
データモデル(ER図)の表記法「IDEF1X」の基本(とkintoneでどう使うかの考察)

以前DA(Data Architect)としてデータモデリングをやっていました(いわゆるデータモデラー)。
使っていたツールはER/Studio(少しだけERWin)、現在は個人で購入したObject Browser ERを使い、表記法はIDEF1Xです。
20年前に身につけた知識ですが、実は今でも常にkintoneアプリ開発の相談や伴走支援のとき、頭の中ではデータモデルで整理したり、ホワイトボードにデフォルメして認識合わせに使っています。
データ構造を可視化できるデータモデリングは知っておいて損はなく、長く使えるスキルかと思い、長文にまとめてみようと思います。
・ここで記述するデータモデルは「概念データモデル」が中心です。
・最近のWebツールでは表記法としてIDEF1XよりIE(鳥の足)の方が主流のようです(大規模開発向けのツールしかIDEF1Xは対応していない?)
・kintone開発者の視点でkintoneの用語も交えて説明します。
→関連レコード一覧やルックアップの表現方法が目下の興味
1. データモデルの概要
1.1 データモデルとは?
データモデルはデータベースの設計図で、データの構造を図にしたものです。
建築で例えるなら、建物を建てる前の設計図かと思います。なので、設計図を作る建築士をアーキテクト(Architect)と呼ぶのに対し、データベース(データ構造)の設計者をデータアーキテクト(Data Architect、略してDA)と呼びます。
データモデルは、その用途やフェーズにより大きく以下3種類に分かれますが、専門的なデータベースを作るわけではないのでここでは概念データモデル(Conceptual Data Model)にフォーカスします。
概念データモデル:業務全体のデータをざっくり整理(システムに依存しない)。
建物で言えばパース図や手書きスケッチぐらい?論理データモデル:処理や要件に基づき最適化したデータベース全般向け。ここまでは日本語で書くことが多い。
建物で言えば平面図や立面図ぐらい?物理データモデル:個別のデータベース製品(DBMS)への実装前提。製品ごとにデータ型も異なる。実際のテーブル名やカラム名になるためそのままSQL文(DDL)に書き出すこともできる。
建物で言えば構造設計図や施工図ぐらい?
kintoneで論理モデルと物理モデルを説明すると、
論理データモデルではフィールド名
物理データモデルではフィールドコード
で書くイメージです。なので、あまり違いはありません。
概念データモデルは、ざっくりと概念的に(コンセプチュアルに)表現する際に使います。
その程度の使い方で十分かと思います。
なお、私がkintoneアプリを開発する際は(なるべく)論理や物理を意識しなくて済むように、フィールド名とフィールドコードは一致させるようにしています。
つまり、なかぐろ「・」かアンダースコア「_」を使い、カッコ「()」は使わないように努力しています。
フィールド名を設定したら、直後にフィールドコードも合わせて修正(コピペ)する「習慣」は非常に大事です。
フィールド名の横に「フィールドコードを同期する」チェックボックスのようなのをつけて頂きたいなあと思う今日この頃です。
2. データモデルの基本1
ER図(ER Diagram)とは、エンティティ(Entity)とリレーションシップ(Relationship)を使った図(Diagram)です。
まずこの2種類を覚えるのが最重要です。
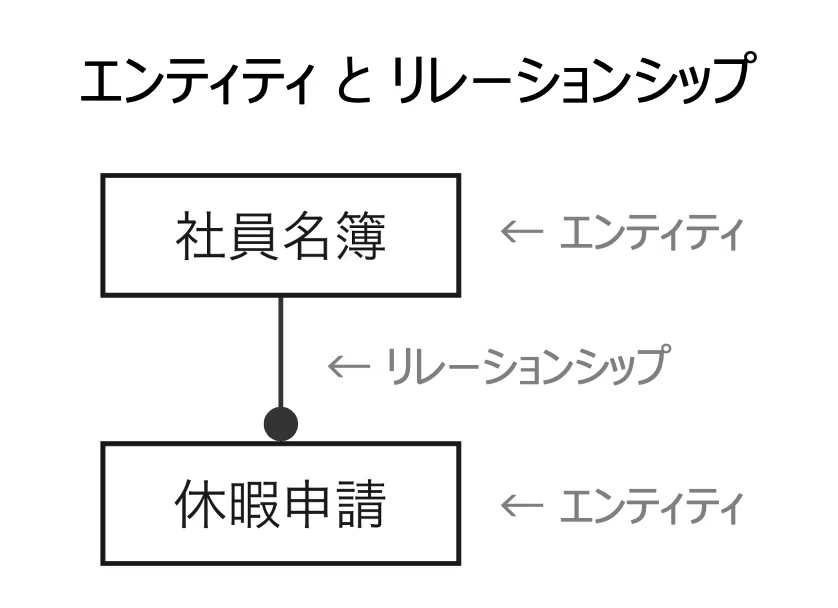
これを覚えると、常に「1対多の関係」(1:N)を意識できるようになります。これがほぼゴールです。
アプリ開発を考え始めた最初の段階で、打ち合わせしながら「1:N」なのか「1:1」なのか「N:N」なのか、を整理できるのがデータモデリングのメリットです。
「1:N」の関係を初期の段階で整理できれば、余計な手戻りがグッと減ります。80%ぐらい減ります。
2.1 サンプルアプリとデータモデル
kintoneアプリストアにある「おすすめ機能体験パック」というサンプルアプリをベースにデータモデルを解説していきます。


アプリパックを追加すると、2つのアプリが作成されます。

作成された「社員名簿」と「休暇申請」アプリの関係をデータモデルにしたのが以下です。これをベースにします。

上記のようなエンティティレベルで表現できるだけでも、データモデラー同士の会話の場合、意思疎通が格段に高まります。
細かい表現をする場合は属性レベル(定義レベル)のデータモデルを用いるのが一般的ですが、以下はどれも同じエンティティをレベルを変えて見せています。

以下、教科書的な内容も交えながら、長文で解説していきます。
2.2 エンティティ
エンティティとは、データベースで管理したい「モノやコト」のことです。
例えば、
リソース(例:顧客や製品のマスター情報)
イベント(例:注文や支払い)
サマリ(例:毎月の受注合計)
スナップショット(例:月末時点の在庫状態)
などがあります。
まずは「リソースとイベント」の大きく2つに分かれるという意識を持つだけでよいかと思います。(「マスタとイベント」でもよい)
エンティティは、
データベースでいうとテーブルです。
kintoneでいうとアプリです。
Excelでいうと1シートです。
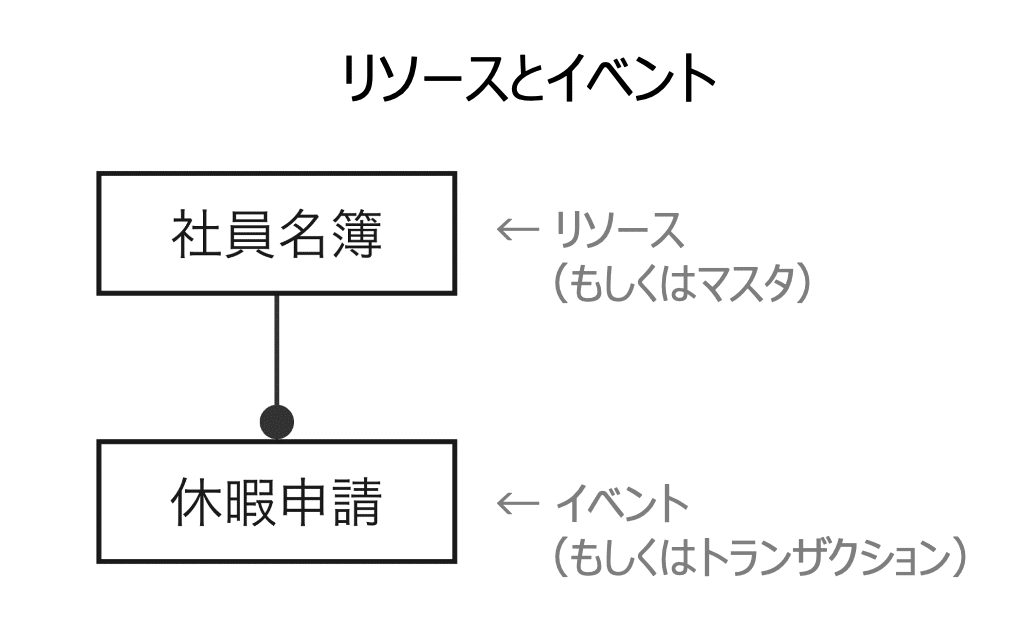
「社員名簿」エンティティには、1従業員あたり1レコードだけ存在するイメージです。
データは頻繁に更新されません。引っ越した時に住所が変更されたり、退職時に退職日が設定するときなどしか更新されません。
そのようなエンティティを「リソース(俗にマスタ)」と呼びます。

次に「休暇申請」エンティティには、休暇申請のたびに1レコードが追加されるイメージです。何かのイベントごとにどんどんレコードが追加されていくので、マスタ(リソース)ではなくイベントと呼ばれます(トランザクションという言い方もよく使われます)。

リソースとマスタ、どっち?
「マスタ」という呼び方が会話の中でも通じるなと感じます。一番市民権を得ている気がします。
イベントとトランザクション、どっち?
トランザクションはデータベースエンジニアにはしっくりきますが、単語が難しいので「イベント」の方がイメージしやすいかと思います。
なので、個人的には普段「これはマスタ系、これはイベント系」という呼び方が多いです。
2.3 リレーションシップ
上の休暇申請アプリの一覧をみると、星野さん(社員番号106)は、休暇申請を2件提出しています。
一方で社員名簿には、星野さんのレコードは1件しかありません。
つまり、社員名簿と休暇申請の関係は1:Nです。
これをデータモデルに表すと、以下のように表現できます。
あとで詳しく出てきますが、この線と丸がリレーションシップで、1対多の関係を表しています。
基本的に、これだけ表現できれば、シンプルなkintoneアプリ開発では十分かと思います(特に市民開発の場合)。
これ以上細かく表現しようとすると、深みにハマっていきます。
以降、データモデリングの基礎ではありますが、エンティティ(アプリ)レベルではなく、属性(フィールド)レベルという細かい世界に突入します。
つまり、アプリを細かく設計するレベルの話になるため、kintoneのノーコード開発、特に市民開発においては優先度は下がります。
組織内で内製化を行い、きちんとしたアプリ設計を行うような場合には、以降も読み進んでいただくとデータモデリングの勉強になるかと思います。
アールスリーさんのグスクカスタマインなら「設計情報のダウンロード機能」を使うだけで、アプリの情報を出力することができます。
kintoneアプリの設計情報ダウンロード機能について
この機能は素晴らしく、いわゆる「データ定義書」を出力することができます。さらにkintoneアプリの様々な設計情報を出力することもできます。
補足:キーの重要性

ちなみに、もう一つ意識できると格段にアプリ設計の質が上がるのが「キー」です。
一意である属性をキーと言います。
一意というのは「他に同じものがなく、唯一無二であること」です。
社員名簿アプリで言えば「社員番号」が一意なキーです。
社員番号さえ分かれば、社員名簿の中から必ず1つのレコードを見つけることができます。

kintoneではフィールドの設定情報の中で「値の重複を禁止する」にチェックを入れたものが「キー」となります。
また「レコード番号」もキーです。これはkintoneのシステムが必ず作成する「1から始まる意味なし連番の一意キー」です。
データモデリングでは、この「キー」が重要になりますが、kintoneアプリを作る上でも、
キーとなるフィールドはなんだろう?
「値の重複を禁止する」にチェックが入るフィールドは何だろう?
という意識は常に持っておくのがよいです。
なおkintoneの場合、レコード番号が必ずキーとなります。
これを使って(レコード番号を主キーとして)管理するのも良いのですが、レコード番号以外にキーとなるフィールドを用意することをおすすめします。(特にマスタ系アプリの場合)
・レコードを削除するとレコード番号が歯抜けになる
・アプリの移行(データ移行)を行うとレコード番号が変わる
といった運用上の課題が発生する可能性があるためです。
ここまででOK
データモデルの基本的な理解は、ここまででいいと思っています。
つまり、エンティティレベルで1対N(1対多)の関係を認識合わせに使えるようになるだけで、システム開発の概念設計フェーズでは絶大な効果が生まれます。
「議論の空中戦をさけ、ホワイトボードに落とし込む」のに使うのが良いでしょう。
でもkintoneなら「アプリを作りながら考える」方がアリなケースも多いです(本末転倒)。
3. データモデルの基本2
ここからは、属性レベルの細かい話に入るため優先度は低いです。
リレーションシップの種類やサブタイプといった、より柔軟にデータ構造を表記するノーテーション(表記法)の話が中心です。
しかも最近のWebツールではIDEF1Xではなく鳥の足モデル(IE記法)の方が多く使われており、IDEF1Xは最近のシステムというよりはレガシーな大規模システム向けの表記法なのかも知れません。
3.1 属性とキー
エンティティを構成する情報を「属性」と呼びます。
属性は、大きく分けて主キー、非キー、外部キーの3種類があります。

主キー
表記法、説明
エンティティを2つに分割した上側に表現されます。
エンティティ内のレコードを一意に識別する属性、または2つ以上の属性のグループ(複合主キー)です。
主キーは空値(NULL)を許しません。(値が必須)
注意点
主キーとなる属性が多い場合、単一属性のキーを別に作成して「代理キー」とします。
kintoneの場合は、レコード番号が「意味なし連番の代理キー」となっています。自然と代理キーが使える便利な状態といえます。

非キー
表記法、説明
エンティティを2つに分割した下側に表現されます。
注意点
導出属性(例えば、開始時刻と終了時刻から計算すれば導出できる時間など)は、表現しないようが望ましいと言われています(冗長なので)。
ただし認識合わせや、情報の欠落防止のために表現することが多いです。導出属性の場合は、なんらかの記号などで識別できるようにするのが望ましいです。
外部キー
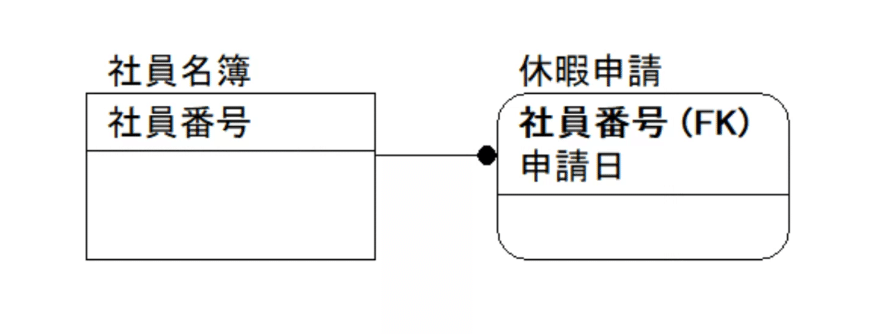
表記法、説明
属性名のうしろに(FK)の文字(Foreign Keyの略)を追加して表現されます。
リレーションシップを通じて、親エンティティの主キー属性が、子エンティティに組み込まれます。
上記の図(休暇申請エンティティ)の場合、親エンティティである社員名簿エンティティの主キー「社員番号」が、子エンティティの休暇申請エンティティの外部キーとして組み込まれています。
注意点
親エンティティの中に、主キーと合わせて頻繁に使用される属性(例えば氏名や部署名)が存在する場合、子エンティティにコピーを作成する場合があります。
親エンティティと子エンティティで属性が重複することになりますが、「テーブルの結合」が不要となるため、処理速度を考慮した設計ではよく行われます。
このことを「データを冗長に持つ」といった言い方をしますが、その場合は「本来は別エンティティから導出できるけれども、わざと冗長に持たせている属性」であることをなんらかの記号などで識別できるようにするのが望ましいです。
補足:導出属性の表現について
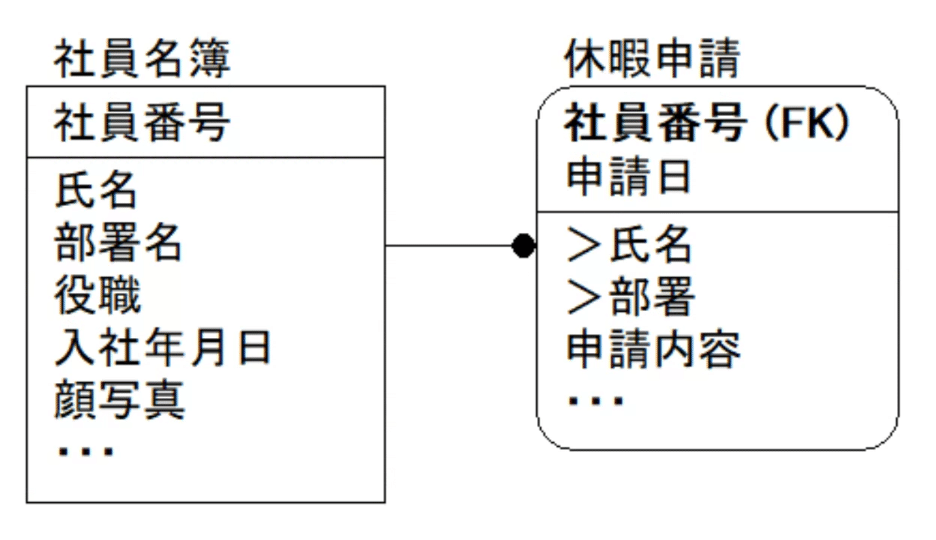
上記非キー、外部キーの注意点に出てきた「導出属性」は、データモデルでは上の図のように「>」という記号で表現してきました(個人の経験より)。
kintoneのアプリ開発においても、ルックアップの際「ほかのフィールドのコピー」を行うことが多いかと思います。
このコピーするフィールドがまさに「導出属性」で、わざわざキーを辿って親アプリを参照することなく、子アプリにコピーして値を冗長に持たせる手法です。
これにはメリットとデメリットがあることは、kintone開発者なら誰しも経験するところです。
メリット:その時の親アプリの情報を残すことができる。
デメリット:最新の親アプリの状態が反映されない(親アプリを変更しても子アプリに自動で反映されない)
逆に関連レコード一覧の特徴は、
メリット:親アプリのレコードの最新内容を常に確認することができる
デメリット:子アプリに値を持たせることができない
かと思います。
このルックアップと関連レコード一覧をうまく使い分けることがkintone開発の醍醐味のような気がしています。
私はkintoneを始めた当初、とある外部の方から「kintoneはデータベースではないので、ルックアップのように親(マスタ)側のキーを子に持たせても、親側の最新情報を反映できない。kintoneは不便だ」と聞いて、その時は「そうなんだぁ、残念」と思ったのですが、翌月に関連レコード一覧という基本機能を知り「これはリレーションシップを実現しているじゃないか」と理解を改めました。(ここからkintoneをデータベースとして扱えるな、と思った)。
この関連レコード一覧機能は、kintoneの中でもリレーショナルなデータベースを意識してアプリ設計を行うことができるという点で、一番好きな機能です。
(なおパフォーマンスに注意が必要ですが、関連レコード一覧を設定すると、子アプリ側の一覧の絞り込み条件に親アプリのフィールドを設定して検索することもできます)
3.2 リレーションシップ(詳細)
エンティティ同士の関係性を主に線と点で表現します。
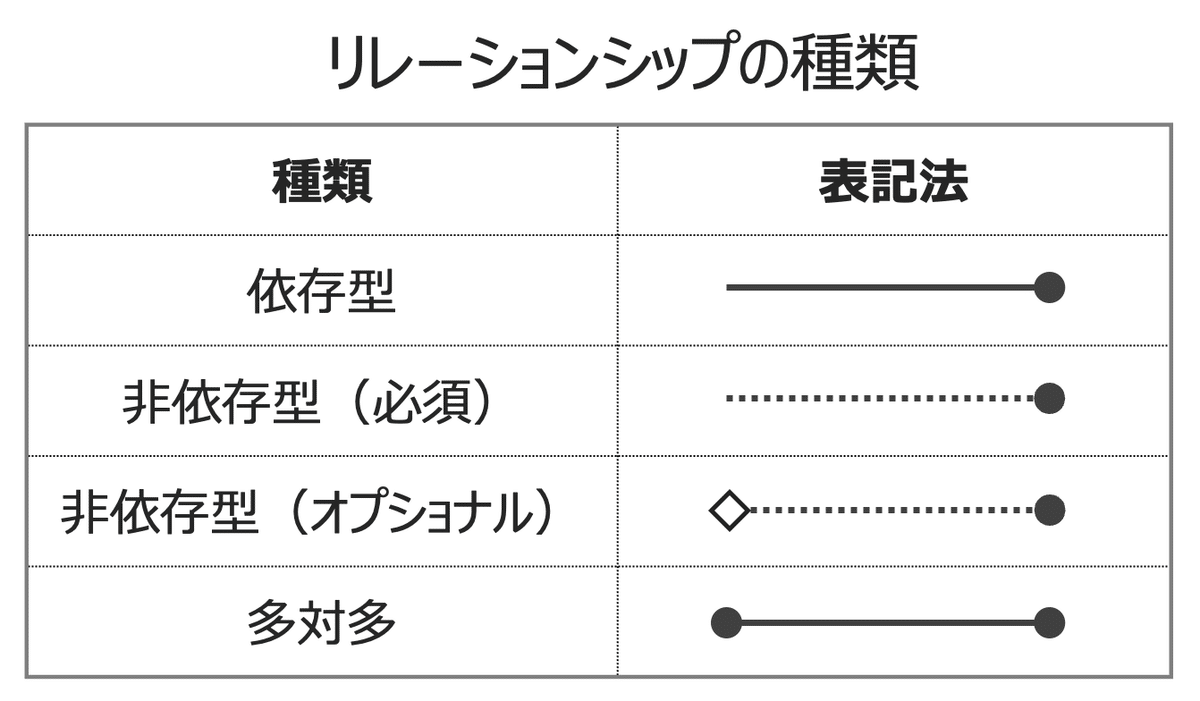
1. 依存型(Identifying Relationship)
説明
親エンティティのすべての主キーが、子エンティティの主キーに組み込まれます。
特徴
子エンティティは、親エンティティが存在して初めて意味を持ちます。
子エンティティは主キーの一部に親エンティティの主キーを含むため、親が存在しない場合に子を作成することはできません。
例
「注文」エンティティと「注文詳細」エンティティ
親: 注文ID(主キー)
子: 注文ID + 商品ID(主キー)
注文がなければ、注文詳細は存在できません。
表記
線が実線で描かれます。
アナロジー
親が必須で、親に依存する子
2. 非依存型(必須)(Non-Identifying, Mandatory Relationship)
説明
親エンティティのすべての主キーが、子エンティティの非キー属性として移ります。親エンティティの存在が必須となります。
特徴
子エンティティは親エンティティに依存しませんが、子を作成する際には親が必須です。
外部キーとして親の主キーが保存されます。
例
「顧客」エンティティと「契約」エンティティ
親: 顧客ID(主キー)
子: 契約ID(主キー)、顧客ID(非キー属性)
顧客は必須だが、契約IDだけで一意に識別できる
表記
線が点線で描かれ、接続端に菱形なし。
アナロジー
親が必須だが、子は親に依存せず独立【親はいるけど独り立ち】
3. 非依存型(オプショナル)(Non-Identifying, Optional Relationship)
説明
親エンティティのすべての主キーが、子エンティティの非キー属性として移りますが、親エンティティの存在は任意です。
特徴
子エンティティは、親エンティティに紐付かないレコードを持つことができます。
親が存在しなくても子を作成可能です。
例:
「担当者」エンティティと「タスク」エンティティ親: 担当者ID(主キー)
子: タスクID(主キー)、担当者ID(非キー属性、NULLを許容)
表記
線が細線で描かれ、接続端に菱形(◇)が追加されます。
アナロジー
【親はなくとも子は育つ】
4. 多対多型(Many-to-Many Relationship)
説明
2つのエンティティ間で複数のレコードが相互に関連付けられる関係。
特徴
多対多の関係を直接表現するのは困難なため、通常は中間テーブル(関連エンティティ)を作成します。
中間テーブルでは、それぞれのエンティティの主キーを含めて新しい主キーを構成します(複合主キー)。
例
「学生」エンティティと「クラス」エンティティ
中間テーブル: 学生ID + クラスID
学生Aは、クラス「1年1組」だが、来年は別のクラス「2年1組」に。
表記
直接的なリレーションではなく、中間エンティティとして三者関係を構築。
3.3 スーパータイプ/サブタイプ

共通属性をまとめた親(スーパータイプ)と、分類された子(サブタイプ)を表現します。
(例:「乗り物」を「自動車」と「自転車」と「船」に分ける)
これは「概念モデル」で何らかの区分を表現する時に使う特別な表記法です。共通の特性(属性)を持つエンティティをグループ化する、という言い方もできます。
3.4 カーディナリティ
カーディナリティは、1つの親エンティティの主キーに対して、いくつの子エンティティのレコードが対応するかを正確に表現するためのルールです。

1 : 0~N
意味:親エンティティの1つのレコードに対して、子エンティティは0個からN個のレコードが関連付けられます。
表記法:なし
例:顧客と問い合わせ
顧客が問い合わせをしたことがない(0件)場合もあれば、複数回問い合わせをしている(N件)場合もあります。
1 : 1~N
意味:親エンティティの1つのレコードに対して、子エンティティには最低1件以上、N件のレコードが関連付けられます。
表記法:P(おそらく「存在する」という意味のPresenceかなと)
例:レシピと材料
レシピには少なくとも1つ以上の材料が必要です。材料がないレシピは成立しません。
1 : 0または1
意味:親エンティティの1つのレコードに対して、子エンティティには0件または1件のレコードが関連付けられます。
表記法:Z(Zero or One)
例:受験生と合格者
受験生の中には合格者が存在しない場合(0件)も、合格者として記録される場合(1件)もあります。
1 : N(固定)
意味:親エンティティの1つのレコードに対して、子エンティティには固定されたN件のレコードが関連付けられます。
表記法:定数N(例: N=8)
例:バスケの試合と先発選手
各バスケの試合には必ず固定された数(N=5)の先発選手が登録されます。選手の数は試合ごとに固定されています。
4. さいごに結論、kintoneアプリ開発にER図をどう活かすか
ここまで、基本的なER図の表記法をまとめてみたのですが、kintoneでこれをどう活かすか考えてみました。
結論「この表記法は不要」と考えます(笑)
(むしろER図など必要ないのがkintoneのよさ)
kintoneで本格的なDBシステムを構築していく場合は、ER図による全体の俯瞰も良いかと思います。ただしサブテーブル(kintone基本機能のテーブル)を別エンティティに書いたり、関連レコード一覧やルックアップを表現する表記法でも無いため、なかなか労力に見合わない気がします。
よりkintoneに合う表現方法を考えた方がよいかと思っています。
そんななか、2024年11月のCybozu Days 2024にヒントがありました。
「ワイドコース」の中でアプリ分析(2025年リリース予定)についての紹介があり、それらしいものが。

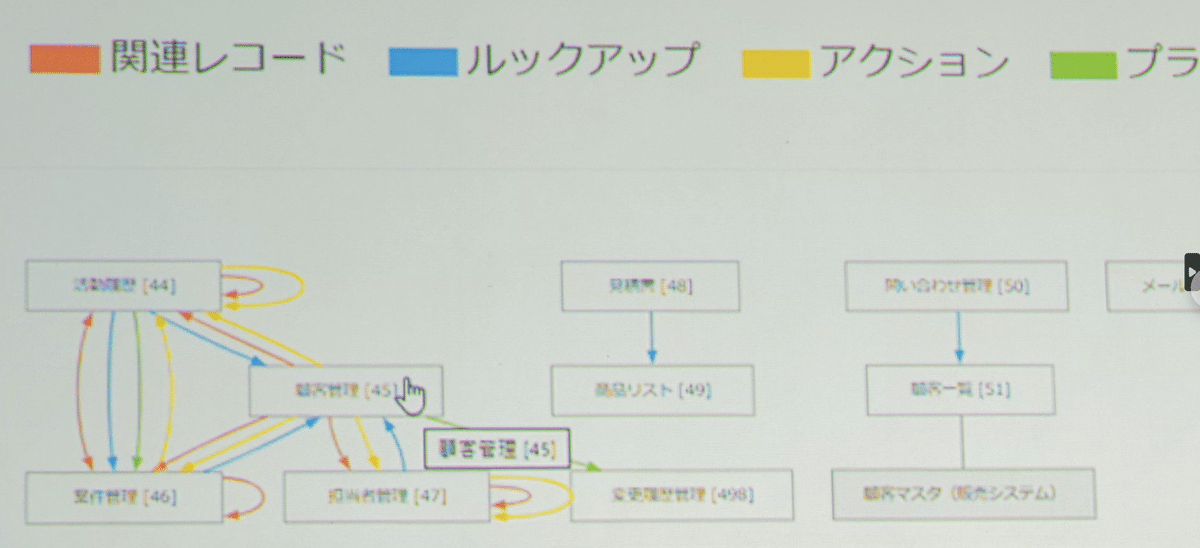
アプリ(エンティティ)を、矢印で繋いでいます。基本的に矢印に色で意味を持たせており、
赤→関連レコード(関連レコード一覧かと)
青→ルックアップ
黄→アクション(アプリアクションかと)
緑→プラグイン/カスタマイズ
灰→外部システム連携(外部連携サービスかと)
としています。
まだ開発中の画面かと思うので、リリース時には変わるかもしれませんが、これぐらいがいい塩梅なのかもしれません。
これも踏まえながら、kintoneでのアプリ構造を「いい加減」に表現できる表記方法を考えたいと思う2024年大晦日でした。
(2024年12月31日初稿、書き足りないので改訂予定)
(足りないこと思い出しメモ。再帰リレーションシップ。部品表(多対多))