
Depth Anything V1とV2の結果を見比べる

概要
単眼深度推定モデルDepth Anything (以降はV1として記載します)とそのアップデート版にあたるDepth Anything V2を簡単に比較してみました。
V1に比べV2は輪郭がはっきりしており、細部も予測できるようになった印象を受けました。
推論の速度はほぼ同等で、GPU使用量と重みのファイルサイズは同じでした。
Depth Anything V2のSサイズモデルはApache-2.0ライセンスですが、Mサイズ(Base)以上は非商用のCC-BY-NC-4.0ライセンスのため要注意です。
Depth Anything V1の方はモデルごとのライセンスの記載はなく、S~Lサイズの各モデルApache-2で利用できるようです。
深度推定(Depth Estimation)について
画像処理における深度推定は、撮影位置/カメラに対する奥行を画素単位で推定するタスクです。
推定された奥行は以下の画像の様に色の変化で可視化します。
可視化のカラーパターンは黒~白や紫~黄、青~赤などよく利用されます。

← 入力画像 可視化された深度 →
深度推定はその方法によってステレオ深度推定や単眼深度推定などの分類があります。
Depth Anythingは単眼深度推定のモデルで、1枚の画像を入力としてその深度を推定します。
Depth Anythingの強みは、「Anything」と名付けられているだけあってZero-Shotで良い感じの推定結果を得ることができる能力です。
V1はApache-2ライセンスなため、その利用しやすさも魅力です。
(注意点)
Depth Anythingの公開されている重みで推定される深度の値は「〇〇メートル」といった実際の距離ではなく、画像内での遠近を示す相対的な値です。
実施内容
Google Colab (Pro)のL4、T4で実行しました。
Depth Anything V1
インストール
まずはGitHubからクローンとライブラリのインストールを行い、必要なフォルダも作成しておきます。
!git clone https://github.com/LiheYoung/Depth-Anything
%cd Depth-Anything
!pip install -r requirements.txt
!mkdir checkpoints作成した checkpoints フォルダに学習済みの重みファイル3種をダウンロードします。
!wget -P checkpoints https://huggingface.co/spaces/LiheYoung/Depth-Anything/resolve/main/checkpoints/depth_anything_vitl14.pth
!wget -P checkpoints https://huggingface.co/spaces/LiheYoung/Depth-Anything/resolve/main/checkpoints/depth_anything_vitb14.pth
!wget -P checkpoints https://huggingface.co/spaces/LiheYoung/Depth-Anything/resolve/main/checkpoints/depth_anything_vits14.pth入力/出力画像の格納先のフォルダも作成します。
!mkdir inputs outputsサンプルコードの実行
inputs フォルダに入力画像をアップロードし、サンプルコードを実行します。
サンプルコードの実効例と指定オプションの概要は以下の通りです。
!python run.py --encoder vitl --img-path inputs --outdir outputs/vitl/gray --pred-only --grayscale--encoder
使用したいモデルのサイズに合わせて指定する。
vitl ⇒ Lサイズ
vitb ⇒ Mサイズ(わかりやすさ優先でMと記載)
vits ⇒ Sサイズ
--img-path
画像のファイルパスや、格納先フォルダのパスを指定する。
--outdir
出力先のフォルダを指定する。(サブフォルダも自動で作成してくれました。)
--pred-only
本オプション未指定時は本稿の上部の画像の様に、元画像と深度の可視化画像が横並びになった1枚の画像として保存されます。本オプションを指定するとシンプルな深度の可視化画像を保存されます。
--grayscale
本オプション未指定時は紫~黄のカラーパターンで深度が可視化され、指定すると黒~白のカラーパターンで可視化されます。
深度推定結果
Lサイズのモデルの結果は以下の様になりました。
入力画像と見比べるために「--pred-only」は未指定で実行しました。
後述のV2とはデフォルトのカラーパターンが異なるため、見比べやすくする目的で「--grayscale」を指定して実行しました。(未指定ではV1は紫~黄、V2は青~赤)





上で使用した画像の場合はMサイズやSサイズでも概ね同様の見た目の推定結果が得られました。
大きいモデルほど良い結果が得られると思います。
(処理時間と必要なメモリ量は増加しますが)
Depth Anything V2
一旦、作業フォルダを元のフォルダに戻ってV2のインストールを行います。
%cd /contentインストール
V2のインストール・準備はV1の時と同様に行います。
!git clone https://github.com/DepthAnything/Depth-Anything-V2
%cd Depth-Anything-V2
!pip install -r requirements.txt
!mkdir checkpoints!wget -P checkpoints https://huggingface.co/depth-anything/Depth-Anything-V2-Large/resolve/main/depth_anything_v2_vitl.pth
!wget -P checkpoints https://huggingface.co/depth-anything/Depth-Anything-V2-Base/resolve/main/depth_anything_v2_vitb.pth
!wget -P checkpoints https://huggingface.co/depth-anything/Depth-Anything-V2-Small/resolve/main/depth_anything_v2_vits.pth!mkdir inputs outputsサンプルコードの実行
こちらもV1と同様で inputs フォルダに画像をアップロードし、サンプルコードを実行します。
実行方法やオプションの指定方法は同じですが、一部のオプションは動作に微妙な違いがありました。
!python run.py --encoder vitl --img-path inputs --outdir outputs/vitl/gray --pred-only --grayscale--pred-only の差異
本オプション未指定時に作成される横並びになった深度の可視化画像に「Raw image」や「Depth Anything」というキャプションが無くなっています。
--grayscale の差異
本オプション未指定時は青~赤のカラーパターンで深度が可視化されるようになりました。
深度推定結果
Lサイズのモデルの結果は以下の様になりました。
こちらもV1の時と同様に「--pred-only」は未指定、「--grayscale」を指定して実行しました。





V1 vs V2
推定結果の比較
2モデル(V1, V2)、3サイズ(L, M, S)での結果を見比べてみます。
「--pred-only」を指定して出力された結果の画像を比較用に結合しました。
以下の各画像は2×3で、以下の並びで推定結果の画像を結合しています。
| V1-L | V1-M | V1-S |
| V2-L | V2-M | V2-S |
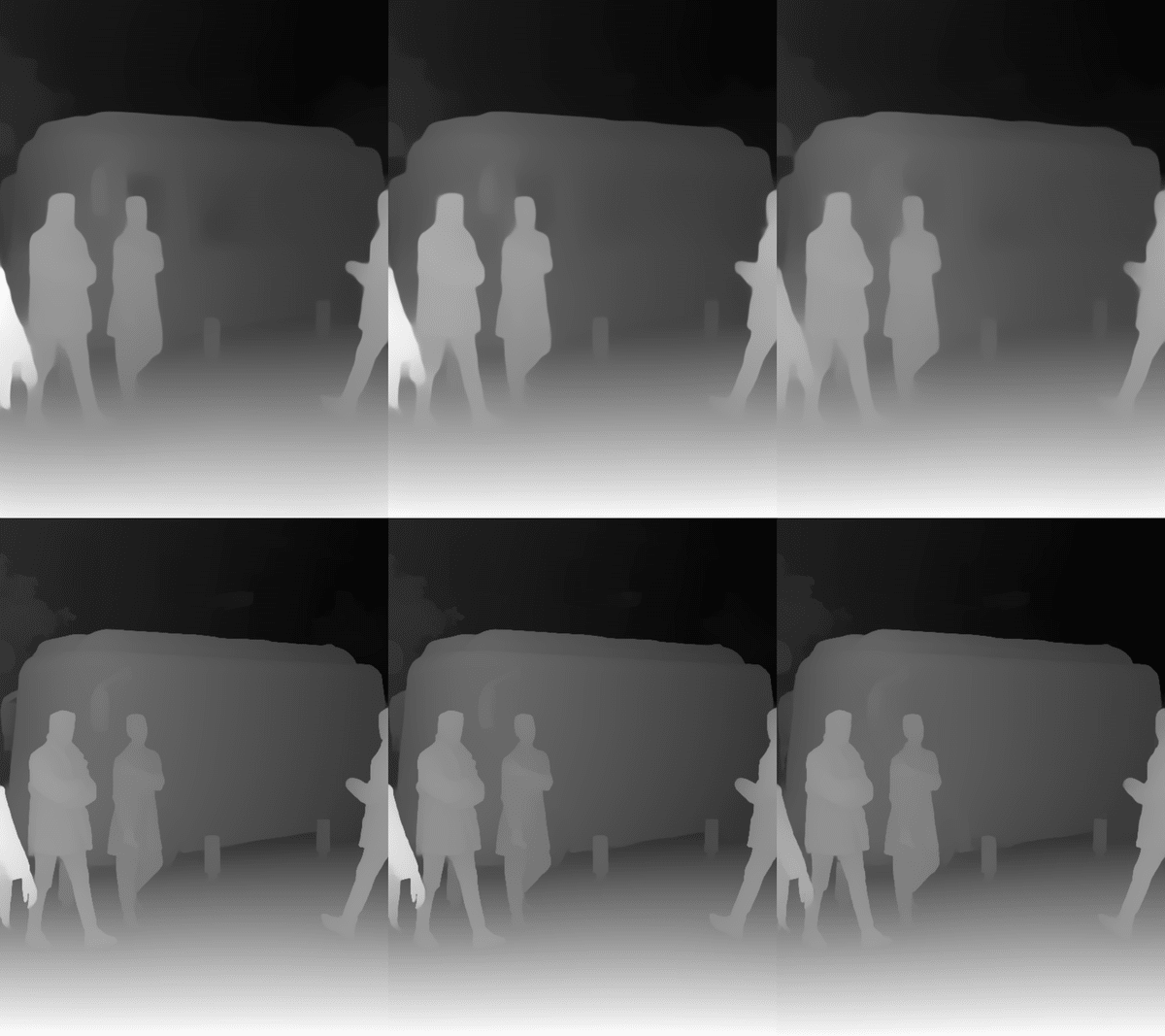




V2の方が全体的に輪郭がくっきりした印象で、2枚目の人のスーツに深度のグラデーションがはっきりと見えるため、V1に比べ分解能が向上した気がします。
また、1枚目のバスや5枚目を見ると、窓ガラスに対する推定特性が変わっているように感じます。V1では車のボディより暗く(奥側として)推定さた車の窓が、V2では車のボディと同等の色味(深度)になっています。
処理速度
L4インスタンスとT4インスタンスでバスの画像を10回推論させたときの平均の処理時間(ミリ秒)は以下の様になりました。
V1とV2で処理時間はほぼ同等でした。
L4
Lサイズ V1: 305 ms V2: 305 ms
Mサイズ V1: 114 ms V2: 115 ms
Sサイズ V1: 55 ms V2: 55 ms
T4
Lサイズ V1: 586 ms V2: 604 ms
Mサイズ V1: 239 ms V2: 221 ms
Sサイズ V1: 107 ms V2: 103 ms
以下は処理時間計測に使用したコードです。
V2で使いやすいコードに改修されたためと思われますが、V1とV2で提供されているコードの推論処理部分の実装が異なっています。
そのため、V1用のコードはサンプルコード run.py を参考にV2の推論用メソッド infer_image 内の処理と同様になるよう実装しました。
V1用
import time
import cv2
import torch
import torch.nn.functional as F
from torchvision.transforms import Compose
from depth_anything.dpt import DepthAnything
from depth_anything.util.transform import Resize, NormalizeImage, PrepareForNet
DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Device: {DEVICE}")
v1_model_configs = {
"vitl": {"encoder": "vitl", "features": 256, "out_channels": [256, 512, 1024, 1024]},
"vitb": {"encoder": "vitb", "features": 128, "out_channels": [96, 192, 384, 768]},
"vits": {"encoder": "vits", "features": 64, "out_channels": [48, 96, 192, 384]}
}
v1_encoder = "vits" # or "vitb", "vits"
print(f"V1 Encoder: {v1_encoder}")
v1_model = DepthAnything(v1_model_configs[v1_encoder])
v1_model.load_state_dict(torch.load(f"checkpoints/depth_anything_{v1_encoder}14.pth"))
v1_model = v1_model.to(DEVICE).eval()
raw_img = cv2.imread("inputs/bus.jpg")
for i in range(10):
torch.cuda.synchronize(); start = time.perf_counter()
image = cv2.cvtColor(raw_img, cv2.COLOR_BGR2RGB) / 255.0
h, w = image.shape[:2]
transform = Compose([
Resize(
width=518,
height=518,
resize_target=False,
keep_aspect_ratio=True,
ensure_multiple_of=14,
resize_method="lower_bound",
image_interpolation_method=cv2.INTER_CUBIC,
),
NormalizeImage(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
PrepareForNet(),
])
image = transform({"image": image})["image"]
image = torch.from_numpy(image).unsqueeze(0).to(DEVICE)
with torch.no_grad():
v1_depth = v1_model(image)
v1_depth = F.interpolate(v1_depth[None], (h, w), mode="bilinear", align_corners=False)[0, 0]
v1_depth.cpu().numpy()
torch.cuda.synchronize(); end = time.perf_counter()
print(f"({str(i+1):0>2}) Inference time: {end - start} sec")V2用
import time
import cv2
import torch
from depth_anything_v2.dpt import DepthAnythingV2
DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Device: {DEVICE}")
v2_model_configs = {
"vits": {"encoder": "vits", "features": 64, "out_channels": [48, 96, 192, 384]},
"vitb": {"encoder": "vitb", "features": 128, "out_channels": [96, 192, 384, 768]},
"vitl": {"encoder": "vitl", "features": 256, "out_channels": [256, 512, 1024, 1024]},
"vitg": {"encoder": "vitg", "features": 384, "out_channels": [1536, 1536, 1536, 1536]}
}
v2_encoder = "vitl" # or "vits", "vitb", "vitg"
print(f"V2 Encoder: {v2_encoder}")
v2_model = DepthAnythingV2(**v2_model_configs[v2_encoder])
v2_model.load_state_dict(torch.load(f"checkpoints/depth_anything_v2_{v2_encoder}.pth", map_location="cpu"))
v2_model = v2_model.to(DEVICE).eval()
raw_img = cv2.imread("inputs/bus.jpg")
for i in range(10):
torch.cuda.synchronize(); start = time.perf_counter()
v2_depth = v2_model.infer_image(raw_img) # HxW raw depth map in numpy
torch.cuda.synchronize(); end = time.perf_counter()
print(f"({str(i+1):0>2}) Inference time: {end - start} sec")GPUメモリ使用量と重みファイルサイズ
GPUメモリの使用量と重みファイル(.pth)のファイルサイズを nvidia-smi コマンドと ls -lh コマンドで調べました。
V1とV2で結果は同じで、以下の様になりました。
Lサイズ GPU使用量: 2.31GB ファイルサイズ: 1.3GB
Mサイズ GPU使用量: 1.21GB ファイルサイズ: 372MB
Sサイズ GPU使用量: 0.63GB ファイルサイズ: 95MB
まとめ
Depth AnythingのV1とV2を簡単に比較しました。
推論速度はほぼ同じですが、精度的にはやはりV2が良さそうです。
GPU使用量、重みのファイルサイズは同じでした。
業務利用の場合はライセンス的にV1になりそうです。(SサイズならV2)
今回使用した画像の取得元
他の方の記事
深度推定モデルがもっと注目/応用されることを願って他の方の記事へのリンクも載せておきます。
余談
深度推定の活用例
過去にステレオ深度推定に触れたことがあり、個人的に単眼深度推定も非常に関心のある分野です。
ただ、物体検出などの画像処理タスクと比較すると、実際のアプリケーションやサービスでの活用を考えるとニッチな用途になってしまう印象はあります。
自動運転のように正確な距離情報が欲しい場合にはLiDAR等のセンサー情報には負けてしまうかと思います。
そういったセンサーが使用できない環境で、正確さをある程度目をつぶれるのであれば深度推定も選択肢に入ってくると思います。
Depth Anythingよりも前のモデルではありますが、以下のような記事があります。
noteだと、画像生成AIでの活用例を見かけることが多いかもしれません。
以下の記事の様に画像内の位置関係を残したまま別の画像を生成する際に利用されています。
ステレオ深度推定
2台のカメラで同時に撮影した画像(1枚ずつの計2枚)を画素単位で比較し、対応する画素の位置ずれ(視差)から深度を得ることができます。
(近いものほど視差は大きく、遠いほど視差は小さい)
カメラパラメータ(カメラの焦点距離など)を事前に調べておくことで、視差をもとに実際の距離を推定することもできます。
OpenCVにも組み込まれており、BMやSGBMといったアルゴリズムを利用できます。試しているブログ記事なども多数見つけられるかと思います。
ただ、これらの手法は片側のカメラにしか映らない領域(物体の輪郭付近の画素など)は深度を推定できません。可視化画像の見栄えの観点では単眼震度推定の方が綺麗です。
単眼震度推定を組み合わせて補完したりはできそうですね。
この記事が気に入ったらサポートをしてみませんか?