
R言語{gtrendsR}の時系列データで遊ぶ

●本記事でやること
・Rで時系列データを取り扱う。
・{gtrendsR}パッケージでGoogle Trendsデータを取得する。
・実データを加工しTrendsデータと組み合わせ、ggplotで図示する。
●前置き
時系列データ分析に最近ハマっております。
時系列データの中で、実データと実社会における注目度(トレンド)の変化にどのように関係があるかは興味深いところです。
例えば、実データの増減の前にトレンドの上昇が予兆となって現れるのであれば前もって対策が可能ですし、実データの増加と比較してトレンドの上昇が小さければそれほど社会的な反応は大きくないのかもしれません。
今回はRの{gtrendsR}パッケージによってGoogleトレンドデータを取得し、実際の時系列データと比較してみました。
Google TrendsデータはRを使わなくてもCSVファイルで取ってこれるのですが...Rで取得できるとキモチイイのです。
●例1:Bitcoin
予想が難しいカオスな時系列データと言えばBTCチャートです。
BTC-USDチャートとGoogle Trendsのサーチ数を比較してみます。
・library読み込み
# load library
if (!require("tidyverse")) install.packages('tidyverse')
if (!require("lubridate")) install.packages('lubridate')
if (!require("quantmod")) install.packages('quantmod')
if (!require("gtrendsR")) install.packages('gtrendsR')
if (!require("stringi")) install.packages('stringi')使用するパッケージは以下の通りです。
データ成型に用いる{tidyverse}
時系列データ処理に用いる{lubridate}
BTCデータの取得に用いる{quantmod}
Google Trendsデータ取得に用いる{gtrendsR}
{gtrendsR}を使用する際のエンコードエラーの回避に用いる{stringi}
・BTCデータの取得
金融分析用パッケージの{quantmod}により、ALPHA VANTAGEのAPI keyを使用してBTC-USDデータを取得します。
ALPHA VANTAGE API keyについてはサイトを参照してください。
https://www.alphavantage.co/
# download BTCUSD from https://www.alphavantage.co/
btc <- getSymbols("BTCUSD",
src = "alphavantage",
api.key = "yourapikey", # ALPHA VANTAGE API key
output.size = "full",
auto.assign = TRUE)トレンドデータは0から100の数値なので、比較や容易なように最大値100のパーセンテージデータにしてやります。
今回は過去一年間の終値を使用します。
また、ggplotフレンドリーな整然(tidyな)データにしてやるためにmutateでline列を作成してデータ名を追加しています。
BTCUSD2 <- data.frame(date=index(BTCUSD), coredata(BTCUSD)) %>%
mutate(date = ymd(date),
BTCUSD=as.numeric(BTCUSD.Close)/max(as.numeric(BTCUSD.Close))*100) %>%
select(date, BTCUSD) %>%
dplyr::filter(date >= Sys.Date()-365*1) %>%
mutate(line = "Actual BTC-USD Percentage")・Google Trendsデータの取得
次に{gtrendsR}パッケージによってGoogle Trendsデータを取得します。
{gtrendsR}パッケージはwindows環境から実行するとエンコードのエラーが発生し、結果が文字化けします。いつものSHIFT-JIS⇔UTF-8問題です。
このためWindows以外の環境やRstudio Cloudで分析することが望ましいです。
私のような趣味でやってるニワカRユーザーでは当然基本環境はwindowsですので、このままでは{gtrendsR}を使用することはできません。
実際、普段gtrendsRを使用する際はRstudio Cloud環境で実施しています。(早くDockerのUbuntu環境に移行しないと...)
しかしトレンド数値データのみの取得であればロケールを変更した上で、{stringi}パッケージでエンコードをUTF-8に変えてやることで問題なく取得が可能でした。最後に念のため変えたロケールを戻してやります。
こちらも一年間のデータを取得します。取得範囲を変えたい時にはtimeを指定された語句に変えてやります。
# trends data acquire data from Google Trends using {gtrends}
search_words = "Bitcoin"
# set locale to avoid invalid multibyte error under MS environment
Sys.setlocale("LC_ALL","English")
res <- gtrends(
keyword = stri_encode(search_words,"","utf-8"), # search word
geo = "", # search location all
time = "today 12-m"
)
# time = "now 1-H" # last hour
# time = "now 1-d" # last day
# time = "today 1-m") # last 30 days
# time = "today 3-m") # last 90 days
# time = "today 12-m") # last 12 months
# time = "today+5-y" # last five years (default)
# time = "all" # since 2004
# restore locale to JP
Sys.setlocale("LC_CTYPE", "Japanese_Japan.932")・データ成型
取得したデータをggplotで図示するため整形してやります。
Google Trendsのデータには1以下を示す”<1”というデータが含まれるため、これをas.numericでNAにした後、NAを0にします。
# preprocess data for ggplot
trends <- res$interest_over_time %>%
as_tibble() %>%
mutate(date = ymd(date)) %>%
mutate(BTCUSD = suppressWarnings(as.numeric(hits))) %>% # convert <1 to NA
select(date,BTCUSD) %>%
mutate(line = "Google Search Trends")
trends$BTCUSD[is.na(trends$BTCUSD)] <- 0 # convert NA to 0
・ggplotでグラフに
その後、両者のデータをggplot friendlyな形で結合してやり、line plotを作成。
フォントはTakaoフォントをお借りしました。
https://launchpad.net/takao-fonts
# plot actual vs trends
windowsFonts("TPG"=windowsFont("Takao Pゴシック")) # https://launchpad.net/takao-fonts
dat_g <- bind_rows(BTCUSD2, trends)
g <- dat_g %>%
ggplot(aes(x = date, y = BTCUSD, color = line)) +
geom_line(size=1.3) +
labs(title = " BTC actual vs trends") +
theme_minimal(base_size = 16, base_family = "TPG")
plot(g)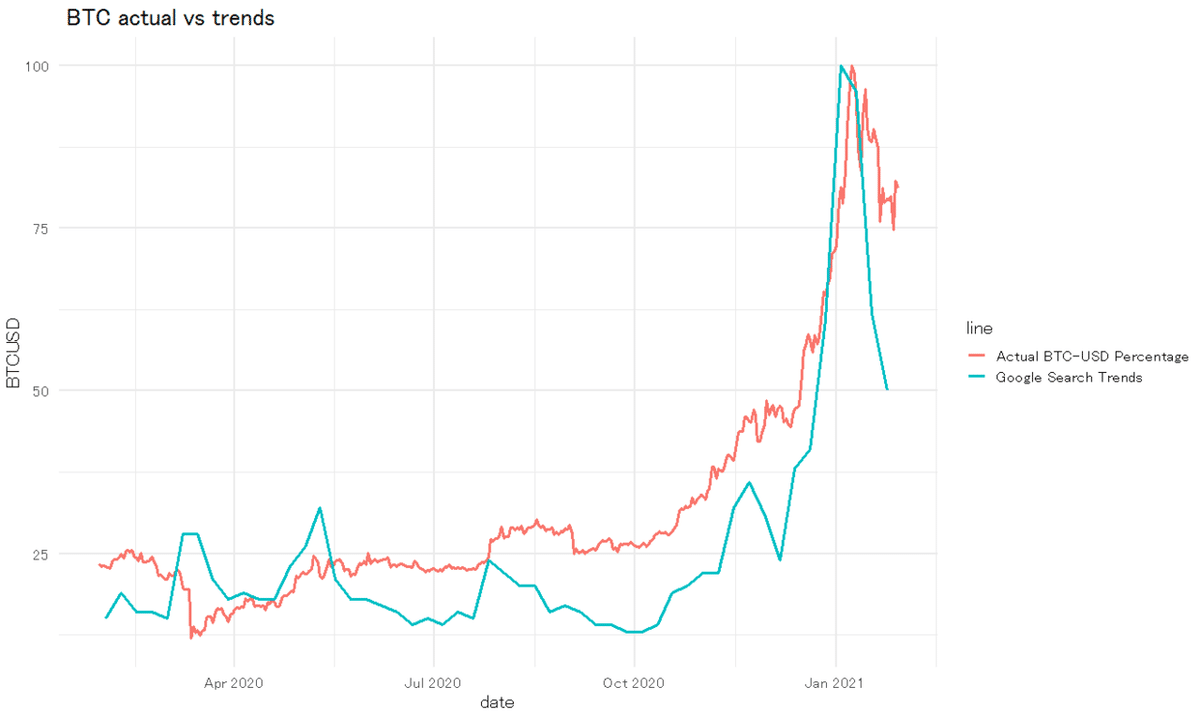
実際の相場が上昇、または下降する際にGoogle Trendsの増加が見られることが分かります。
時間当たりデータにするなど分解能をあげてやればより有用な指標が得られそうです。
●例2:コロナウイルスPCR陽性者数vsコロナサーチ数
手順はBTCの場合と同様。
まずは”コロナ”という検索ワードでGoogle Trendsデータを取得してやります。
# load library
library(tidyverse)
library(lubridate)
library(gtrendsR)
library(stringi)
search_words = "コロナ"
# set locale to avoid invalid multibyte error
Sys.setlocale("LC_ALL","English")
res <- gtrends(
keyword = stri_encode(search_words,"","utf-8"), # search word
geo = "JP", # search location
time = "today 12-m" # Data search period 5 years time = "all" since 2004
)
# restore locale to JP
Sys.setlocale("LC_CTYPE", "Japanese_Japan.932")
head(res[1]) # check data
trends <- res$interest_over_time %>%
as_tibble() %>%
mutate(date = ymd(date)) %>%
mutate(hits = suppressWarnings(as.numeric(hits))) %>%
select(date,hits) %>%
mutate(line = "Google Search Trends") %>%
dplyr::filter(date >= as.Date("2020-01-01"))
trends$hits[is.na(trends$hits)] <- 0・陽性者数データの取得
実際の陽性者数のデータを取得します。
厚生労働省のページからデータを取得します。こんな感じでurlを読み込ませてやれば読めました。
カラム名をデータをy、日付をdsにしてるのは本分析には特に意味はないのですが、{prophet}パッケージに使えるようにです。機会があったらそちらも記事にします。
# PCR positive in Japan data import
url <- "https://www.mhlw.go.jp/content/pcr_positive_daily.csv"
# Ministry of Health, Labour and Welfare (Japan)
dat <- readr::read_csv(url, locale = locale(encoding = "utf8"))
colnames(dat) <- c("ds","y")・データ成型
同様に最大値100のパーセンテージデータにしてやります。
今回は過去一年間の終値を使用しました。
BTCの時と同じようにtidyなデータにしてやるためにline列を作成してデータ名を追加。
最後にTrendsデータとbind_rowsで結合。
dat <- dat %>%
mutate(date = ymd(ds)) %>%
mutate(hits = y/max(y)*100) %>%
select(date,hits) %>%
mutate(line = "Actual PCR positives \nPercentage")
str(dat) # check data
dat2 <- bind_rows(dat, trends)・ggplotで図示
g <- ggplot(dat2, aes(x = date, y = hits, color = line)) +
geom_line(size=1.3) +
labs(title = " Coronavirus actual vs trends") +
theme_minimal(base_size = 16, base_family = "TPG")
plot(g)
実際の陽性者数と検索数を比較
過去と比較すると、陽性者数の増加に対し、検索数が伸びなくなっている(反応しなくなっている)様子が分かります。
トレンドデータとあわせて見ることによって、感染者数増加や対策への反応、買占めや品切れの兆候を推定することができるかもしれませんね。
●結論
時系列データは楽しい。
●使用したコード
# BTC Actual vs trends
# load library
if (!require("tidyverse")) install.packages('tidyverse')
if (!require("lubridate")) install.packages('lubridate')
if (!require("quantmod")) install.packages('quantmod')
if (!require("gtrendsR")) install.packages('gtrendsR')
if (!require("stringi")) install.packages('stringi')
# download BTCUSD from https://www.alphavantage.co/
btc <- getSymbols("BTCUSD",
src = "alphavantage",
api.key = "yourapikey", # ALPHA VANTAGE API key
output.size = "full",
auto.assign = TRUE)
# create dataframe and caliculate BTC-USD percentage
BTCUSD2 <- data.frame(date=index(BTCUSD), coredata(BTCUSD)) %>%
mutate(date = ymd(date), BTCUSD=as.numeric(BTCUSD.Close)/max(as.numeric(BTCUSD.Close))*100) %>%
select(date, BTCUSD) %>%
dplyr::filter(date >= Sys.Date()-365*1) %>%
mutate(line = "Actual BTC-USD Percentage")
# trends data acquire data from Google Trends using {gtrends}
search_words = "Bitcoin"
# set locale to avoid invalid multibyte error under MS environment
Sys.setlocale("LC_ALL","English")
res <- gtrends(
keyword = stri_encode(search_words,"","utf-8"), # search word
geo = "JP", # search location
time = "today 12-m"
)
# time = "now 1-H" # last hour
# time = "now 1-d" # last day
# time = "today 1-m") # last 30 days
# time = "today 3-m") # last 90 days
# time = "today 12-m") # last 12 months
# time = "today+5-y" # last five years (default)
# time = "all" # since 2004
# restore locale to JP
Sys.setlocale("LC_CTYPE", "Japanese_Japan.932")
# preprocess data for ggplot
trends <- res$interest_over_time %>%
as_tibble() %>%
mutate(date = ymd(date)) %>%
mutate(BTCUSD = suppressWarnings(as.numeric(hits))) %>% # convert <1 to NA
select(date,BTCUSD) %>%
mutate(line = "Google Search Trends")
trends$BTCUSD[is.na(trends$BTCUSD)] <- 0 # convert NA to 0
# plot actual vs trends
windowsFonts("TPG"=windowsFont("Takao Pゴシック")) # https://launchpad.net/takao-fonts
dat_g <- bind_rows(BTCUSD2, trends)
g <- dat_g %>%
ggplot(aes(x = date, y = BTCUSD, color = line)) +
geom_line(size=1.3) +
labs(title = " BTC actual vs trends") +
theme_minimal(base_size = 16, base_family = "TPG")
plot(g)
# Corona virus actual VS trends
# read library
library(tidyverse)
library(lubridate)
library(gtrendsR)
library(stringi)
search_words = "コロナ"
# set locale to avoid invalid multibyte error
Sys.setlocale("LC_ALL","English")
res <- gtrends(
keyword = stri_encode(search_words,"","utf-8"), # search word
geo = "JP", # search location
time = "today 12-m" # Data search period 5 years time = "all" since 2004
)
# restore locale to JP
Sys.setlocale("LC_CTYPE", "Japanese_Japan.932")
head(res[1]) # check data
trends <- res$interest_over_time %>%
as_tibble() %>%
mutate(date = ymd(date)) %>%
mutate(hits = suppressWarnings(as.numeric(hits))) %>%
select(date,hits) %>%
mutate(line = "Google Search Trends") %>%
dplyr::filter(date >= as.Date("2020-01-01"))
trends$hits[is.na(trends$hits)] <- 0
# PCR positive in Japan data import
url <- "https://www.mhlw.go.jp/content/pcr_positive_daily.csv"
# Ministry of Health, Labour and Welfare (Japan)
dat <- readr::read_csv(url, locale = locale(encoding = "utf8"))
colnames(dat) <- c("ds","y")
dat <- dat %>%
mutate(date = ymd(ds)) %>%
mutate(hits = y/max(y)*100) %>%
select(date,hits) %>%
mutate(line = "Actual PCR positives \nPercentage")
str(dat) # check data
dat2 <- bind_rows(dat, trends)
g <- ggplot(dat2, aes(x = date, y = hits, color = line)) +
geom_line(size=1.3) +
labs(title = " Corona virus actual vs trends") +
theme_minimal(base_size = 16, base_family = "TPG")
plot(g)