
Stable Diffusion(Diffusers)による画像生成の効率化と、基本的な使い方まとめ

長いですが、ほぼ無料で読めるようにしています。ぜひ、画像生成の楽しみを味わってください😆
はじめに
今、Stable Diffusion や Midjourney などのAIによる画像生成は、画面を手でポチポチ操作する手順(WebUI)が主流になっています。
数枚程度なら気になりませんが、いろんな設定パターンで、大量に画像を生成したいときは、やや不便だなーと感じることもあります。また、WebUIでたくさん生成するには、基本的に何かしらの課金が必要です。
そこで、自分が実践している効率的な画像生成方法を公開します。そして、その過程で学んだ、無料でできる基本的な画像生成方法も載せます。
ネット上では新旧の情報があちこちに散乱しており、新しく始める人には非常にわかりにくいので、初めての方が今すぐにでも画像生成できる情報をまとめました。
調べるのに割と苦労したので、終盤は有料にさせてもらってますが、無料部分でも結構なボリュームだと思います。
※GoogleColab上で、Stable Diffusion 用のライブラリであるDiffusersを使った手法です。Colabの無料枠ではWebUIが使えなくなりましたが、Diffusersなら無料枠でもそれなりに使えます。
注意事項
AIを使用することで、誰でも様々な種類の画像を生成できます。このnoteの情報を用いて発生する、いかなる問題についても責任は負いかねます。ご認識の上でご活用ください。
効率化の全体イメージ
Googleの無料サービスを組み合わせました。
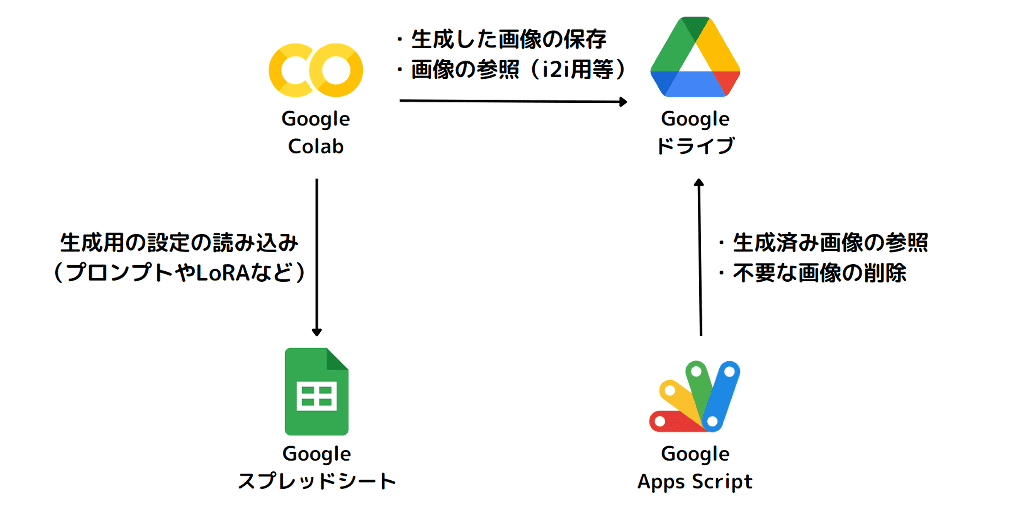
画像の生成処理:Google Colab
・画像生成処理の実行
設定管理:Googleスプレッドシート
・画像生成に必要な設定内容の管理(プロンプト、Controlnet、LoRAなど)
画像管理:Googleドライブ
・生成した画像の管理
・入力画像の管理(img2img、インペイント、Controlnetなど)
画像の表示やダウンロード:Google Apps Script
・生成した画像の表示やダウンロード
・生成した画像の削除
まずは、上の4つについて簡単に説明します。
Google Colabで画像生成
Stable Diffusionの画像生成では「AUTOMATIC1111」の画面(WebUI)を使う方法が有名ですが、今回はプログラムで自由に扱いたいので「Diffusers」というライブラリを使います。
※AUTOMATIC1111の画面ではなくAPIを用いた手法もありますが、今回は非採用としました。
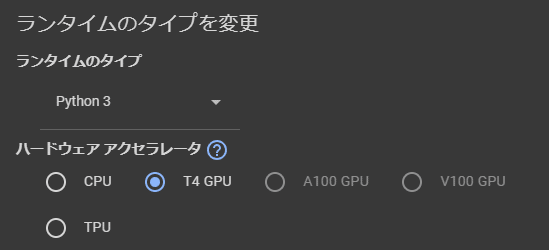
最初に、最もシンプルな使い方でDiffusersを使ってみます。Google Colabでノートブックを新規作成し、メニューバーからランタイム設定をGPUに変更します。
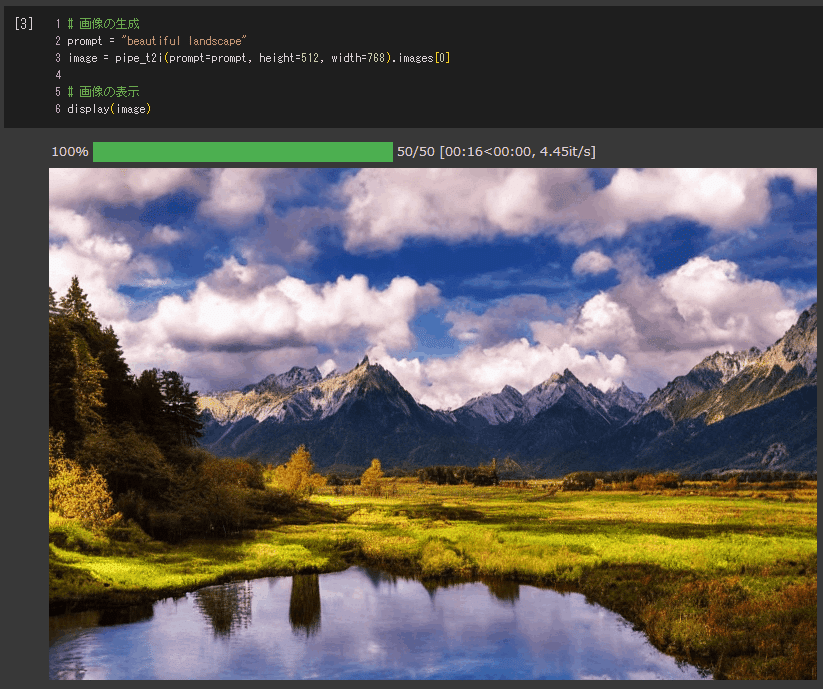
コードセルを追加して、以下を実行します。
# 後半で必要になるものも含めちゃってます
!pip install diffusers transformers accelerate omegaconf pytorch_lightningimport torch
from diffusers import AutoPipelineForText2Image
# モデルのパスを指定
model_path = "runwayml/stable-diffusion-v1-5"
# Pipelineの作成
pipe_t2i = AutoPipelineForText2Image.from_pretrained(
model_path, torch_dtype=torch.float16
).to("cuda")# 画像の生成
prompt = "beautiful landscape"
image = pipe_t2i(prompt=prompt, height=512, width=768).images[0]
# 画像の表示
display(image)数秒でこのように画像が生成されます。
Googleドライブとの連携
Colab上で下記コードを実行すると、認証ダイアログが表示されます。
from google.colab import drive
drive.mount('/content/drive')承認すればGoogleドライブと連携され、ドライブ上に画像を保存できます。
画像を保存するときは、saveするときのパスを「/content/drive/MyDrive/…」とします。
import os
# Googleドライブ直下に、「images」フォルダを作成
os.makedirs("/content/drive/MyDrive/images", exist_ok=True)
# 「images」フォルダに保存
image.save("/content/drive/MyDrive/images/new_image.png")
もちろんGoogleドライブ上の画像をColab側で読み込むこともできます。
from PIL import Image
# 画像読み込み
load_image = Image.open("/content/drive/MyDrive/images/new_image.png")
display(load_image)Googleスプレッドシートとの連携
下記コードで認証ダイアログが表示されるので、承認します。
from google.colab import auth
import gspread
from google.auth import default
auth.authenticate_user()
creds, _ = default()
gc = gspread.authorize(creds)対象のGoogleスプレッドシートを開いて、URL(下図の枠線部分)からコピーします。
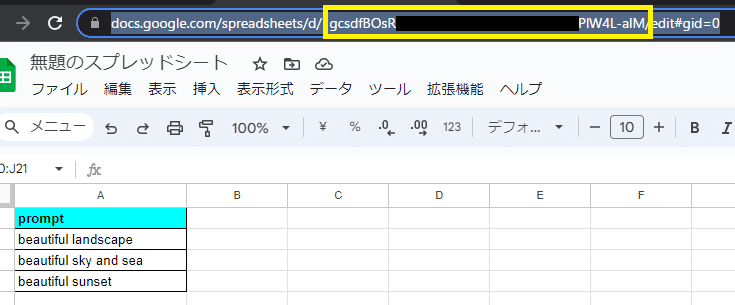
Colabに戻り、コピーしたIDを貼り付けて、読み込みたいシートを指定します。1シート目を読み込むならこんな感じ。
ss_id = "XXXXXXX" #シートのID(シートのURLからコピー)
sheet_no = 1 #シートの番号(何シート目か)
workbook = gc.open_by_key(ss_id)
worksheet = workbook.get_worksheet(sheet_no-1)シートの中身を読み込みます。
import pandas as pd
# シート全体を読み込み
rows = worksheet.get_all_values()
# 2行目以降をレコード、1行目を列名に指定
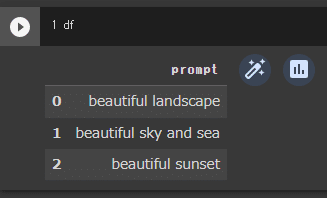
df = pd.DataFrame.from_records(rows[1:], columns=rows[0])例えば下のようなシートを読み込んだとすると、「prompt」という列に、2行目以降の各プロンプト内容(beautifu~)が設定されたテーブルデータが取得されます。

「df」と書いたセルを実行すると、テーブルの中身が確認できます。上のシート内容と同じです。
そして下記コードを実行すると、各プロンプトを使って連続で画像が生成され、全ての画像がGoogleドライブに保存されます。
# シートの行数分、処理を繰り返す
for index, row in df.iterrows():
# row["prompt"]には、シートの各行の「prompt」列の値が入っている
image = pipe_t2i(prompt=row["prompt"], height=512, width=768).images[0]
image.save(f"/content/drive/MyDrive/images/{index}.png")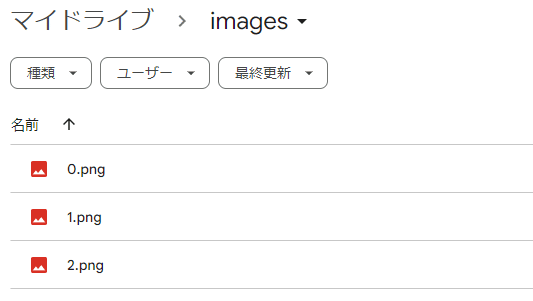
この方法で、プロンプトだけでなく、img2img・Controlnet・LoRAなどの強さだったり、各種画像パスや、生成枚数など、いろいろな情報がシート上で管理できます。
つまり、Colab上のコードを変更しなくても、シートの各行の値を変えるだけで、それぞれの設定で画像を一括生成できるので、とても効率が上がります。「ChatGPTに大量に出力させたプロンプトを、シートに貼り付けて一括生成」なんてこともできますね。
Google Apps Scriptとの連携
Googleドライブの画面は、たくさんの画像を連続で確認しようとすると、モッサリして使いにくさを感じました。
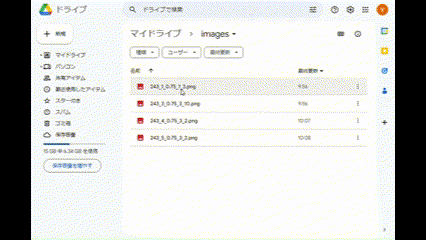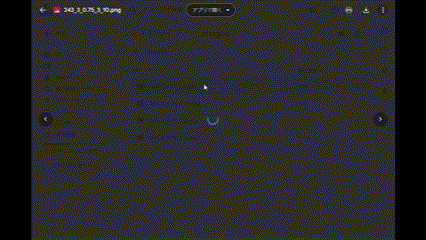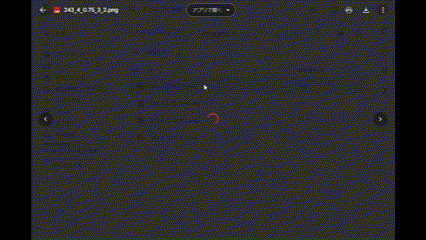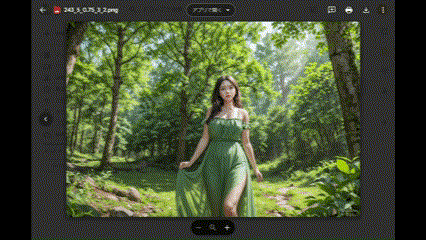
なので、Google Apps Script で、このような簡易Webページを作ってみました。(と言いつつ、コード書いたのはChatGPTですが…)
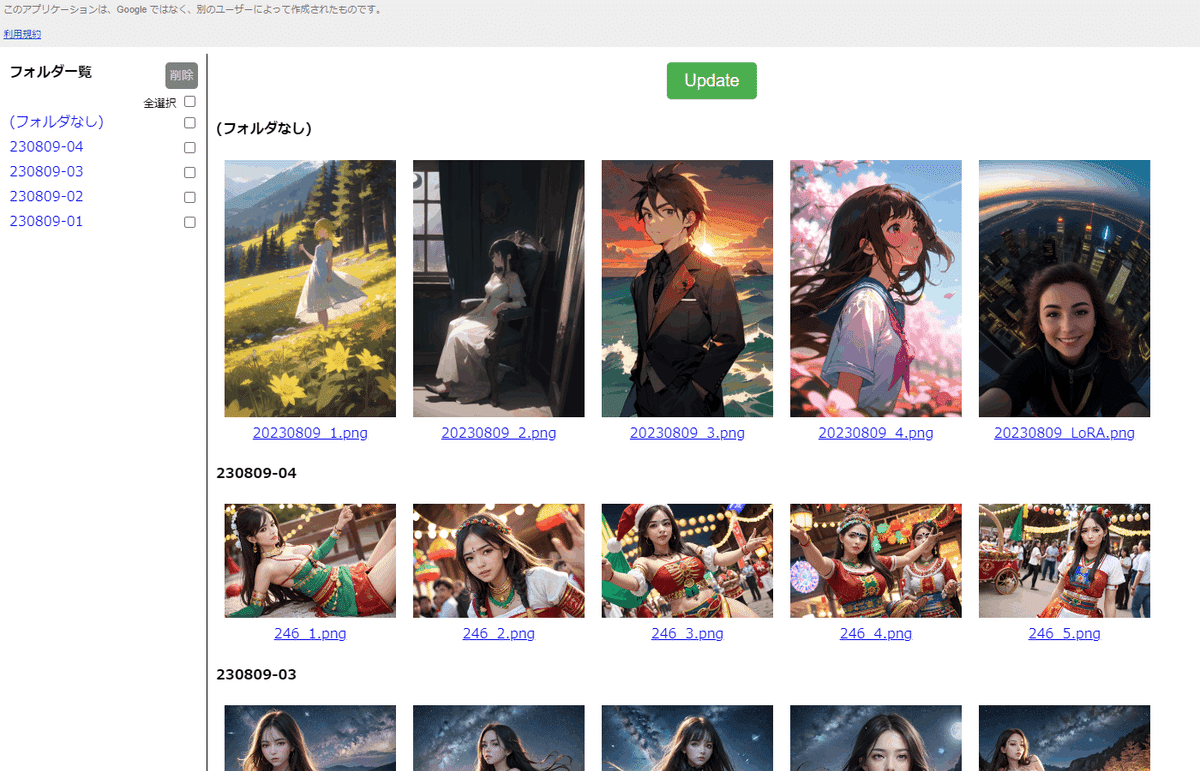

「画像の切り替え」と「ダウンロード」を、矢印キーとEnterキーだけで効率よく行える画面を目指しました。画像の削除もできます。(フォルダ単位)
せっかく作ったので、アプリに必要な全コード(HTMLとgsファイルの添付)含め、利用手順を記事の後半に載せています。
Diffusersの機能の使い方
ここから先は、より素敵な画像を作るために知っておくべきDiffusersの各機能の基本的な使い方です。
img2img(既存画像ベースの生成)
既存の画像をベースとして生成したい場合は、img2img(i2i)用のPipelineを準備します。(参考:AutoPipeline)
from diffusers import AutoPipelineForImage2Image
# 作成済みの「pipe_t2i」を利用して作成すれば追加メモリ不要
pipe_i2i = AutoPipelineForImage2Image.from_pipe(pipe_t2i)最初に作成した風景画像に、動物たちを追加してみます。プロンプトは 「beautiful landscape with animals」で。
画像生成時は、既存の画像(image)と変化の強さ(strength)のパラメータを指定します。画像サイズは指定しません。
# 「new_image.png」を初期画像として読み込み
init_image = Image.open("/content/drive/MyDrive/images/new_image.png")
# img2img実行
prompt = "beautiful landscape with animals"
strength= 0.8
image = pipe_i2i(prompt=prompt, image=init_image, strength=strength).images[0]
image.save("/content/drive/MyDrive/images/img2img.png")
display(image)
インペイント(画像の一部修正)
画像の一部のみを変更したい場合は、インペイント用のPipelineを準備。
from diffusers import AutoPipelineForInpainting
pipe_inpaint = AutoPipelineForInpainting.from_pipe(pipe_t2i)次に、修正したい画像と同サイズの、白黒の画像を準備します。例えば上半分を修正したい場合は、このような画像を。

先ほどの動物たちの画像にインペイントしてみます。
動物の画像をimageパラメータに、マスキング画像をmask_imageパラメータに指定し、プロンプト「many birds flying」で実行。
# 初期画像とマスキング画像を読み込み
init_image = Image.open("/content/drive/MyDrive/images/img2img.png")
mask_image = Image.open("/content/drive/MyDrive/images/mask.png")
# インペイント実行
prompt = "many birds flying"
strength = 0.8
image = pipe_inpaint(
prompt=prompt,
image=init_image,
mask_image=mask_image,
strength=strength,
height=512,
width=768,
).images[0]
display(image)
生成モデルの変更(safetensors形式)
冒頭の生成コード例では、下記のようにモデルを指定していました。特定の形式のモデルは、このようにパスを指定するだけで使えます。
# モデルのパスを指定
model_path = "runwayml/stable-diffusion-v1-5"
# Pipelineの作成
pipe_t2i = AutoPipelineForText2Image.from_pretrained(
model_path, torch_dtype=torch.float16
).to("cuda")でも、もっとイラストとか、綺麗なお姉さんとかに特化したモデルを使いたい人も多いと思います。そこで、よく見かける safetensorsファイル単体のモデルを使う手順をご紹介します。
例として、イラスト系で有名な「Counterfeit-V3.0」のモデルを使います。まずは変換したいsafetensorsファイルのURLを確認します。
確認したURLから、Colab上にダウンロードします。
※事前ダウンロードではなく直接指定の方法もありますが、この方が汎用的かなと。時間がかかるので、Googleドライブ上に保存するのもありです。
# 確認したURLからsafetensorsファイルをダウンロード
!wget https://huggingface.co/gsdf/Counterfeit-V3.0/resolve/main/Counterfeit-V3.0_fp16.safetensorsダウンロードしたファイルを使ってPipelineを作成。
from diffusers import StableDiffusionPipeline
import torch
# ダウンロードしたファイル名を指定して、Pipeline作成
pipe_t2i = StableDiffusionPipeline.from_single_file(
"Counterfeit-V3.0_fp16.safetensors", torch_dtype=torch.float16
).to("cuda")画像生成時のコードは今まで通り。
# Counterfeit-V3.0の公開ページを参考にしたプロンプト
prompt = "masterpiece, best quality, 1girl, solo, flower, long hair, outdoors, letterboxed, school uniform, day, sky, looking up, short sleeves, parted lips, shirt, cloud, black hair, sunlight, white shirt, serafuku, upper body, from side, pink flower, blurry, brown hair, blue sky, depth of field"
image = pipe_t2i(prompt=prompt, height=512, width=768).images[0]
display(image)イラストが生成できました。

こちらは「Blazing Drive」というモデルの例。カッコよいです。

フォトリアルなモデルも使えます。こちらは「BracingEvoMix」を使用させていただいた例。AI感がなくてスゴい。

ネガティブプロンプト、EasyNegative
「描画したくないもの」をnegative_promptパラメータに指定すると、描かれにくくなります。例えば「worst quality」のような品質が悪そうな言葉をたくさん入れることで、品質が上がります。
prompt = "XXX"
negative_prompt = "worst quality, low quality, nsfw" # ←ここで設定
image = pipe_t2i(
prompt=prompt, negative_prompt=negative_prompt, height=512, width=768
).images[0]汎用的なネガティブプロンプトを設定するための「EasyNegative」という便利なものもあります。(参考:Diffusersで「EasyNegative」を使ってみる)
# EasyNegativeのファイルをダウンロード
!wget https://huggingface.co/datasets/gsdf/EasyNegative/resolve/main/EasyNegative.safetensors# Pipelineに設定
pipe_t2i.load_textual_inversion(
".", weight_name="EasyNegative.safetensors", token="EasyNegative"
)あとは negative_promptパラメータに「EasyNegative」と入れるだけ。
prompt = "XXX"
negative_prompt = "EasyNegative"
image = pipe_t2i(
prompt=prompt, negative_prompt=negative_prompt, height=768, width=512
).images[0]
display(image)この有無で、結果が大きく変わります。

Scheduler(Sampler)の変更
スケジューラーによって、出力結果や生成時間が変わります。WebUIではSamplerという項目にあたるみたいです。(参考:diffusersでschedulerを変える方法)
Pipelineのschedulerパラメータを指定します。例えば「DPMSolverMultistepScheduler」を使用する場合はこのように。
from diffusers import DPMSolverMultistepScheduler
# 作成済みのPipelineにスケジューラーを設定
pipe_t2i.scheduler = DPMSolverMultistepScheduler.from_config(pipe_t2i.scheduler.config)指定できるスケジューラーはたくさんあるので(SCHEDULERS)、気になる方はいろいろ試してみてください。「このスケジューラーはクオリティが高い!」といったものではなく、好み次第かなと感じます。

プロンプトの指定が細かいと、あまり変わらないかも?
VAEの変更
VAEを変えると、雰囲気がガラッと変わります。ここでは、Counterfeit-V2.5のVAEを使ってみます。
# VAEファイルのダウンロード
!wget https://huggingface.co/gsdf/Counterfeit-V2.5/resolve/main/Counterfeit-V2.5.vae.ptPipeline作成時に、vaeパラメータを指定します。(参考:AutoencoderKL)
from diffusers import AutoencoderKL
# ダウンロードしたVAEファイルを指定
vae = AutoencoderKL.from_single_file("Counterfeit-V2.5.vae.pt")
# VAEを指定してPipeline作成
pipe_t2i = StableDiffusionPipeline.from_single_file(
"Counterfeit-V3.0_fp16.safetensors", torch_dtype=torch.float16, vae=vae
).to("cuda")
VAEもいろいろあるので、こだわる人は試してみてください。vae-ft-mse-840000-ema-pruned とかは、よく使われているかも。また、最初からVAE込みのモデルもあります。
ガイダンススケール、ステップ数
画像生成時に設定できるパラメータです。自分はguidance_scaleは7.5〜8.0、num_inference_stepsは20〜40ぐらいにすることが多いですが、明確なものはありません。(あまり気にしなくていいかも)
# 画像生成処理
image = pipe_t2i(
prompt=prompt,
height=512,
width=768,
guidance_scale=7.5,
num_inference_steps=20
).images[0]num_inference_stepsは、特に生成時間に影響します。細かく検証されている方もいるので、気になった方は調べてみてください。
Controlnet
画像生成を、よりコントロール可能にする技術です。線画や人間のポーズの指定、書き込み量アップなど、様々なことができます。
ここでは、既存の画像に対し、書き込み量を増やしつつ解像度を上げる例(Tile)をご紹介します。
まずはControlnetを指定したPipelineを定義します。
from diffusers import StableDiffusionControlNetPipeline, AutoPipelineForImage2Image
from diffusers import ControlNetModel
import torch
# 使用するControlnetを準備
controlnet = ControlNetModel.from_pretrained(
"lllyasviel/control_v11f1e_sd15_tile", torch_dtype=torch.float16
)
# Pipeline作成
pipe_t2i = StableDiffusionControlNetPipeline.from_single_file(
"Counterfeit-V3.0_fp16.safetensors",
torch_dtype=torch.float16,
controlnet=controlnet,
).to("cuda")
# img2img用Pipeline作成
pipe_i2i = AutoPipelineForImage2Image.from_pipe(pipe_t2i)生成前の準備として、既存の画像を、生成したいサイズに拡大します。ここでは最大辺を1024pxに。(参考:control_v11f1e_sd15_tile)
from PIL import Image
def resize_for_condition_image(input_image: Image, resolution: int):
input_image = input_image.convert("RGB")
W, H = input_image.size
k = float(resolution) / min(H, W)
H *= k
W *= k
H = int(round(H / 64.0)) * 64
W = int(round(W / 64.0)) * 64
img = input_image.resize((W, H), resample=Image.LANCZOS)
return img
init_image = Image.open("/content/drive/MyDrive/images/sample.png")
init_image = resize_for_condition_image(init_image, 1024)拡大した画像(imageとcontrol_image)と、Controlnetを適用する強さ(controlnet_conditioning_scale)をパラメータに指定して、img2imgで生成します。
prompt = "XXX"
negative_prompt = "XXX"
strength = 1.0 # img2imgの変化の強さ
scale = 1.0 # Controlnetの強さ
image = pipe_i2i(
prompt=prompt,
negative_prompt=negative_prompt,
strength=strength,
image=init_image,
control_image=init_image,
controlnet_conditioning_scale=scale,
).images[0]
個人的には、落書きを清書してくれるScribbleがお気に入りです。特にイラストを少しでも経験ある方は、使ってみると楽しいと思います。

他にも様々な機能がありますし、複数の機能を組み合わせることもできます。Diffusersで使えるControlnet機能は、使い方含めて下のページで紹介されています。
プロンプトの重み付け
WebUIだと、"XXX:1.4" のように重み付けをするのが一般的だと思いますが、DiffusersではCompelという機能で実現します。(参考:Weighting Prompts)
プロンプトに「+」や「-」を付けることで、重みを調整することができます。また、括弧でくくれば、カッコ内全体に適用されます。
!pip install Compel試しに「cat」に「++」を付けてみます。
from compel import Compel
# 強調したいワードに「+」を付ける
prompt = "beautiful landscape, forest, mountain, sunny, yellow flower, woman in white dress with cat++"
negative_prompt = "EasyNegative, nsfw"
# promptを変換
compel_proc = Compel(tokenizer=pipe_t2i.tokenizer, text_encoder=pipe_t2i.text_encoder)
prompt_embeds = compel_proc(prompt)
negative_prompt_embeds = compel_proc(negative_prompt)
# 画像生成時に、変換後のprompt_embedsを渡す
image = pipe_t2i(
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
height=768,
width=512,
).images[0]
display(image)
右には猫要素がプラスされている
同じ画像の出力(シード値の固定)
通常、シードと呼ばれるパラメータがランダムで設定され、生成される画像は毎回変わります。
画像生成時に下記のようにgeneratorパラメータでシードを固定すれば、全く同じ画像が出力できます。
# シードを「123」に固定(他の数値でもOK)
generator = torch.Generator("cuda").manual_seed(123)
# generatorを指定して生成
image = pipe_t2i(
prompt=prompt,
negative_prompt=negative_prompt,
height=768,
width=512,
generator=generator,
).images[0]メモリの節約など
(品質とは直接関係ありませんが)メモリをたくさん使うことでGoogleColabが落ちることもあるので、メモリの節約の例についても少し触れます。
例えば、Pipeline作成後に、下記コードを実行しておくなどで節約ができます。処理速度とのトレードオフにはなるようですが。他にもいろいろあるようです(参考:Memory and Speed)
pipe_t2i.enable_model_cpu_offload()また、画像生成時のコードを下記のようにすると、推論処理が早くなるようです。(浮動小数点データ型の変換によるもの。ほぼ精度は変わらないぽい)
from torch import autocast
with autocast("cuda"):
image = pipe_t2i(prompt=prompt, height=512, width=768).images[0]あと、大量に画像生成する際に、Colab上で生成する度に(display関数などで)画像を表示するのは避けたほうがよいかもしれません。画像が多くなると、次第にColabの反応が遅くなっていくように感じました。
Safety Checkerの解除
画像生成時に、健全な画像が不適切(NSFW)と判定されて真っ黒になることがありますが、Pipeline作成後に下記を実行することチェッカーを解除できます。
pipe_t2i.safety_checker = Noneここまでの機能の公開Colabファイル
ここまでに記載した基本機能を実行できる公開Colabファイルです。たぶん動くはず。
プロンプトの参考先
プロンプトは、自分で考えたり、ChatGPTにたくさん出してもらうのも楽しいですが、最近はよく、BDさんの記事を参考にさせていただいています。(本記事でも、ヘッダーに含まれている画像などで)
ちなみに上記はPixivのページもありますが、今はnoteに移行されています。イラスト系のいろんなモデルを作られています。
LoRA(ウェイト設定、解除)
LoRAは、元々は言語モデル向けの、特定のタスクに適応させる技術です。画像生成では、特定の顔・服装・ポーズ・背景などを生成したいときによく使われます。
例えば「LowRA」というLoRAを使うと(ややこしい)、暗めのドラマチックな画像が簡単に生成できます。

情報整理と記事の作成にとても時間がかかったので、ここから先だけ有料にさせてください…!🙇♂
主に下記3点を紹介しています。
・LoRAのウェイト設定・解除方法
・Googleドライブ画像管理アプリの利用手順
・顔だけを綺麗に違和感なく自動修正する方法
個人的には価値ある内容をまとめたつもりですが、自分で調べたり、ChatGPTに相談しながらコードを書ける人向けの説明です。
また、自分が採用している方法の公開であり、正確性は保証していません。もっと良い方法があるかもしれませんし、ライブラリのバージョンアップや、Googleサービスの仕様変更などにより記載内容が使えなくなっている可能性もあります。
あと、一応定型文として書いておきますと、本記事の内容によって生じた損害等の一切の責任を負いかねます。文章や画像等の無断転載は禁止です。
上記をご理解いただいた、心に余裕のある方だけご購入ください。
ここから先は
¥ 500
この記事が気に入ったらチップで応援してみませんか?