
rtweet 0.7→1.0バージョンアップで困ったこととその解決法のメモ【R】

◆rtweetがバージョンアップしました
Rを使ってtwitterを収集するパッケージrtweetが0.7→1.0にバージョンアップされ、動作や取得できるデータが変わっています。
◆変更点と困ったポイント
認証周りが便利になったりしているのですが、使うにあたって以下のような困った点がありました。
・ハッシュタグ使用頻度をグラフにできない。
・csvやxlsxなどのエクセル形式で保存できない。
詳しい人にとっては全く大したことではないかもですが…
ちょっと迷いましたので私なりの解決方法をメモします。
パッケージの読み込み
rm(list = ls())
gc()
gc()
if (!require("pacman")) install.packages("pacman")
pacman::p_load(
tidyverse,
data.table,
rtweet,
lubridate,
openxlsx
)こちらはいつも通り。
認証
# auth your twitter account
if (!auth_has_default()) {
auth_setup_default()
}auth_setup_default()でブラウザが開き、ログインしているtwitterアカウントを使って認証できるようになりました。
これによってAPI keyを取得しなくても使いやすくなりました。
ただし、変わらず大量のデータ収集の際にはAPI key取得が推奨されています。
# or enter your app baerer token
auth <- rtweet_app()API keyを持っている場合にはrtweet_app()でbaererトークンを入力することで認証できます。
この場合、ツイートやいいね、ブロックなどのアクションはできません。
ただしレート制限がデフォルトよりも有利らしく、データを取得するだけならこっちの方が良いです。
その他認証方法や詳細は以下のページやTwitter開発者プラットフォームなどで。
データ取得
データを取得していきます。
取得方法はver_0.7と変わりません。
# set word
q <- "#レシピ"
# set number
n <- 1000
# get tweets data
df <- search_tweets(
q = q,
n = n,
retryonratelimit = TRUE,
include_rts = FALSE,
# token = auth, # rtweet_app()で認証したときのみ必要
)しかし、取得できるデータにver_0.7とは多くの違いがあります。
変更点1:ユーザーデータが含まれない
取得されたデータを見てみると43のカラムがあります。
ver_0.7では90のカラムがあったため、47種の情報がどこかに行ってしまっています。
例えば、以前はscreen_name等で表示されていたツイートしたユーザーの情報がなくなっています。
これを取得するには、dfに対してusers_data()をしてやればOKです。
df_user <- users_data(df) 変更点2:ツイートURLの情報が含まれない
かつてツイートURLが含まれていたstatus_urlカラムは取得データから消滅しました。
このためツイートURLを直接取得できません。
ツイートへのリンクURLが欲しい場合にはscreen_nameとツイートidから自分で生成しなければなりません。
変更点3:入れ子構造のリストが大量にある
これが一番難しい。
取得されたツイートデータやユーザーデータを見てみると以下のような入れ子構造のリストが大量にあります。
これはrtweet 1.0で使用するようになったAPI key v1.1の仕様によるものだそうです。

リストの中にリストを含むセルがあったり、データフレームが含まれていたり…。
特に大きいのはハッシュタグ(hashtags)と、添付ファイルURLが「リストの中のリスト」に格納されていることです。
このためハッシュタグの使用頻度棒グラフを作ったりメディアURLの一覧を取得して一斉DLをする際などに、unnest()で一発でリストを分解できなくなりました。
変更点4:取得したツイートデータがwriteできない。
変更点3で入れ子構造が複雑になったことでrtweetパッケージのtwitterデータ保存関数write_as_csv()や、write.csv可能にする関数flatten()が動作しなくなりました。
write_as_csv()は将来消滅の方向であり、自力でflattenしてwrite.csv()しろ、またはsaveRDSでRDS形式で保存しろ、と公式発表されています。
ついでにスクリーンショットを撮るtweet_shot()も消滅の方向。
つまり、共有するためなどでどうしてもcsvファイルにしたい場合、必要なデータをリストから取り出し、保存可能なデータフレームにしてやる必要があります。
◆解決策
・ハッシュタグ使用頻度をグラフにしたい。
・エクセル形式で保存したい。
という場合に、変更点による問題を解決するため以下のようなことをやってみました。
① ツイートデータとユーザーデータとbind
② ツイートURL(status_url)を生成する。
③ 入れ子リストから必要な情報を新たなカラムに移してwrite.csvできる形式に変更
④ ③を保存
ユーザーデータを取得し必要なものだけ残す
df_user <- users_data(df) %>%
select(id_str, name, screen_name, name, description, followers_count, friends_count, listed_count, created_at, verified, statuses_count) %>%
data.table::setnames(c("user_id", "user_name", "screen_name", "description", "followers_count", "friends_count", "listed_count", "account_created_at", "verified", "statuses_count"))ユーザーデータをsearch_tweets()で得られたdfからusers_(df)して必要なものだけselectして残します。
この時、ツイートデータのid_str(以前のstatus_id)とユーザーデータのid_strのカラム名が被るため、user_idに変えています。
データの順番はツイートデータと同じになるため、arrange()などで順番を変えてしまうと後でbindできないことに注意です。
入れ子リストからハッシュタグとメディアURLを別カラムに
df_i <- df %>%
rowwise() %>%
mutate(
media_url = list(entities[["media"]][["media_url_https"]]),
hashtags = list(entities[["hashtags"]][["text"]]),
) %>%
ungroup() %>%
select(c(1, 3, 4, 9, 11, 13, 14, 19:23, 44:45))ツイートデータからrowwise→mutateで、入れ子リストから必要なデータを別カラムにしてやります。
その他データが必要な場合にはリスト内を見て同じように適宜指定してあげてください。
この場合はentitiesカラムからmedia_urlとhashtagsを別カラムにしています。
その後、必要なカラムだけをselectして残します。
ツイートデータとユーザーデータをbindしstatus_urlを作る
上で整形したツイートデータとユーザーをbindしてstatus_urlを作ります。
tweet_df <- bind_cols(df_i, df_user) %>%
rowwise() %>%
mutate(status_id = paste0("https://twitter.com/", screen_name, "/status/", id_str, collapse = "")) %>%
ungroup()xlsxで保存してみる
openxlsxパッケージで.xlsxで保存してみます。
tweet_df %>%
mutate(
hashtags = as.character(hashtags),
media_url = as.character(media_url)
) %>%
write.xlsx(paste(Sys.Date(), "_", q, "_tweet_df.xlsx", sep = ""))リストを含むカラムはwrite.xlsxやwrite.csvできないので、無理やりas.character()で文字列にしています。
複数のhashtagsやmedia_urlを含む場合、c("A", "B")という文字列で保存されます。
このため保存ファイルを読み込んで使用する際はstringiパッケージなどで下のような正規表現文字列処理をして元のリストに戻してやる必要があります。
read_df %>%
mutate(hashtags = stri_replace_all(.$hashtags, regex = '^c\\(|"|\\)$| ', replacement = '') %>%
stri_split(regex = ","),
media_url = stri_replace_all(.$media_url, regex = '^c\\(|"|\\)$| ', replacement = '') %>%
stri_split(regex = ",")
)◆例
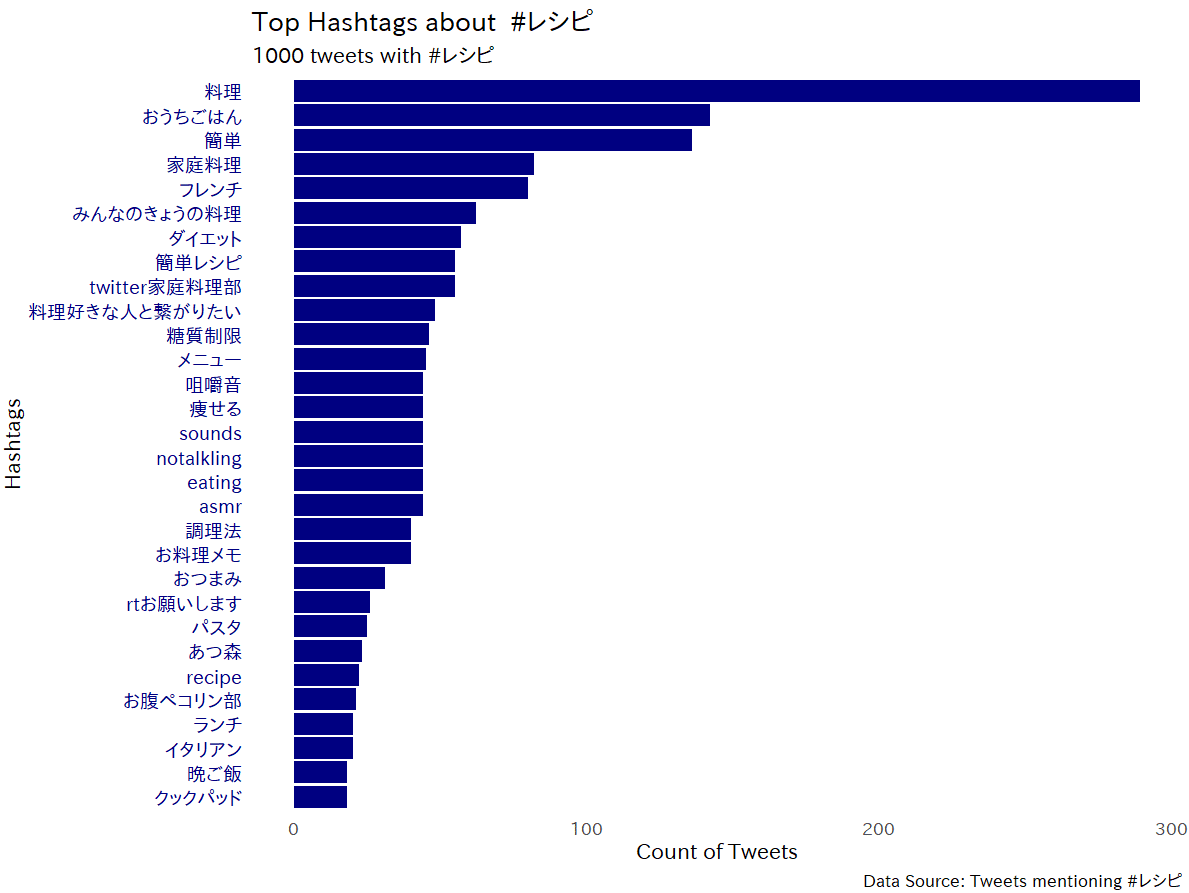
ハッシュタグの出現頻度をグラフ化してみる
上のような処理をすればver_0.7のようにhashtagsをunnest()してグラフ化できます。
# bar
# Takaoフォント
windowsFonts("TPG" = windowsFont("Takao Pゴシック")) # https://launchpad.net/takao-fonts
tweet_df %>%
unnest(hashtags) %>%
count(hashtags = tolower(hashtags)) %>%
filter(hashtags != str_replace_all(q, pattern = "#", replacement = "")) %>%
arrange(desc(n)) %>%
mutate(hashtags = fct_reorder(hashtags, -n, .desc = TRUE)) %>%
drop_na() %>%
slice(1:30) %>%
ggplot() +
geom_bar(aes(hashtags, n), stat = "identity", fill = "#000080") +
coord_flip() +
ggplot2::theme_minimal(base_size = 16, base_family = "TPG") +
theme(
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
axis.text.y = element_text(
size = 14,
color = "#000080"
)
) +
labs(
title = paste0("Top Hashtags about ", q),
subtitle = paste0(nrow(df_i), " tweets with ", q),
caption = paste0("Data Source: Tweets mentioning ", q),
y = "Count of Tweets",
x = "Hashtags"
)
添付画像を一斉DLする
dl_url <- function(dat) {
download.file(dat, destfile = basename(dat), mode = "wb")
Sys.sleep(0.5)
}
num <- 10 # リツイート→いいね順に10件DL
df_pic <- tweet_df %>%
unnest(media_url) %>%
drop_na(media_url) %>%
arrange(desc(favorite_count)) %>%
arrange(desc(retweet_count)) %>%
distinct(id_str, .keep_all = TRUE) %>%
slice(1:num)
df_pic$media_url %>% walk(dl_url)◆最後に
リスト操作に慣れていなかったため、今回の変更で結構戸惑いました。
rtweetでツイートを収集している方はupdateしていない方もいるかもですが、ご参考になれば幸いです。
ありがとうございます。