
AIエージェントとは何か?超訳

推論や論理、そして外部情報へのアクセスをすべて生成AIモデルに結びつけるこの組み合わせは、「エージェント」という概念を想起させます。
人間は複雑で曖昧なパターン認識タスクが得意ですが、結論に至るまでに、本やGoogle検索、電卓などのツールを使って既存の知識を補うことがよくあります。同様に、生成AIモデルも、リアルタイムの情報へアクセスしたり、現実世界でのアクションを提案したりするためにツールを活用するよう訓練できます。
たとえば、データベース検索ツールを活用して顧客の購買履歴などの特定情報にアクセスし、それをもとにカスタマイズされたショッピングレコメンデーションを生成することが可能です。あるいは、ユーザーの問い合わせ内容に応じて、同僚にメールを送信するAPIコールを行ったり、ユーザーに代わって金融取引を完了させたりすることもできます。
こうした処理を行うには、生成AIモデルが外部ツールへのアクセス権を持つだけでなく、自律的にタスクを計画し、実行できる能力が必要です。
推論や論理、そして外部情報へのアクセスを生成AIモデルにすべて結びつけるこの組み合わせは、「エージェント」という概念、つまり生成AIモデル単体の能力を超えて拡張するプログラムを想起させます。本ホワイトペーパーでは、これらの要素と関連するトピックについて、さらに詳しく掘り下げていきます。
What is an agent?
最も根本的な形で言えば、Generative AI(生成系AI)のエージェントとは、達成すべき目標を定め、その目標に向けて世界を観察し、利用できるツールを駆使して行動を起こすアプリケーションとして定義できます。
エージェントは自律性を備えており、特に適切な目標や目的が与えられている場合には、人間の介入なしに独立して行動が可能です。
また、エージェントは目標達成に向けて能動的なアプローチを取ることができます。たとえ明示的な指示セットが人間から与えられていない場合でも、エージェントは最終的な目標を達成するために次に何をすべきかを推論します。AIにおけるエージェントの概念は非常に一般的かつ強力ですが、本ホワイトペーパーでは、Generative AIモデルが本稿執筆時点で構築できる特定の種類のエージェントに焦点を当てます。
エージェントの内部的な仕組みを理解するには、まずエージェントの行動、アクション、そして意思決定を支える基盤的なコンポーネントを紹介することから始めると良いでしょう。
これらのコンポーネントの組み合わせは「コグニティブ・アーキテクチャ」と呼ばれ、コンポーネントをさまざまに組み合わせることで多様なアーキテクチャを構築できます。コアとなる機能に注目すると、図1に示すように、エージェントのコグニティブ・アーキテクチャには3つの主要なコンポーネントが存在します。

The model
エージェントの文脈において「モデル」とは、エージェントの処理における集中型の意思決定を担う言語モデル(LM)を指します。エージェントで使用されるモデルは、ReAct、Chain-of-Thought、Tree-of-Thoughtsのような指示に基づく推論や論理的フレームワークに対応できるものであれば、小規模から大規模まで、一つでも複数でも構いません。モデルは、汎用的なもの、マルチモーダルなもの、あるいは特定のエージェントアーキテクチャのニーズに応じてファインチューニングされたものなど、さまざまな形態があり得ます。
本番(プロダクション)環境で最良の結果を得るには、目的とするアプリケーションに最も適したモデルを活用し、理想的には、認知アーキテクチャで使用するツールと関連するデータシグネチャで学習されているモデルを選ぶのが望ましいでしょう。ただし、モデルは通常、エージェント特有の構成設定(ツールの選択やオーケストレーション/推論の設定など)を組み込んで学習されているわけではないことに注意が必要です。
しかし、エージェントのタスク向けにモデルをさらに最適化する方法として、エージェントが特定のツールを使ったり、さまざまな文脈で推論ステップを踏んだりする事例を提示して、エージェントの能力を示すサンプルを提供することが可能です。
The tools
エージェントの文脈において「モデル」とは、エージェント・プロセスの中心的な意思決定者として活用される言語モデル(LM)を指します。エージェントで用いられるモデルは、小規模あるいは大規模を問わず、ReActやChain-of-Thought、Tree-of-Thoughtsのような命令に基づいた推論やロジックのフレームワークに対応できる、1つまたは複数のLMとなり得ます。モデルは、汎用的なもの、マルチモーダルなもの、またはエージェント・アーキテクチャの要件に合わせてファインチューニングされたものなど、多様な形態を取り得ます。
本番環境で最適な成果を得るには、望ましいエンドアプリケーションに最も適合し、理想的には使用予定のツールに関連するデータシグネチャを学習しているモデルを活用することが推奨されます。なお、モデルは通常、エージェントの具体的な構成設定(例:ツールの選択やオーケストレーション/推論の設定)を学習した状態にはありません。しかし、エージェントが特定のツールや様々な文脈での推論ステップを使用している事例を提示することで、エージェントのタスクに合わせてモデルをさらに最適化することは可能です。
The orchestration layer
オーケストレーション層は、エージェントがどのように情報を取り込み、内部的な推論を行い、その推論をもとに次のアクションや意思決定を行うかという一連のサイクルを表しています。一般的には、このループはエージェントが目的を達成するか停止条件に到達するまで続きます。
オーケストレーション層の複雑さは、エージェントや実行するタスクによって大きく異なる場合があります。あるループでは単純な決定規則に基づく計算だけで済むこともあれば、連鎖的なロジックを含んだり、追加の機械学習アルゴリズムを組み込んだり、その他の確率的推論技術を実装したりすることもあります。エージェントのオーケストレーション層の詳細な実装については、認知アーキテクチャのセクションでさらに詳しく解説します。
Agents vs. models

「認知アーキテクチャ:エージェントはどのように動作するか」
にぎやかなキッチンで働くシェフを思い浮かべてみてください。
レストランのお客さまに美味しい料理を提供するという目標を達成するため、シェフは計画・実行・修正というサイクルを絶えず回しています。
シェフは、お客さまの注文やパントリーや冷蔵庫に何の食材があるかなどの情報を集めます。
彼らは先ほど集めた情報をもとに、どんな料理や味の組み合わせが作れるかを頭の中であれこれと思案している。
彼らは料理を作るために行動を起こし、野菜を刻み、スパイスを調合し、肉を焼き上げていく。
プロセスの各段階でシェフは、材料が減ったり顧客からのフィードバックがあったりすると、その都度必要に応じて調整を行いながら計画を洗練し、これまでの結果を踏まえて次の行動方針を決定します。
この「情報の取り込み → 計画 → 実行 → 調整」のサイクルは、シェフが目標を達成するために用いる独自の認知アーキテクチャを表しています。
シェフと同様に、エージェントも情報を段階的に処理し、得られた結果に基づいて判断を下し、次のアクションを磨き上げることで最終的な目標を達成できます。エージェントの認知アーキテクチャの中核を担うのが「オーケストレーション層」であり、メモリや状態、推論、計画の管理を担います。このオーケストレーション層は、急速に進化しているプロンプトエンジニアリングと関連するフレームワークを活用して推論や計画を導き出し、エージェントが環境とより効果的にやり取りしながらタスクを完了できるようにします。
プロンプトエンジニアリングのフレームワークや言語モデルのタスク計画に関する研究は急速に発展しており、多彩で有望なアプローチが次々に登場しています。ここで紹介するのはすべてではありませんが、執筆時点で特に注目されているフレームワークや推論手法の一部です。
ReActは、インコンテキストの例があってもなくても、言語モデルがユーザーの問い合わせに対して「推論し、行動を起こす」ための思考プロセス戦略を提供するプロンプトエンジニアリングのフレームワークです。ReActによるプロンプトは、いくつかの最先端(SOTA)ベースラインを上回る性能を示し、人間との相互運用性やLLMの信頼性を高めることが報告されています。
Chain-of-Thought (CoT) は、中間ステップを通じて推論能力を実現するプロンプトエンジニアリングのフレームワークです。self-consistency、active-prompt、multimodal CoT など、複数のサブテクニックが存在し、具体的な用途に応じてそれぞれに長所と短所があります。
Tree-of-thoughts (ToT)は、探索や戦略的な先読みが求められるタスクに適したプロンプトエンジニアリングのフレームワークです。ToT は Chain-of-Thought によるプロンプトを一般化したもので、言語モデルを使った汎用的な問題解決のために、中間的な思考プロセスを複数の枝として探索できるようにします。
エージェントは、上記の推論手法のいずれか、または他のさまざまな手法を利用して、与えられたユーザーリクエストに対する最適な次のアクションを選択できます。たとえば、ReAct フレームワークを用いてユーザーの問い合わせに応じた適切なアクションやツールを選択するようにプログラムされたエージェントを考えてみましょう。
イベントの流れは、だいたい次のようになります。
ユーザーがエージェントに問い合わせを送る
エージェントが ReAct のシーケンスを開始する
エージェントはモデルにプロンプトを与え、次の ReAct ステップとその出力を生成するよう求める。具体的には以下の要素が含まれる:
Question: ユーザーから送られた問い合わせの質問
Thought: モデルが次に何をすべきかを考える思考プロセス
Action: モデルが次に取るアクションを決定する部分
ここでツールの選択を行う場合がある
例としてアクションは [Flights, Search, Code, None] などが考えられ、最初の 3 つはモデルが選択できる既知のツールを表し、最後の “None” は「ツールを使用しない」ことを意味する
Action input: ツールに与える入力を決める(ツールを使う場合)
Observation: Action / Action input の結果
この「Thought / Action / Action input / Observation」は、必要に応じて何度でも繰り返される
Final answer: 元のユーザーからの問い合わせに対して出す最終的な回答
ReAct のループが終了し、最終的な回答がユーザーに返される

図 2 に示すように、モデル、ツール、そしてエージェントの構成が連携して、ユーザーの元の問い合わせに基づいた確かな情報に根差した、簡潔な応答を提供します。モデルは過去の知識に基づいて答えを推測(いわゆる「幻覚」)することもできましたが、実際には「Flights」というツールを用いてリアルタイムの外部情報を検索しました。この追加情報がモデルに与えられることで、現実の事実データに基づいてより適切な判断を下し、それを要約してユーザーに返すことができるようになっています。
まとめると、エージェントの応答の品質は、これら多様なタスクに対してモデルが推論し行動できる能力、特に適切なツールを選択する能力やそのツールの定義の精度に直接影響されます。ちょうど、シェフが新鮮な食材を使いながら顧客のフィードバックを取り入れて料理を仕上げるように、エージェントも正確な推論と信頼できる情報に依存して最適な結果を出すのです。次のセクションでは、エージェントが新しいデータとどのように連携するかについて詳しく見ていきましょう。
ツール:外部世界への鍵
言語モデルは情報の処理に優れている一方で、現実世界を直接感知したり、影響を与えたりする能力には欠けています。そのため、外部システムやデータとのやり取りが必要な状況では、言語モデルの有用性が制限されてしまいます。つまり、ある意味では、言語モデルは学習データから得た知識の範囲でしか機能しません。どれほど大量のデータを学習させても、モデルには依然として外部世界とリアルタイムで相互作用するための根本的な能力が欠けているのです。
では、モデルがリアルタイムかつ文脈を理解したうえで外部システムとやり取りするにはどうすればよいのでしょうか。そのための手段として、Functions、Extensions、Data Stores、そして Plugins といった仕組みが考えられます。
呼び方はさまざまですが、ツールとは基盤となるモデルと外部世界をつなぐリンクのことを指します。このリンクを通じてエージェントは、より広範なタスクを、より正確かつ信頼性の高い方法で実行できるようになります。たとえばツールを使えば、エージェントがスマートホームの設定を変更したり、カレンダーを更新したり、データベースからユーザー情報を取得したり、特定の指示に応じてメールを送信したりすることが可能です。
本稿の執筆時点で、Google のモデルが連携できる主なツールは、Extensions、Functions、そして Data Stores の 3 種類です。エージェントにこれらのツールを持たせることで、世界を「理解」するだけでなく、実際に「行動」することも可能になり、多様な新しいアプリケーションや可能性が大きく広がります。
Extensions
Extensions は、エージェントと API を標準化された方法でつなげる「橋渡し」のような役割を果たし、API の実装方式に依存することなくシームレスにエージェントから API を呼び出せるようにする仕組みです。たとえば、ユーザーがフライトを予約できるようにサポートするエージェントを作ろうとしているとします。このとき、フライト情報を取得するために Google Flights API を使いたいと考えていても、エージェントがどうやってその API エンドポイントを呼び出せるようにするか悩んでいるかもしれません。

ひとつの方法としては、カスタムコードを実装して、受け取ったユーザーからの問い合わせを解析し、必要な情報を抽出してから API を呼び出す、というやり方が考えられます。たとえば、フライト予約のケースでユーザーが「オースティン発チューリッヒ行きのフライトを予約したい」と言った場合、このカスタムコードは「オースティン」と「チューリッヒ」を問い合わせから取り出して API を呼び出すわけです。
しかし、もしユーザーが「チューリッヒ行きのフライトを予約したい」と言うだけで、出発地を指定しなかったらどうでしょうか。必要なデータが不足しているために API 呼び出しは失敗しますし、こうしたエッジケースやコーナーケースを処理するために、さらにコードを追加しなければなりません。こうしたアプローチは拡張性が低く、実装したカスタムコードの想定範囲外のシナリオが出てきたときには簡単に破綻してしまう可能性があります。
より堅牢なアプローチとしての Extension
これまで述べたようなカスタムコードに代わって、より堅牢な方法としてExtension(拡張機能)を利用するという手段があります。Extension は、エージェントと API の間を橋渡しするもので、主に次の役割を担います。:
例示を使って、エージェントにAPIエンドポイントの使い方を教える
例示を使って、エージェントにAPIエンドポイントの使い方を教える

Extension はエージェントとは独立して作成できますが、エージェントの構成の一部として提供される必要があります。エージェントは実行時にモデルやサンプルを参照し、ユーザーの問い合わせを解決するのに最適な Extension があるかどうかを判断します。ここで重要なのは、Extension が持つ「組み込みの例示」の仕組みにより、エージェントが動的に最適な Extension を選択できる点です。

この仕組みは、ソフトウェア開発者がユーザーの問題を解決する際に、どの API エンドポイントを利用するか選ぶ過程によく似ています。たとえばユーザーがフライトを予約したい場合は Google Flights API を使い、ユーザーが自分の現在地から最寄りのコーヒーショップを知りたい場合は Google Maps API を使う、といった具合です。
同じように、エージェント/モデルのスタックも、登録された複数の Extension の中から、ユーザーの問い合わせに最も合ったものを選びます。Extension の実際の動作を確かめてみたい場合は、Gemini アプリケーションの「Settings > Extensions」から任意の Extension を有効にして試してみることができます。たとえば、Google Flights の Extension を有効にした状態で、「来週の金曜日にオースティン発チューリッヒ行きのフライトを教えて」と Gemini に問い合わせてみてください。
サンプル Extensions
# ================================
# Vertex AI でコードインタープリター機能を用いた例
# ================================
import vertexai
import pprint
# -------------------------------
# 1. プロジェクト設定
# -------------------------------
PROJECT_ID = "YOUR_PROJECT_ID" # あなたのプロジェクトIDを指定
REGION = "us-central1" # 適切なリージョンを指定
# -------------------------------
# 2. Vertex AIの初期化
# -------------------------------
vertexai.init(project=PROJECT_ID, location=REGION)
# -------------------------------
# 3. 拡張機能(Extension)のインポートと読み込み
# -------------------------------
from vertexai.preview.extensions import Extension
# "code_interpreter" 拡張を Code Hub からロード
extension_code_interpreter = Extension.from_hub("code_interpreter")
# -------------------------------
# 4. コード生成のためのクエリ(質問文)定義
# -------------------------------
# 今回は「二分木を O(n) 時間で反転する Python メソッド」の実装例を生成させたい
CODE_QUERY = """Write a python method to invert a binary tree in O(n) time."""
# -------------------------------
# 5. 拡張機能を使ってコードを生成・実行
# -------------------------------
response = extension_code_interpreter.execute(
operation_id="generate_and_execute",
operation_params={"query": CODE_QUERY}
)
# -------------------------------
# 6. 生成されたコードの出力
# -------------------------------
print("Generated Code:")
pprint.pprint({response['generated_code']})
# ================================================================
# 以下は上記で生成されたコードの例と、その日本語コメント付き解説です
# ================================================================
# 二分木を表すノードのクラス
class TreeNode:
def __init__(self, val=0, left=None, right=None):
"""
val: ノードが保持する値
left: 左の子ノード
right: 右の子ノード
"""
self.val = val
self.left = left
self.right = right
def invert_binary_tree(root):
"""
二分木を反転させる関数。
引数:
root: 二分木のルートノード
戻り値:
反転された二分木のルートノード
処理の流れ:
1. ノードがNoneなら、そこで処理を打ち切ってNoneを返す。
2. root.rightとroot.leftを再帰的に反転したものを入れ替える。
3. 最終的にrootを返す。
"""
# もしノードが存在しなければ None を返す
if not root:
return None
# 右の子ノードを左に、左の子ノードを右に再帰的に割り当てる
root.left, root.right = invert_binary_tree(root.right), invert_binary_tree(root.left)
return root
# -------------------------------
# 使用例: 二分木を構築して反転させるデモ
# -------------------------------
# 以下の木を例として考える:
# 4
# / \
# 2 7
# / \ / \
# 1 3 6 9
#
# これを反転すると左右が入れ替わり、
# 4
# / \
# 7 2
# / \ / \
# 9 6 3 1
# という構造の木に変わる。
# サンプルの二分木を構築
root = TreeNode(4)
root.left = TreeNode(2)
root.right = TreeNode(7)
root.left.left = TreeNode(1)
root.left.right = TreeNode(3)
root.right.left = TreeNode(6)
root.right.right = TreeNode(9)
# 二分木を反転
inverted_root = invert_binary_tree(root)
スニペット 1. Code Interpreter Extension は Python コードを生成して実行できます。
まとめると、Extensions を活用することで、エージェントが多様な方法で外部の世界を知覚し、やり取りし、影響を与えられるようになります。これらの Extensions の選択や呼び出しは、Extension の設定に含まれる Examples を用いて指示されます。
Functions
ソフトウェアエンジニアリングの世界では、関数は特定のタスクを実行するために自己完結したコードのモジュールとして定義され、必要に応じて再利用できます。プログラミングを行う際、ソフトウェア開発者はさまざまなタスクを処理するために多くの関数を作成します。そして、function_a と function_b のどちらをいつ呼び出すか、その入出力がどうあるべきかといったロジックを定義します。
エージェントの世界でも関数の働きはほぼ同じですが、ここではソフトウェア開発者の代わりに「モデル」が存在します。モデルは、あらかじめ定義された一連の関数を使い、仕様に基づいて「いつ」「どの関数」を使うか、引数として何を与えるかを判断します。関数と Extensions にはいくつかの違いがありますが、中でも代表的なものは以下のとおりです。
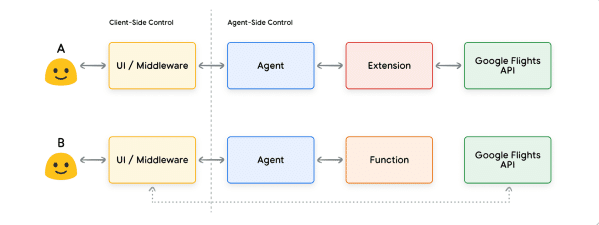
モデルは関数とその引数を出力するものの、実際の API 呼び出しは行わない。
関数はクライアント側で実行されるのに対し、Extensions はエージェント側で実行される。
再び Google Flights の例を用いると、関数のシンプルなセットアップは図 7 に示すようになります

ここでの大きな違いは、Function もエージェントも Google Flights API と直接やり取りしないという点です。では、実際の API 呼び出しはどのように行われるのでしょう
Functions では、実際の API エンドポイントの呼び出しに関するロジックと実行が、エージェント側ではなくクライアント側のアプリケーションにオフロードされます(図 8 と図 9 を参照)。この方法により、開発者はアプリケーション内のデータフローをより細かく制御できるようになります。
Extensions よりも Functions を利用する理由はさまざまですが、よくあるユースケースとしては次のような例があります。
エージェントのアーキテクチャフローの外側(ミドルウェアやフロントエンドなど)で API を呼び出す必要がある。
セキュリティや認証上の制約で、エージェントから直接 API を呼び出せない(たとえば、API がインターネットに公開されていない、またはエージェントのインフラからアクセス不可)。
処理のタイミングや手順の都合で、エージェントがリアルタイムに API を呼び出せない(バッチ処理や人間によるレビューが必要など)。
エージェントが実行できない追加のデータ変換ロジックを API レスポンスに適用する必要がある。たとえば、返却される結果の件数を制限するためのフィルター機構がない API エンドポイントに対して、クライアント側で変換処理を行えるようにしておく、など。
エージェントの開発を進めるにあたって、API エンドポイント用の追加インフラをデプロイせずに進めたい(Function Calling は “API のスタブ化” としての役割を果たせる)。
図 8 に示すように、この 2 つのアプローチの内部アーキテクチャの違いはごくわずかですが、外部 インフラへの依存が切り離され、かつデータを細かく制御できることから、開発者にとっては Function Calling が魅力的なオプションになる場合があります。
ユースケース
モデルは、エンドユーザー向けの複雑なクライアント側の実行フローを扱うために、関数を呼び出す目的で利用できます。エージェント開発者が、API の実行(Extensions の場合のように)を言語モデルに任せたくない場合に適しています。
たとえば、旅行コンシェルジュとして機能するエージェントを想定し、バカンスを予約したいユーザーとやり取りするケースを考えてみましょう。
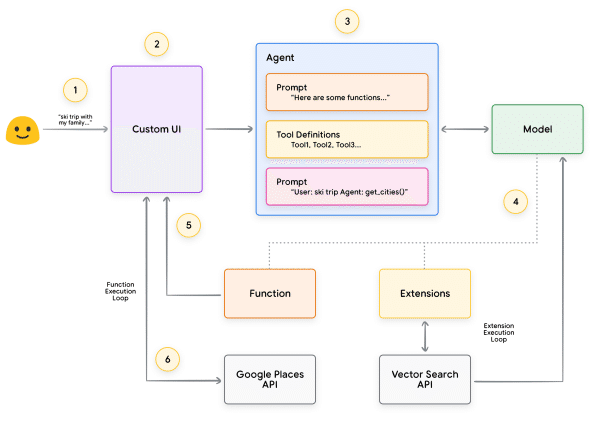
目標は、エージェントに都市のリストを提示させ、そのリストをミドルウェアのアプリケーション側で画像やデータなどを取得する際に活用することです。
ユーザーが次のように言ったとします。
「家族でスキー旅行に行きたいんだけど、どこに行けばいいか分からなくて。」
一般的なプロンプトをモデルに与えた場合、出力例としては次のようになるかもしれません。
「家族でスキーを楽しめる都市の候補はこちらです:
・アメリカ・コロラド州のクレステッドビュート
・カナダ・ブリティッシュコロンビア州のウィスラー
・スイス・ツェルマット」
上記のような出力は、必要な都市名の情報を含んでいますが、他のシステムで解析するにはフォーマットがあまり望ましくありません。
Function Calling を使うと、モデルに出力を JSON などの構造化された形式で返すように指示でき、別のシステムでより扱いやすくなります。同じユーザーからのプロンプトに対して、Function が返す JSON のサンプルはスニペット 5 のようになる場合があります。
function_call {
name: "display_cities"
args: {
"cities": ["Crested Butte", "Whistler", "Zermatt"],
"preferences": "skiing"
}
} スニペット 5. 都市リストとユーザーの好みを表示するための Function 呼び出しペイロード例
この JSON ペイロードはモデルによって生成され、クライアント側のサーバーへ送られます。その後、クライアント側で自由に処理することができます。たとえばこのケースでは、モデルが返した都市名を使って Google Places API を呼び出し、画像を取得して、整形したリッチコンテンツとしてユーザーに返すことが可能です。図 9 は、こうした一連のやり取りをステップごとに示したシーケンス図です。

図 9 の例においては、モデルが必要なパラメータを埋め込み、クライアント側の UI がそのパラメータを使って Google Places API を呼び出す形になっています。クライアント側の UI は、モデルから返された Function のパラメータを使って実際の API 呼び出しを行います。これは Function Calling のひとつの利用例にすぎませんが、他にも次のようにさまざまなシナリオが考えられます。
言語モデルにコード内で使える関数を提案させたいが、コードに認証情報を含めたくない場合。Function Calling では関数自体は実行されないため、関数情報とあわせて認証情報をコードに含める必要がありません。
非同期の操作を行う必要があり、数秒以上の時間がかかる場合。Function Calling は非同期処理として機能するため、このようなケースに向いています。
関数を実行するデバイスが、Function の呼び出しや引数を生成しているシステムとは異なる場合。
関数について覚えておくべき重要な点は、API 呼び出しの実行だけでなく、アプリケーション全体のデータフローに対して、開発者がより細かいコントロールを行えるように設計されているということです。図 9 の例では、開発者はエージェントの今後の動作に不要だと判断し、API から得た情報をエージェントに返しませんでした。
しかし、アプリケーションのアーキテクチャによっては、今後の推論やロジック、アクションの選択に影響を与えるために、外部 API で取得したデータをエージェントに返す方が望ましい場合もあります。最終的には、各アプリケーションにとって最適な方法を選択するのは開発者次第です。
関数のサンプルコード
上記のスキー旅行シナリオで示したような出力を得るために、Gemini バージョン 1.5-flash-001 のモデルを使って必要なコンポーネントを組み立ててみましょう。
まず、display_cities 関数をシンプルな Python メソッドとして定義します。
次に、モデルをインスタンス化し、ツールを構築して、ユーザーのクエリとツールをモデルに渡します。以下のコードを実行すると、スニペットの最後に示すような出力が得られます。
from typing import Optional
def display_cities(cities: list[str], preferences: Optional[str] = None):
"""
ユーザーの検索クエリおよび嗜好に基づいて都市のリストを提供する関数。
引数:
cities (list[str]): ユーザーに推奨する都市のリスト
preferences (str, オプション):
スキーやビーチ、レストラン、BBQ など、ユーザーが希望する嗜好情報
戻り値:
list[str]: ユーザーにおすすめする都市のリスト
"""
# シンプルに、渡された都市のリストをそのまま返す
return cities
スニペット 6. 都市のリストを表示するための関数を実装した Python メソッドの例。
次に、モデルをインスタンス化してツールを構築し、ユーザーのクエリとツールをモデルに渡します。以下のコードを実行すると、スニペットの末尾に示すような出力が得られます。
# ===================================
# Vertex AI の GenerativeModel を使って、
# 自然言語から関数呼び出し情報を生成するデモ
# ===================================
from vertexai.generative_models import GenerativeModel, Tool, FunctionDeclaration
# 1. GenerativeModel のインスタンスを生成
# "gemini-1.5-flash-001" はモデルの名称
model = GenerativeModel("gemini-1.5-flash-001")
# 2. 呼び出す予定の関数を FunctionDeclaration に変換
# display_cities は、ユーザーの嗜好に応じて都市を表示する関数(以前の例で定義)
display_cities_function = FunctionDeclaration.from_func(display_cities)
# 3. Tool オブジェクトを作成し、上記の関数宣言を登録
tool = Tool(function_declarations=[display_cities_function])
# 4. ユーザーからのメッセージ(自然言語)
message = "I’d like to take a ski trip with my family but I’m not sure where to go."
# 5. モデルにメッセージを与え、必要に応じて上記ツール(display_cities_function)を使うよう指示
res = model.generate_content(message, tools=[tool])
# 6. 結果を出力
# 生成された情報から、どの関数が呼び出されたかと、引数として何が推定されたかを表示
print(f"Function Name: {res.candidates[0].content.parts[0].function_call.name}")
print(f"Function Args: {res.candidates[0].content.parts[0].function_call.args}")
# 実行結果の例:
# Function Name: display_cities
# Function Args: {'preferences': 'skiing', 'cities': ['Aspen', 'Vail', 'Park City']}
スニペット 7. ツールを構築してユーザーのクエリをモデルに渡し、Function Call を行う例
要約すると、Functions はアプリケーション開発者に対し、データフローやシステム実行を細かく制御するためのシンプルなフレームワークを提供すると同時に、エージェント/モデルを重要なインプット生成に有効活用する手段を与えます。開発者は外部データをエージェントに返すことで「ループに残す」か、あるいはアプリケーションのアーキテクチャによって必要がなければ返さない、といった選択を柔軟に行えます。
Data Store
言語モデルを膨大な蔵書を持つ図書館にたとえると、学習データという「本」が大量に詰まっている状態です。しかし、通常の図書館が新しい本を次々と入手して内容を更新するのに対し、この図書館(言語モデル)は学習時点の知識に固定されてしまいます。現実世界の情報が常に変化し続けることを考えると、これは大きな課題となります。Data Store は、より動的かつ最新の情報へアクセスできるようにすることで、この制約を克服し、モデルの回答を実際の事実や関連性に基づいたものに保ちます。

Data Store を使うと、開発者は追加データを元の形式のままエージェントに提供できます。これにより、時間のかかるデータ変換やモデルの再学習、ファインチューニングなどが不要です。Data Store は受け取ったドキュメントをベクトルデータベース用の埋め込み(ベクトル表現)に変換し、エージェントが次のアクションやユーザーへの回答を補足するために必要な情報を取り出せるようにします。

実装と応用
Generative AI エージェントの文脈でいう Data Store は、開発者が実行時にエージェントにアクセスさせたいベクトルデータベースとして実装されることが多いです。ベクトルデータベースの詳細はここでは扱いませんが、要点はデータをベクトル埋め込みという高次元ベクトル(または数学的表現)として保存する点です。
近年、言語モデルにおける Data Store 利用の代表的な例として、RAG(Retrieval Augmented Generation)ベースのアプリケーションが挙げられます。RAG アプリケーションでは、Web サイトのコンテンツや PDF、Word、CSV、スプレッドシートといった形式の構造化/非構造化データをモデルから参照できるようにすることで、基盤となる学習データを超えた幅広い知識をモデルに提供します。
ウェブサイトのコンテンツ
PDF、Word、CSV、スプレッドシートなどの構造化データ
HTML、PDF、TXT などの非構造化データ

ユーザーからのリクエストとエージェントの応答ループの基本的な流れは、図 13 のようにモデル化されます。
ユーザーの問い合わせを埋め込みモデルに送信し、ベクトル埋め込みを生成する
この問い合わせの埋め込みを、SCaNN などのマッチングアルゴリズムを使ってベクトルデータベースの内容と照合する
照合結果として一致したコンテンツがテキスト形式でベクトルデータベースから取得され、エージェントに返される
エージェントはユーザーの問い合わせと取得したコンテンツの両方を受け取り、回答またはアクションを生成する
最終的な回答がユーザーに返される

最終的に完成するアプリケーションでは、エージェントがベクトル検索を用いてユーザーの問い合わせを既知のデータストアに照合し、元のコンテンツを取得してオーケストレーション層およびモデルに渡し、さらに処理を行うことができます。続いてエージェントがユーザーに最終回答を返したり、結果をさらに絞り込むために追加のベクトル検索を行うなど、次のアクションを選択することも可能です。
ReAct を使った推論・プランニングを RAG と組み合わせたエージェントとのやり取りの例として、図 14 をご覧ください。

ツールのおさらい
まとめると、Extensions、Functions、Data Stores は、エージェントが実行時に利用できるツールの一部であり、それぞれに異なる目的があります。エージェント開発者の判断により、これらを組み合わせたり、単独で使ったりできます。

ターゲットを絞った学習によるモデル性能の向上
モデルを効果的に活用するうえで重要になるのが、「大量のツールを運用する際に、モデルが適切にツールを選びながら出力を生成する能力」です。汎用的なトレーニングによってモデルはこのスキルを身につけますが、現実世界のシナリオでは学習データを超えた知識が必要になることが多々あります。これは、基本的な料理技術と特定の料理分野の専門性の違いに似ています。どちらにも料理の基礎知識は必要ですが、後者はより高度で特定分野にフォーカスした学習を要します。
こうした、より専門的な知識やスキルをモデルに習得させる手段として、以下のアプローチがあります。
In-context Learning
一般的なモデルに対して、推論(推定)時にプロンプトやツール、少数の例(few-shot examples)を与え、その場で「いつ・どのツールを使うべきか」を学習させる手法です。ReAct フレームワークは、このアプローチを自然言語で実現する例といえます。
Retrieval-based In-context Learning
外部メモリから最適な情報やツール、関連する例示を動的に取得(リトリーブ)してプロンプトに組み込み、モデルがその場で活用できるようにする手法です。Vertex AI Extensions の “Example Store” や、先述の Data Stores を用いた RAG(Retrieval Augmented Generation)型のアーキテクチャがその一例です。
Fine-tuning based Learning
ユーザーからの問い合わせを受ける前に、特定の分野に関する大量の学習データを使ってモデルを再学習し、特定のツールを「いつ・どのように使うか」をあらかじめ学習させる方法です。
この 3 つの学習アプローチについて、再度料理のアナロジーで説明してみましょう。
In-context Learning
シェフが特定のレシピ(プロンプト)と、いくつかの重要な食材(ツール)、そして少数の例示(few-shot examples)を顧客から受け取ったと考えてください。シェフは一般的な料理の知識を活かして、その限られた情報をもとに、即興でレシピと顧客の好みに合う料理を作り上げます。Retrieval-based In-context Learning
シェフが豊富な食材やレシピ本(例示やツール)が詰まったパントリー(外部データストア)を持っているとします。シェフは必要に応じてそれらを取り出し、新旧の知識を組み合わせることで、より充実した料理を作れます。Fine-tuning based Learning
シェフを専門学校に再度通わせ、新たな料理ジャンルを学ばせるイメージです(特定のデータセットで再トレーニングする)。これにより、シェフは将来の新しい顧客の注文に対して、より深い理解と専門性を発揮できるようになります。特定分野でのスキルを高めたい場合に適した方法です。
これらのアプローチはいずれも、速度、コスト、レイテンシーなどの観点でそれぞれ利点と欠点があります。しかし、エージェントのフレームワークにこれらを組み合わせることで、それぞれの強みを生かし欠点を補い合う、より強力で柔軟なソリューションが得られます。
LangChain を使ったエージェントのクイックスタート
実際に動作するエージェントの例を示すために、オープンソースの LangChain と LangGraph ライブラリを使って簡易プロトタイプを作ってみましょう。これらのライブラリは、ユーザーのクエリに答えるために、一連のロジックや推論、ツール呼び出しを「チェーン」状につなぎ合わせることで、カスタムエージェントを構築できるようにしています。
ここでは gemini-1.5-flash-001 モデルと、シンプルなツールをいくつか使って、ユーザーからの複数ステップにわたるクエリに応答する例(スニペット 8)を見ていきます。
今回使うツールは SerpAPI(Google Search 用)と Google Places API です。スニペット 8 のプログラムを実行すると、スニペット 9 に示すサンプル出力が得られます。
import os
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool
from langchain_community.utilities import SerpAPIWrapper
from langchain_community.tools import GooglePlacesTool
from langchain.chat_models import ChatVertexAI
# SerpAPI と Google Places API のキーを環境変数として設定
os.environ["SERPAPI_API_KEY"] = "XXXXX" # あなたの SERPAPI_API_KEY を入力
os.environ["GPLACES_API_KEY"] = "XXXXX" # あなたの GPLACES_API_KEY を入力
@tool
def search(query: str):
"""
Google Search を行うために SerpAPI を使用するツール。
引数:
query (str): 検索クエリ
戻り値:
str: 検索結果
"""
# SerpAPIWrapper を使ってクエリを実行
search = SerpAPIWrapper()
return search.run(query)
@tool
def places(query: str):
"""
Google Places API を使って検索を行うツール。
引数:
query (str): 検索クエリ
戻り値:
str: Google Places API の検索結果
"""
# GooglePlacesTool を使ってクエリを実行
places = GooglePlacesTool()
return places.run(query)
# モデルとして ChatVertexAI を選択し、"gemini-1.5-flash-001" を指定
model = ChatVertexAI(model="gemini-1.5-flash-001")
# 利用するツールをリストアップ
tools = [search, places]
# エージェントに与える質問(クエリ)
query = "Who did the Texas Longhorns play in football last week? What is the address of the other team's stadium?"
# create_react_agent を使ってエージェントを作成
agent = create_react_agent(model, tools)
# エージェントに入力を渡す (messages は (role, content) のタプルで構成)
input_data = {"messages": [("human", query)]}
# stream_mode="values" によって、受け取ったレスポンスをストリームで逐次出力
for s in agent.stream(input_data, stream_mode="values"):
message = s["messages"][-1] # 最新のメッセージを取得
if isinstance(message, tuple):
# メッセージが (role, content) の形式なら、そのまま表示
print(message)
else
スニペット 8. LangChain と LangGraph を使い、ツールを組み合わせたエージェントのサンプル
========================
他チームのスタジアムの住所は===============================
ユーザーからのメッセージ (Human Message)
===============================
先週、テキサス・ロングホーンズはフットボールでどこと対戦しましたか?
その相手チームのスタジアムの住所はどこですか?
================================= AI からのメッセージ (Ai Message)
=================================
ツール呼び出し: search
引数:
query: "Texas Longhorns football schedule"
================================ ツールからのメッセージ (Tool Message)
===============================
ツール名: search
{...結果例: "NCAA Division I Football, Georgia, Date..."}
(検索結果の詳細がここに入る想定)
================================= AI からのメッセージ (Ai Message)
=================================
テキサス・ロングホーンズは先週、ジョージア・ブルドッグスと対戦しました。
ツール呼び出し: places
引数:
query: "Georgia Bulldogs stadium"
================================ ツールからのメッセージ (Tool Message)
===============================
ツール名: places
{...Sanford Stadium Address: 100 Sanford...}
(Google Places からの検索結果の詳細がここに入る想定)
================================= AI からのメッセージ (Ai Message)
==========
ジョージア・ブルドッグスのスタジアムの住所は、100 Sanford Dr, Athens, GA 30602, USA です。
スニペット 9. スニペット 8 のプログラム出力例
このエージェントの例は比較的シンプルですが、モデル・オーケストレーション・ツールといった基盤となる要素が連携して、特定の目標を達成する様子を示しています。最後のセクションでは、こうした要素が Vertex AI Agents や Generative Playbooksといった Google 規模のマネージド製品においてどのように組み合わさるのかを見ていきましょう。
Vertex AI Agents を使った本番アプリケーション
本ホワイトペーパーではエージェントの主要コンポーネントを紹介してきましたが、実際に本番環境レベルのアプリケーションを構築するには、ユーザーインターフェースや評価フレームワーク、継続的な改善メカニズムなど、追加のツールを統合する必要があります。Google の Vertex AI プラットフォームは、これらの基本要素をすべて含む、フルマネージドな環境を提供することで、このプロセスを簡素化します。
開発者は自然言語インターフェースを用いて、エージェントの目標、タスクの指示、ツール、タスクを委任するサブエージェント、そして例示(Examples)といった重要要素を素早く定義し、求めるシステム動作を簡単に構築できます。さらに、このプラットフォームには一連の開発ツールが備わっており、テストや評価、エージェントのパフォーマンス計測、デバッグ、品質改善などを実行可能です。これにより、インフラやデプロイ、メンテナンスといった複雑な部分をプラットフォームが管理するため、開発者はエージェントの構築と改良に集中できます。
図 15 では、Vertex Agent Builder、Vertex Extensions、Vertex Function Calling、Vertex Example Store といった機能を活用して Vertex AI プラットフォーム上で構築されたエージェントのサンプルアーキテクチャを示しています。このアーキテクチャには、本番アプリケーションに必要となるさまざまなコンポーネントが含まれています。
この事前構築されたエージェントアーキテクチャのサンプルは、公式ドキュメントで試すことができます。
まとめ
本ホワイトペーパーでは、Generative AI エージェントの基盤となる構成要素、それらの組み合わせ方、そして認知アーキテクチャとして実装する方法について解説しました。主なポイントは以下のとおりです。
エージェントはツールを活用することで言語モデルの能力を拡張し、リアルタイム情報へのアクセス、現実世界でのアクション提案、複雑なタスクの自律的な計画・実行を可能にします。
エージェントは、複数の言語モデルを連携させることで、いつ・どのように状態遷移を行い、外部ツールを使ってモデル単体では難しい(あるいは不可能な)タスクをこなすかを判断できます。エージェントの中心となるのはオーケストレーション層であり、推論・計画・意思決定を構造化し、エージェントのアクションを導きます。
ReAct や Chain-of-Thought、Tree-of-Thoughts といった多様な推論手法によって、オーケストレーション層が情報を取り込み、内部で推論し、的確な判断や応答を生成するための枠組みを提供します。Extensions、Functions、Data Stores などのツールは、エージェントにとって外部世界への“鍵”の役割を果たします。
Extensions はエージェントと外部 API をつなぐ架け橋となり、API 呼び出しやリアルタイム情報の取得を可能にします。
Functions は開発者により細かな制御権を与え、モデルが生成する関数パラメータをクライアント側で実行できるようにします。
Data Stores は、エージェントが構造化・非構造化データにアクセスする手段を提供し、データドリブンなアプリケーションを実現します。
今後、エージェントはさらに高度なツールや推論能力の発展とともに、ますます複雑な問題を解決できるようになるでしょう。特に複数の専門特化エージェントを組み合わせる「エージェントチェイニング」によるアプローチは、さまざまな分野や課題に対応できる“エージェントの専門家集団”を作り出す可能性があります。
ただし、複雑なエージェントアーキテクチャの構築には試行錯誤が不可欠です。各組織やビジネスケースごとに適切な解決策を見つけるためには、実験と改良のプロセスが重要となります。エージェントの基盤となる言語モデルが生成的(ジェネレーティブ)である以上、同じように設計されたエージェントでも出力が異なることもあります。しかし、本ホワイトペーパーで紹介した各コンポーネントの強みを組み合わせることで、言語モデルの能力を拡張し、現実世界で価値を生み出すアプリケーションを構築できるようになるでしょう。
Endnotes
1. Shafran, I., Cao, Y. et al., 2022, 'ReAct: Synergizing Reasoning and Acting in Language Models'. Available at: https://arxiv.org/abs/2210.03629
2. Wei, J., Wang, X. et al., 2023, 'Chain-of-Thought Prompting Elicits Reasoning in Large Language Models'. Available at: https://arxiv.org/pdf/2201.11903.pdf.
3. Wang, X. et al., 2022, 'Self-Consistency Improves Chain of Thought Reasoning in Language Models'. Available at: https://arxiv.org/abs/2203.11171.
4. Diao, S. et al., 2023, 'Active Prompting with Chain-of-Thought for Large Language Models'. Available at: https://arxiv.org/pdf/2302.12246.pdf.
5. Zhang, H. et al., 2023, 'Multimodal Chain-of-Thought Reasoning in Language Models'. Available at: https://arxiv.org/abs/2302.00923.
6. Yao, S. et al., 2023, 'Tree of Thoughts: Deliberate Problem Solving with Large Language Models'. Available at: https://arxiv.org/abs/2305.10601.
7. Long, X., 2023, 'Large Language Model Guided Tree-of-Thought'. Available at:
https://arxiv.org/abs/2305.08291.
8. Google. 'Google Gemini Application'. Available at: http://gemini.google.com.
9. Swagger. 'OpenAPI Specification'. Available at: https://swagger.io/specification/.
10. Xie, M., 2022, 'How does in-context learning work? A framework for understanding the differences from traditional supervised learning'. Available at: https://ai.stanford.edu/blog/understanding-incontext/.
11. Google Research. 'ScaNN (Scalable Nearest Neighbors)'. Available at:
https://github.com/google-research/google-research/tree/master/scann.
12. LangChain. 'LangChain'. Available at: https://python.langchain.com/v0.2/docs/introduction/.
お気軽にご相談ください
RAGを使って業務効率化を実現したい方、新規事業の可能性を探りたい方、まずはRAGのよろず相談会でお話してみませんか?
みなさまの課題やご要望をじっくり伺い、一緒に具体的な進め方を考えていけたらうれしいです。
下記のGoogleフォームからお気軽にご連絡ください!