最もかわいいポケモンは何か Elasticsearch で感情の統計を取る

本記事で記載した Elasticsearch の詳細つきましては以下の記事をご覧ください。
最もかわいいポケモンを決定することが困難な理由
さて、最もかわいいポケモンとはなんでしょうか?真っ先にピカチュウを思い浮べる人もいるでしょう。

たしかにピカチュウはかわいいポケモンです。しかしイーブイのほうがかわいいと言う人もいるでしょう。では全員が納得するような最もかわいいポケモンとは何でしょうか?
最もかわいいポケモンの結論が出ない原因としては、結論を支える最大の根拠が個人の感情だからです。個人の感情は客観的な根拠となり得ないため、人によって導き出す結論が異なります。全ての人が同じ結論を導き出すためには、客観的な根拠を示す必要があります。
どうやって客観的な根拠を示すのか
客観的な根拠として世間の意見を収集し、かわいいと言われるポケモンの統計を示します。
今回は世間の意見に Twitter を使用することにします。
まず、キーワード「かわいい ポケモン」でツイートを検索し、世間の意見を収集します。次に、収集したツイートに含まれるポケモン名の出現回数をカウントし統計を作成します。今回、全てのツイートからポケモン名の出現回数をカウントするためには Elasticsearch の全文検索を使用します。
全文検索エンジンってなんだ?
全文検索とは、複数の文書から特定の文字列を検索することです。有名な例を挙げますと google の検索機能です。google の検索では、複数の文書 (webページ)から特定の文字列 (検索キーワード) を含んだ web ページのみを検索できます。
今回は全文検索機能を持つ Elasticsearch を使用して、複数の文書(収集したツイート)から特定の文字列(各ポケモン名)を検索し、出現回数をカウントすることで統計を作成します。
ツイートから統計を作成するまでの流れ
ツイートから統計を作成するまでの全体の流れを示します。
統計の可視化には Elasticsearch 用のデータ視覚化ダッシュボード 「Kibana」を使用します。

1. Twitter の API を使用して「ポケモン かわいい」を含むツイートを収集します。
2. 収集したツイートの内容を分析するために、Elasticsearch の設定をする。
3. 収集したツイートを Elasticsearch に投入する。
4. 投入したツイートに出現するポケモン名を Elasticsearch の全文検索でカウントし、Kibana を使用して可視化する。
以降では具体的な実装手順を記載します。
実装手順1. Twitter の API を使用して「ポケモン かわいい」を含むツイートを収集します。
まず、Twitter からツイートを収集するために「Standard search API」を使用します。
Standard search API を使用するためには、Twitter API の登録申請をして、API を使用するための認証キーを Twitter 社からもらう必要があります。詳しい登録申請方法は下記のサイトに記載されています。
Twitter API の登録が終わったら、Standard search API を使用して、キーワード「ポケモン かわいい」のツイートを収集します。今回はPython を使用して実装しました。認証キーをハードコーディングしていますが、外部のリソースから取得するようにしたほうがいいですね。
#!/usr/bin/env python3 #python2.x系だと文字コードでエラー吐くから修正してね
#coding: utf-8
import json
import requests
from requests_oauthlib import OAuth1Session
import re
from time import sleep
CONSUMER_KEY = "<Twitter社からもらった値>" ##変更してください
CONSUMER_SECRET_KEY = "<Twitter社からもらった値>" ##変更してください
ACCESS_TOKEN = "<Twitter社からもらった値>" ##変更してください
ACCESS_TOKEN_SECRET = "<Twitter社からもらった値>" ##変更してください
SEARCH_WORD = "ポケモン かわいい"
class TwitterSearchAPI_Elasticsearch():
def __init__(self,searchWord):
self.index = 0
self.searchWord = searchWord
self.params = {
"q": (self.searchWord),
"lang": "ja",
"result_type": "recent",
"max_id": -1,
"exclude":"retweets"
}
def searchTweetToElasticsearch(self):
twitter = OAuth1Session(CONSUMER_KEY,CONSUMER_SECRET_KEY,ACCESS_TOKEN,ACCESS_TOKEN_SECRET)
#while True:
for i in range(1): ##debug
searchAPI_response = twitter.get("https://api.twitter.com/1.1/search/tweets.json", params=self.params)
if searchAPI_response.status_code == 200:
self.json_searchAPI_response = json.loads(searchAPI_response.text)
if len(self.json_searchAPI_response["statuses"]) == 0: ##これ以上収集できるツイートが無い時終了
break
##今回収集した最後のツイートより1つ前のツイートから、次回のループで検索できるようにする
self.params["max_id"] = self.json_searchAPI_response["statuses"][-1]["id"] - 1
else:
print('15分待ちます') ##APIの制限
sleep(15*60)
def run(self):
self.searchTweetToElasticsearch()
if __name__ == '__main__':
TwitterSearchAPI_Elasticsearch(SEARCH_WORD).run()ライブラリが足りず実行できない場合は、下記のコマンドでライブラリをインストールします。
python -m pip install --target=./ <ライブラリ名>実行するとこんな感じでツイートを収集できます。
------------
Wed Dec 11 13:03:42 +0000 2019
モルペコかわいいな…おなかがすくとぷんすかモードになるのか…たらふく食わせてやりたいねポケモン
------------
Wed Dec 11 13:02:59 +0000 2019
@***** めちゃくさポケモンだ!!!!!!!!!!かわいい!!!!!ぽぽっこわたっこすき!!!!ラフレシアもすき!!!ニョロトノは可愛くないけど混ぜてあげよう…っ
------------
実装手順2. 収集したツイートを分析するために、Elasticsearch の設定をする。
今回 Elasticsearch を設定するにあたって、知っておく必要がある用語は下記の6つです。
- ドキュメント
- インデックス
- テンプレート
- マッピング
- フィールド
- Analyzer
わからない用語がある場合(Elasticsearch が初めての場合)は下記の素晴らしい記事を見てください。
ちなみに私のようにデータベースに疎い方は、上記の記事でもあまりピンと来ないかもしれません。そのため、ざっくりとしたイメージだけ示しておきます。
まずは「ドキュメント」と「インデックス」の例を示します。

「ドキュメント」は Elasticsearch に保存した文書(ここではツイート)のことを表します。同じ種類のドキュメントを集めた入れ物を「インデックス」と呼びます。
次に「テンプレート」と「マッピング」と「フィールド」の例を示します。

「ドキュメント」に含まれる値には、それぞれ「フィールド」と呼ばれる名前が付いています。「マッピング」は「フィールド」の保存方法を定義するルールのことです。例えば Time フィールドにマッピングした「ドキュメント」の値 (Wed Dec 11 13:03:42 +0000 2019) は、 「マッピング」が type = date であることから時間を表す値であることがわかります。また、値のフォーマットは (曜日 月 日 時間 タイムゾーン 西暦) の順であることがわかります。
なお、時刻のフォーマットについては下記のドキュメントに記載されてます。
「テンプレート」は僕考えた最強の「マッピング」です。
通常「インデックス」を作成するとElasticsearch が「マッピング」を自動的に作成します。しかし、予め「テンプレート」を作成しておくことで、Elasticsearch は「テンプレート」から「マッピング」を作成してくれるようになります。
最後に「Analyzer」の例を示します。

Analyzer はテキストをトークン(単語、助詞など)に分解し、転置インデックス(索引)を作成します。転置インデックス(索引)を作成する目的は、トークンからドキュメントを検索するためです。例えば、上図の赤枠で囲った転置インデックスを使用すると、トークン「ピカチュウ」はドキュメント1, 2 の両方に含まれることがわかりますが、トークン「かわいい」はドキュメント 1 にのみ含まれることがわかります。今回は転置インデックスを用いて全文検索することで「ポケモン名」ごとに出現するツイートの数を数え上げ、統計を作成します。
Analyzer は様々な種類があります。デフォルトでは英語のテキストを検索する Analyzer が使用されていますが、今回は日本語のテキストを検索したいため、Analyzer に Kuromoji を使用します。Kuromoji は日本語のテキストをトークンに分解するプラグインです。Kuromoji の詳細については下記の記事でわかりやすく解説されています。
各用語を理解したところで、収集したツイートを分析するために Elasticsearch にテンプレートを設定します。
Elasticsearch にテンプレートを設定をする方法
Elasticsearch を操作する方法には 2 つの方法があります。
- Kibana の「Dev Tools」(GUIで操作可能)
- RESTful インターフェース (REST を使用してプログラムから操作可能)
ここでは操作が簡単なため、Kibana の「Dev Tools」を使用してテンプレートの設定を行います。Elasticsearch や Kibana をインストールする方法は下記の記事にある「インストール」を見てください。
Elasticsearch に設定するテンプレートの内容
Elasticsearch の「テンプレート」で作成するルールは下記の 5 つです。
1. "poke*"という名前のインデックスを作成した時、自動で作成するマッピングとしてこのテンプレートを使用する。
2. time フィールドのフォーマットを(曜日 月 日 時間 タイムゾーン 西暦)とする。
3. tweet フィールドに対してAnalyzerを使用する。
4. Analyzer に kuromoji を指定する。
5. トークンから不要な語句(助詞や接続詞など)をフィルタリングする。
Elasticsearch にテンプレートを設定する具体的な手順
1. Kibana を起動した後、メニューの中から「Dev Tools」(レンチアイコン)を選択します。

2.「Elasticsearch に設定するテンプレートの内容」で記載した 5 つのルールを持った JSON 形式のテンプレートを作成し、Elasticsearch に設定します。
下記のコマンドの 1 行目では Elasticsearch のテンプレート(pokemon)に設定をPUTすることを、2行目以降では設定する 5 つのルールを表しています。
PUT /_template/pokemon
{
"template" : "poke*",
"settings": {
"analysis": {
"analyzer": {
"ja-normal-tokenizer": {
"type": "custom",
"tokenizer": "kuromoji_tokenizer",
"filter": ["stop_posfilter"]
}
},
"filter": {
"stop_posfilter": {
"type": "kuromoji_part_of_speech",
"stoptags": [
"名詞-固有名詞-一般",
"名詞-固有名詞-人名",
"名詞-固有名詞-人名-一般",
"名詞-固有名詞-人名-姓",
"名詞-固有名詞-人名-名",
"名詞-固有名詞-組織",
"名詞-固有名詞-地域",
"名詞-固有名詞-地域-一般",
"名詞-固有名詞-地域-国",
"名詞-代名詞",
"名詞-代名詞-一般",
"名詞-代名詞-縮約",
"名詞-副詞可能",
"名詞-サ変接続",
"名詞-形容動詞語幹",
"名詞-数",
"名詞-非自立",
"名詞-非自立-一般",
"名詞-非自立-副詞可能",
"名詞-非自立-助動詞語幹",
"名詞-非自立-形容動詞語幹",
"名詞-特殊",
"名詞-特殊-助動詞語幹",
"名詞-接尾",
"名詞-接尾-一般",
"名詞-接尾-人名",
"名詞-接尾-地域",
"名詞-接尾-サ変接続",
"名詞-接尾-助動詞語幹",
"名詞-接尾-形容動詞語幹",
"名詞-接尾-副詞可能",
"名詞-接尾-助数詞",
"名詞-接尾-特殊",
"名詞-接続詞的",
"名詞-動詞非自立的",
"名詞-引用文字列",
"名詞-ナイ形容詞語幹",
"接頭詞",
"接頭詞-名詞接続",
"接頭詞-動詞接続",
"接頭詞-形容詞接続",
"接頭詞-数接続",
"動詞-非自立",
"動詞-接尾",
"形容詞",
"形容詞-自立",
"形容詞-非自立",
"形容詞-接尾",
"副詞",
"副詞-一般",
"副詞-助詞類接続",
"連体詞",
"接続詞",
"助詞",
"助詞-格助詞",
"助詞-格助詞-一般",
"助詞-格助詞-引用",
"助詞-格助詞-連語",
"助詞-接続助詞",
"助詞-係助詞",
"助詞-副助詞",
"助詞-間投助詞",
"助詞-並立助詞",
"助詞-終助詞",
"助詞-副助詞/並立助詞/終助詞",
"助詞-連体化",
"助詞-副詞化",
"助詞-特殊",
"助動詞",
"記号",
"記号-一般",
"記号-読点",
"記号-句点",
"記号-空白",
"記号-括弧開",
"記号-括弧閉",
"記号-アルファベット",
"その他",
"その他-間投",
"フィラー",
"非言語音",
"語断片",
"未知語",
"感嘆詞"
]
}
}
}
},
"mappings": {
"properties": {
"tweet":{
"type": "text",
"fielddata": true,
"analyzer":"ja-normal-tokenizer"
},
"time": {
"type": "date",
"format": "EEE MMM dd HH:mm:ss Z yyyy"
}
}
}
}stoptags フィールドで不要な語句をフィルタリングしますが、なんと現時点ではワイルドカードが使えません。ということで 1 つ 1 つ入力するしております・・・
3. Kibana のコンソール上で緑三角ボタンを押すことでコマンドを実行します。
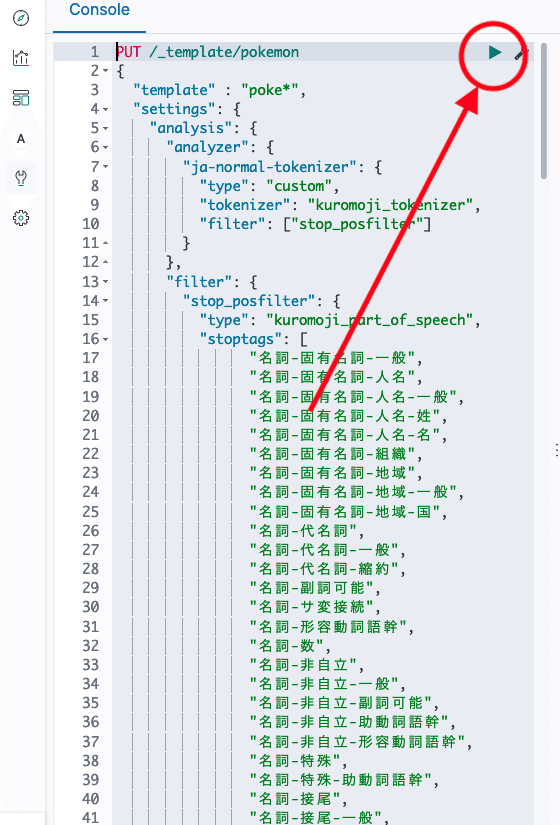
4. 正しく設定されている場合、下記のコマンドでテンプレートが取得できます。
GET /_template/pokemonこれで Elasticsearch の設定が完了しました。
実装手順3. 収集したツイートを Elasticsearch に投入する
Elasticsearch にツイートを投入するためには Bulk API を使用します。
bulk API とは複数の文書 (ツイート) をまとめて Elasticsearch に投入可能なAPI です。Bulk API では、使用できるデータの形が決まっております。具体的には下記の通りです。
POST _bulk
{ "index" : { "id" : "<ドキュメントID1>" } }
{ "<フィールド名1>" : "<フィールドの値1>" }
{ "index" : { "id" : "<ドキュメントID2>" } }
{ "<フィールド名2>" : "<フィールドの値2>" }
そのため先程 Standard search API で取得したツイートを Bulk API で使用できる形に変換する必要があります。変換するプログラムは下記の通りです。
def makeBulkFile(self):
self.data = ""
for line in self.json_searchAPI_response["statuses"]:
self.documentID = self.documentID + 1
self.data += '{"index":{"_id":%d}}\n' % self.documentID
self.data += '{"time" : "%s", "tweet":"%s"}\n' % (line["created_at"], line["text"].replace('\n',''))このプログラムでは、Standard search API で self.json_searchAPI_response に収集したツイートを Bulk API で使用可能な形に変換しています。実際に上記のプログラムで変換したデータは下記の通りとなります。
{"index":{"_id":1}}
{"time" : "Wed Dec 11 13:03:42 +0000 2019", "tweet":"モルペコかわいいな…おなかがすくとぷんすかモードになるのか…たらふく食わせてやりたいねポケモン"}
{"index":{"_id":2}}
{"time" : "Wed Dec 11 13:02:59 +0000 2019", "tweet":"@***** めちゃくさポケモンだ!!!!!!!!!!かわいい!!!!!ぽぽっこわたっこすき!!!!ラフレシアもすき!!!ニョロトノは可愛くないけど混ぜてあげよう…っ"}
変換したツイートを Bulk API を使用して Elasticsearch に投入する
ツイートの変換は Python プログラム中で処理を行うので、Elasticsearch を設定するためには Kibana の「Dev Tools」を使用できません。そのため、今回は RESTful インターフェースを使用します。
def bulkElasticSearch(self):
response = requests.post(self.url, auth=self.auth.awsauth, headers=self.headers, data=self.data)各変数には次のデータが格納されています。
self.url = "https://<Elasticsearch_Endpoint>/<index名>/_bulk/" です。
self.auth.awsauth AWS Elasticsearch を使用するための認証です。通常のElasticsearch を使用する場合は必要ありません。
self.headers = {'Content-Type': 'application/json'}
self.data = <先程のBulk API 用に変換したデータ>
今回作成した実装手順 1~3 の全体コードは下記のようになります。
#!/usr/bin/env python3 #python2.x系だと文字コードでエラー吐くから修正してね
#coding: utf-8
import json
import boto3
import requests
from requests_aws4auth import AWS4Auth
from requests_oauthlib import OAuth1Session
import re
from time import sleep
from botocore.awsrequest import AWSRequest
Elasticsearch_Endpoint = "<変更してください>" ##変更してください AWSのみ
REGION = "<変更してください>" ##変更してください AWSのみ
CONSUMER_KEY = "<Twitter社からもらった値>" ##変更してください
CONSUMER_SECRET_KEY = "<Twitter社からもらった値>" ##変更してください
ACCESS_TOKEN = "<Twitter社からもらった値>" ##変更してください
ACCESS_TOKEN_SECRET = "<Twitter社からもらった値>" ##変更してください
SEARCH_WORD = "ポケモン かわいい"
INDEX = "pokemon_blog"
class Auth():
def __init__(self, service):
credentials = boto3.Session().get_credentials()
self.awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, REGION, service, session_token=credentials.token)
class TwitterSearchAPI_Elasticsearch():
def __init__(self,searchWord,indexName):
self.documentID = 0
self.searchWord = searchWord
self.index_name = indexName
self.params = {
"q": (self.searchWord),
"lang": "ja",
"result_type": "recent",
"max_id": -1,
"exclude":"retweets"
}
self.headers = {'Content-Type': 'application/json'}
self.url = 'https://%s/%s/_bulk/' % (Elasticsearch_Endpoint, self.index_name)
self.auth = Auth("es")
def searchTweetToElasticsearch(self):
twitter = OAuth1Session(CONSUMER_KEY,CONSUMER_SECRET_KEY,ACCESS_TOKEN,ACCESS_TOKEN_SECRET)
while True:
#for i in range(3): ##debug
searchAPI_response = twitter.get("https://api.twitter.com/1.1/search/tweets.json", params=self.params)
if searchAPI_response.status_code == 200:
self.json_searchAPI_response = json.loads(searchAPI_response.text)
if len(self.json_searchAPI_response["statuses"]) == 0: ##これ以上収集できるツイートが無い時終了
break
##今回収集した最後のツイートより1つ前のツイートから、次回のループで検索できるようにする
self.params["max_id"] = self.json_searchAPI_response["statuses"][-1]["id"] - 1
self.makeBulkFile()
self.bulkElasticSearch()
"""
for line in self.json_searchAPI_response["statuses"]:
print(line["created_at"])
print(line["text"])
print("------------")
"""
else:
print('15分待ちます') ##APIの制限
self.auth = Auth("es") ## 1時間制限のため更新
sleep(15*60)
def makeBulkFile(self):
self.data = ""
for line in self.json_searchAPI_response["statuses"]:
self.documentID = self.documentID + 1
self.data += '{"index":{"_id":%d}}\n' % self.documentID
self.data += '{"time" : "%s", "tweet":"%s"}\n' % (line["created_at"], line["text"].replace('\n',''))
def bulkElasticSearch(self):
response = requests.post(self.url, auth=self.auth.awsauth, headers=self.headers, data=self.data)
def run(self):
self.searchTweetToElasticsearch()
if __name__ == '__main__':
TwitterSearchAPI_Elasticsearch(SEARCH_WORD, INDEX).run()正しくデータが入っているか否かはKibana の「Dev Tools」で確認できます。
GET /pokemon_blog/_search実装手順4. 投入したツイートに出現するポケモン名を Elasticsearch の全文検索でカウントし、 Kibana を使用して可視化する。
Kibana の「Visualize」を使用すると Elasticsearch に全文検索の命令をリクエストしつつ、レスポンスを可視化することができます。「Visualize」 を使用する手順は次の通りです。
1. Kibana で、使用するインデックスを指定する
2. インデックスに全文検索リクエストを投げ、結果を可視化する
1. Kibana で、使用するインデックスを指定する
Kibana の「Management」を使用して、「3. 収集したツイートを Elasticsearch に投入する」で作成したpokemon_blog インデックスを指定する手順を記載します。画像の赤枠に沿ってクリックしてください。

Time Filter Field には「2. 収集したツイートを分析するために、Elasticsearch の設定をする。」でマッピングした "time" を指定します。

2. インデックスに全文検索リクエストを投げ、結果を可視化する
いよいよ Elasticsearch で全文検索を行います。

New Visualization で 可視化方法に "Tag Cloud" を選択します。見てのとおりヒートマップや円グラフなども作成できます。

可視化したいインデックスを選択します。今回はpokemon_blogを選択してください。

ここからは Elasticsearch に送信するリクエストを設定します。
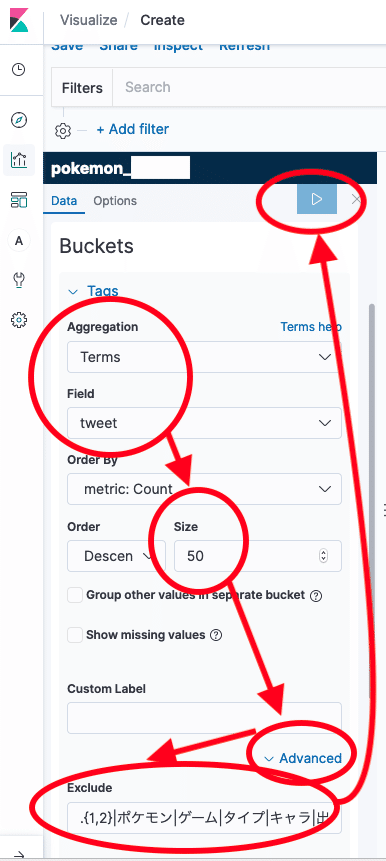
上記の設定内容の詳細は下記の通りです。
1. Aggregation 方法に Terms を指定します。Termsの詳細は下記に記載されています。
2. ツイートに含まれる単語を抽出したいため、Terms の対象とする Field に "tweet" を選択します。
3. Size は結果に表示する単語の数となります。
4. Exclude では特定の文字列をフィルタリングします。ツイート投入段階である程度フィルタリングをしていますが、やはりノイズがあります。kuromoji で使用している bigram の性質上2文字のノイズが入りやすいので、正規表現 .{1,2} を使用して除外しておくことを推奨します。
5. 全ての入力が完了し矢印ボタンを押すと、かわいいポケモンの結果発表の時間です。
結論「最もかわいいポケモン」
Kibana の Visualization で 「Tag Cloud」 と 「Line」の結果を掲載します。
Tag Cloud の結果

Line の結果
注)黃色棒グラフ:11月最終週 青色棒グラフ:12月最初の週

人である主人公はさておき、最もかわいいポケモンはピカチュウであることがわかりました!!せっかくなのでポケモン剣盾発売直後のかわいいポケモンランキング1~5位を掲載しておきます。
1. ピカチュウ

2. メッソン

3. イーブイ

4. マホイップ

5. ワンパチ

今回はポケモン名を用意せずに、全てのトークンを検索しましたが、ポケモン名を事前に用意することで、ポケモン名のみを抽出することができます。逆に言うと、事前に出てくる単語を用意しなくても関連するキーワードを取得できるということです。例えばポケモンをプレイする人は下記のゲームをプレイする傾向があることが抽出できます(下記はかわいいというキーワードに引っ張られています)。これは事前にゲーム名を定義するよりも、より未知の相関を知ることができるでしょう。

人の感情に関するデータはなかなか集めにくいのですが、結構綺麗に収集できたかと思います。また、1回作ってしまえば自分の好きなキーワードで、関連するキーワードを取得できます。汎用性も高いので試してみてはいかがでしょうか。