
YOASOBI「アイドル」の音響分析(3): 転調の検出を試みる

「小説を音楽にする」というユニークなコンセプトで注目を集めるユニット、YOASOBI。彼らの楽曲「アイドル」を題材に、Pythonの強力な音楽分析ライブラリLibrosaを使った音響分析の方法を解説します。Librosaは、音楽データからテンポ、リズム、ピッチなど、様々な情報を抽出するためのツールです。
音響分析データを使えば、例えば、YOASOBIの各曲の分類や、お気に入りの曲の機械学習モデルを作成して、ストリーミングから気に入りそうな他の曲をピックアップしたりすることができます。
この記事では、Librosaを用いて「アイドル」の転調に焦点を当てた分析を試みました。曲中でkeyがどのように変化していくのか、音楽の重要な要素をLibrosaでどのように分析できるのかを、具体的なコードと分析結果とともに解説します。
具体的には、以下の2つのステップについて、コードと結果を詳細に解説します。
Chromagramによる時系列でのPitchの可視化
Umapによる転調箇所の推定
なぜYOASOBIの「アイドル」?
「夜に駆ける」以来のYOASOBIのファンだからです。
「アイドル」は2023年に世界的に大ヒットした曲です。
構成が複雑で、転調、テンポチェンジされていたりラップも含まれていますので、音響分析の対象として面白そうです。
譜面つきの演奏動画や、曲の解析記事も多く、音響分析結果と照合することができます。
Librosaとは
Librosaは、データサイエンスに強いプログラミング言語のPythonで使える、音楽信号や音声信号の解析や処理を専門とする強力なライブラリです。音楽や音声の研究、開発において、幅広く利用されています。テンポやキーなどの曲情報やMFCCなどの音声の特徴量を抽出できます。Librosaのdocumentationサイトには、各関数のアルゴリズムに関する論文が引用されていて、アルゴリズムを確認することもできるのでとても安心感があります。
これまで、Librosaを使ってAdoさんとIKURAこと幾田りらさんなどの歌声のMFCC特徴量から学習モデルを作成して、幾田りらさんのような透明感のあるシンガーの探索を楽しんだりもしています。YouTubeやストリーミングサイトなどのレコメンドに満足できない方には、音響分析から自分だけのレコメンドシステム用の様々な小さな学習モデルを作成してみてはいかがでしょうか。
Pythonコードと実行結果
「アイドル」のmp3ファイルはAmazonのデジタルミュージックで購入しました。
プログラミングと実行環境は、Google Colab Proを使っています。Google アカウントでブラウザ上でPythonのコーディングと実行ができるので、PCに依存せずにメモリー容量を拡張したり、GPU/TPUも利用で、機械学習、特に深層学習に適しています。
まずは、今回の分析に必要なPythonライブラリのInstallとImport
Install & Import
# Install
!pip install librosa
!pip install umap-learn
!pip install japanize-matplotlib# Import
import librosa
import librosa.display
import numpy as np
import pandas as pd
import random
import umap
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")筆者は音楽の基礎知識に欠けているので、探りながらになりました。
Librosaには転調を直接検出する関数は無いので、まず時系列でPitchを可視化するLibrosaの関数Chromagramを使います。
Chromagramによる時系列のPitchの可視化
Chromagramは、音楽のPitch(音高)情報を表現する手法の一つです。人間の聴覚は、オクターブ違いの音を同じ音として認識する傾向があります。例えば、ある音とその1オクターブ上の音は、周波数は異なりますが、同じ「ド」の音として認識されます。クロマグラムは、このような人間の聴覚特性を考慮し、音の高さ(音高)を12の音階(半音)に集約して表現します。これにより、異なるオクターブの同じ音を同一視して扱うことが可能になります。
Librosaには、3種のChromagramの関数がありますが、今回は周波数が高くなると分解能が粗くなるという人間の聴覚特性に近い分析ができる 、librosa.feature.chroma_cpt( )
を使いました。
# mp3ファイルの読み込みと chroma_cptの算出
y, sr = librosa.load('アイドル.mp3', sr=None)
chroma_cqt = librosa.feature.chroma_cqt(y=y, sr=sr)
# chroma_cqtをプロット
plt.figure(figsize=(10, 5))
librosa.display.specshow(chroma_cqt, y_axis='chroma', x_axis='s',sr=sr)
plt.colorbar()
plt.title('Chromagram_cqt')
plt.minorticks_on()
plt.tight_layout()
plt.show()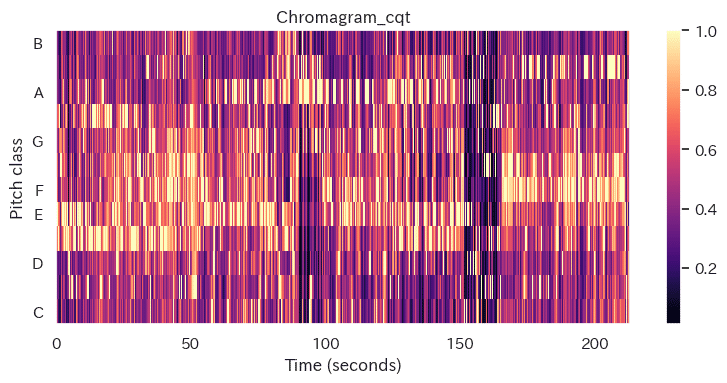
Chromagram_cqtのプロットから主要なPitchが変化していることがわかります。経験を積めばこのプロットから視認でも転調箇所を確認できそうです。
Chromagram_cqtからのUmapによる転調箇所の推定
Chromagram_cqtのプロットからも視認で転調の箇所を推定できそうですが、ここでは10秒ごとの各Pitch classの平均値データでUmapを作成して、転調箇所をおおよそ推定しました。
以下がPythonのコードです。
# chroma_cqtをデータフレームに
chroma_df = pd.DataFrame(chroma_cqt)
# 10秒間の列数を計算
colum_num = chroma_df.shape[1]
duration = librosa.get_duration(y=y, sr=sr)
colum_num//duration * 10
# 10秒ごとの各Pitchの平均値を算出しデータフレームに
start_l =[]
for i in range(21):
#print(i)
start_point = 860*(i)
start_l.append(start_point)
df_av = pd.DataFrame() # Initialize the DataFrame outside the loop
for start_p in start_l:
end_p = start_p + 859
chroma_df_p = chroma_df.iloc[:, start_p:end_p]
new_rows = chroma_df_p.mean(axis=1)
df_av = pd.concat([df_av, new_rows.to_frame().T],
ignore_index=True) # Transpose and append# Umapの作成
title_l = df_av.index.tolist()
color = 'red'
nne = 6
reducer = umap.UMAP(random_state=123, n_neighbors=nne, min_dist=0.02)
reducer.fit(df_av)
sentence_vectors_umap = reducer.transform(df_av)
plt.figure(figsize=(6,6))
for x, y, name in zip(sentence_vectors_umap[:,0],
sentence_vectors_umap[:,1], title_l):
plt.text(x, y, name, c=color, size=10)
plt.scatter(sentence_vectors_umap[:,0],
sentence_vectors_umap[:,1],s=20,)
title = 'UMAP: '+'n_neighbors=' + str(nne) + ' ,mini_dist=0.02'
plt.title(title, fontsize=15)
plt.xlabel("axis1", fontsize=18)
plt.ylabel("axis2", fontsize=18)
plt.show()
Umapは多次元データをデータ間の距離情報をほとんど失うことなく次元を低減することができます。
ここでは各時間間隔の12次元のPitchデータを2次元のUmapプロットで表示しています。
プロットの各ドットの番号は、例えば '0' は0〜10秒のデータを表しています。番号を順にたどって、クラスタリングします。確認にはk-meansを用いています。
クラスタリングした結果が下記のプロットです。
5番から6番の間、すなわち50〜60秒の間で転調していると推定されます。
また同様に、140秒から150秒、160秒から170秒でも転調しているようです。

Umapで推定された転調箇所をChromagram上に記入したのが下記プロットです。55秒あたりで半音上がり、160秒あたりで半音さがり、170秒あたりで全音上がっていると推定しました。

プロット下部の曲の構成は下記YouTubeの中村誠さんのドラム演奏動画の譜面を参考にしています。
あとがき
「アイドル」を聞きながらそのChromagramを追いかけるのも結構楽しいです。
事前に無料版のGemini、PerplexityAIに楽曲の転調を検出するPythonコードを作成させてみましたが、同じくChromagramを使いますが時間単位が短すぎて転調箇所が無数にでて来てしまいました。
今回の記事では、切りの良い10秒ごとの平均値データをUmapでクラスタリングすることで転移箇所がわかりやすくなりました。時間間隔はテンポに応じて調整したほうがより良いでしょう。
また各パートの音階の分析も試みて、強いPitchの抽出やPitch間の相関などを試していますがかなり難しそうです。