Power BI -今日の関数 -SUMX()

参考としたサイト
定義の確認: DAXリファレンス
説明のための例1~5: Powerpivot(pro)
説明のための例6: stack overflow
1. リファレンスの確認
説明: テーブルの行ごとに評価される式の合計値を返します。
構文: SUMX(<table>, <expression>)
※<table>: 式が評価される行を含むテーブル
※<expression>: テーブルの行ごとに評価される式
戻り値: 10進数(スカラー値)
解説: SUMX 関数は、1 番目の引数として、テーブル、またはテーブルを返す式を受け取ります。 2 番目の引数は、合計値を計算する数値を含む列、または列に評価される式です。
列内の数値のみがカウントされます。 空白、論理値、およびテキストは無視されます。
数式内の SUMX のより複雑な例については、ALL 関数 (DAX) および CALCULATETABLE 関数 (DAX) に関するページを参照してください。
例: 次の例では、まず、式 ShippingTerritoryID = 5 におけるテーブル InternetSales をフィルター処理し、次に、列 Freight 内のすべての値の合計を返します。 つまり、式からは、指定された販売区域についてのみ、運送料の合計が返されます。
=SUMX(FILTER(InternetSales, InternetSales[SalesTerritoryID]=5),[Freight])列をフィルター処理する必要がない場合は、SUM 関数を使用します。 SUM 関数は、列を参照として使用する点を除いて、同じ名前の Excel 関数に似ています。
これだけ読んで理解できる人って、いるの・・?
例の中に入っている式もメジャーだし、、私はこれを何度も何度も、、読み返しましたが、ここだけでは全く理解できませんでした。。
2. Powerpivot(pro)の説明
リファレンスで分からなければ、ネットサーフィンの旅に出るしかない。そこでまず見つけたのが、こちら。
投稿者の名前はどっかで見たことあるなぁと思っていたら、座右の書としていた、元マイクロソフトの人が書いたこの本の著者でした。
2-0. 例題で使用するデータセット
Table1:

2-1. 【例1】SUMX()を使う意味がない使い方 -テーブル全体を指定して、単一列を集計させる
=SUMX(Table1, Table1[Qty])結果は35。SUM()を使った次の式と同じ。SUMXを使用する必要がない。
=SUM(Table1[Qty])2-2. 【例2】 エラーが出る使い方 -テーブルを指定しないことによるエラー
=SUMX(Table1[Product], Table1[Qty])結果はエラー。Table1[Product]はテーブルではない。リファレンスで確認した通り、SUMX()は最初にパラメータとしてテーブルを指定しなければならない。列を指定してしまったから、エラーが返される。
2-3. 【例3】 エラーが出る使い方 -DISTINCT()で固有の<Product>ごとに他の列を集計しようとしたが、単一列を指定することによるエラー
=SUMX(DISTINCT(Table1[Product]), Table1[Qty])結果はエラー。DISTINCT(Table1[Product])は次のような単一列を返す。

2-4. 【例4】 エラーが出そうで計算できる例 -DISTINCT()で第1パラメータをテーブル指定しなくても計算できてしまう例
//メジャーの定義
[Sum of Qty] = SUM(Table1[Qty])
// 【例4】
=SUMX(DISTINCT(Table1[Product]), [Sum of Qty])結果は35。【例3】はエラーがでるのに、第2パラメータがメジャーになると、計算できてしまう。
計算できる理由を考えるために、そもそもの定義に戻ると、
SUMX()は、第1パラメータの各値について、第2パラメータの式を評価して、それを計算中の合計に追加していく。
この計算式では次の順でSUMX()が処理を行っている。
処理1:SUMXがDISTINCT(Table1[Product])を評価して、重複のない[Product]のリストを生成

処理2:SUMX()は、([Product]列だけではなく)Table1全体をフィルタリングし始める。まず重複のない[Product]のリストの一番目(りんご)で、次のようなテーブルを作成する。

このテーブルに対して、[Sum of Qty]メジャーは、17を返します
処理3、4:SUMX()は、オレンジと洋ナシについても同じ処理を行い、それぞれについて[Sum of Qty]メジャーは、13と5を返す。
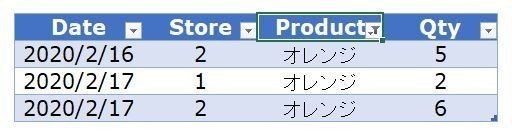

処理5(最後):SUMX()は、[Sum of Qty]メジャーが計算した17と13と5を加算して、35の結果を返す。
2-5. 【例5】汎用性のあるSUMX()の使用例 -組み合わせ(場合の数)を計算する例
//メジャーの定義
[Count of Stores] = COUNTROWS(DISTINCT(Table1[Store]))
// 【例5】
=SUMX(DISTINCT(Table1[Product]), [Count of Stores])結果は5になる。SUMX()の第1パラメータが第2パラメータとしたメジャーが参照する同一テーブル内の行の絞り込みを行った結果。
処理1:先ほどと同様に、SUMX()がDISTINCT(Table1[Product])を評価して、重複のない[Product]のリストを生成
処理2:次に、先ほどと同様に、SUMX()は、([Product]列だけではなく)Table1全体をフィルタリングし始める。まず重複のない[Product]のリストの一番目(りんご)で、次のようなテーブルを作成する。
このテーブルに対して、[Count of Stores]メジャーは、重複のない店舗(の種類の)数を、2と計算して返します。
処理3、4:ここも同様に、SUMX()は、オレンジと洋ナシについても同じフィルタリングを行い、それぞれについて[Count of Stores]メジャーは、2と1を返す。
処理5(最後):SUMX()は、[Count of Stores]メジャーが計算した2と2と1を加算して、5を返す。
2-6. SUMX()は【例3】では集計してくれないのに、【例4】や【例5】では集計してくれる理由は?
SUMX()を使ったメジャーは、そのメジャーの式の中で(第1パラメータで)フィルターを行った結果生まれた2段階目の配列数式を評価できないが(つまり、SUMX()は配列数式で加算していくけど、配列処理後の配列処理はできないということ)、(第2パラメータが)メジャーであれば、メジャーはフィルターに応じて計算できるので、2段階目の配列数式であっても、SUMX()側の機能では追い付かないが、メジャーの発動で計算を実行可能にしている。ということなのだと思う。
3. stack overflowの説明
上記2-6の説明が曖昧なので、別の角度からも、もっとSUMX()は検証されるべき。ということで次のサイトを見た。
3-0. 例題で使用するデータセット
// テーブル名は「Table」
Type Value
A 10
A 10
A 10
B 20
B 20
B 20
C 30
C 30
C 30ちょっと端折りました。。
この投稿者は、Summarize(Tab,[Type],AVG([Value])) と式を作成して、次の結果が欲しい様子
A 10
B 20
C 30
//the final result required from this result set is 10+20+30 i.e. 60.要はType(A,B,C)ごとに、まず平均を出して、その平均を合計したい、という趣旨。(何に使うのかは不明)
3-1. 【例6】SUMX()とSUMMARIZE()を使用して、【例4】のDISTINCT()と同じ効果を実現した例
Sum of Avg =
SUMX (
SUMMARIZE ( Table, [Type], "Total Average", AVERAGE ( Table[Value] ) ),
[Total Average]
)これってすなわち、 【例4】風に書くと、
//メジャーの定義
[Average of Value] = AVERAGE(Table[Value])
// 【例4】
=SUMX(DISTINCT(Table1[Type]), [Average of Value])ってことだと思います。
また例を見つけたら追加していって、帰納的にSUMX()に対する理解を深めたいと思います。
追記
こちらにもSUMX関数の理解に役立つ記事を書きましたので、
併せて読むとこの関数についての理解が深まると思います。