
前処理って大事なんですね。 〜スッキリわかるPythonによる機械学習入門 9章末問題〜

画像は戒めです。こんなレベルのモデル作るくらいなら、勘でやった方がまだマシなんじゃね?という感じ笑
自分の日記的に書いたつもりが、いいねを2桁もいただいてしまいました。
世の中のデータサイエンスへの注目度はやっぱり高いんですねえ。
ど素人の勉強日記なので、たくさん読まれるとそれはそれでレベル低くて恥ずかしいのですが笑
さて、並行していろいろな観点で勉強進めていますが、今日は現在取り組んでいるPythonによる機械学習入門編です。活用しているのはこちら。
同じシリーズのすっきりわかるPythonで基礎を学んでから(ほぼ覚えていないけど)、こちらに移行して取り組んでいまして、現在第9章の章末練習問題。教師あり学習の総復習的な問題に取り組んでいます。
内容としては「金融機関のキャンペーン分析」で、キャンペーンの結果を目的関数として、モデル作成して予測性能を可能な限り高めていくもの。
自力でモデル作ってみるのは、この本の中では初めて。正解とは程遠い内容だったため、各ステップでの失敗を備忘を兼ねて、記載していきます。
前処理
まず自力で思いついた前処理は2つ。
(1)欠損値の補完
これは思いついたというか、当然のプロセスですよね多分。
接触時の平均時間(秒)とキャンペーン結果は密接に関係しそうと思ったが、全項目をdf.shapeで確認すると(27128, 16)という数字が。
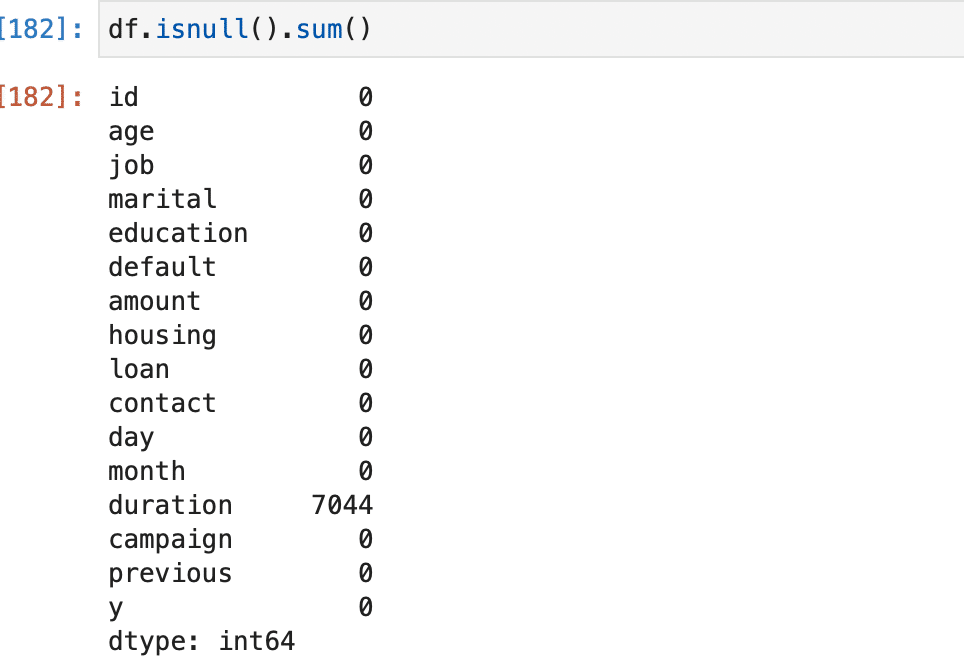
7044/27128かあ〜、多いなあ。テキストには数が多すぎると欠損値を埋めることで精度に大きく影響しすぎると書いてあったので、今回は特徴量に入れ込むことはパス。
(今書いていて気づいたのですが、言っても25%程度なので大部分ではなかった。寝ぼけていたのか。多分そう。きっとそう。)
正解のプロセスでは、この欠損値は中央値でしっかり埋めていました。
(2)ダミー変数化
覚えているぞ。文字列では特徴量として突っ込めないから、01に変換するのだ!
ど文系の自分的には、0か1かみたいな表し方というか考え方にも最近ようやく慣れてきた気がします。最初に基本情報のテキストを読んだときは、なんじゃそりゃ。でした。
今回のケースで言うと、job, education, marital, loan, housing, default…
いやーありすぎぃぃ。
面倒くさがりの私の性格にはきついので、関係ありそうなloanとhousingあたりをダミー変数化して、データフレームに結合。
全然数値が上がらずに観念して回答を見ると、なんとまとめてダミー変数化する術があるらしい。。そんなことテキストに書いてあったっけな。
書き始めたらミスポイントありすぎてキリがないので今日はこの辺で。
学習・評価の過程でも、あーこうやれば良かったかあという箇所がいくつかあったので、別記事でまたそのうちまとめます。
※同じようにデータサイエンス勉強中の方、すでにプロフェッショナルな方、ちょっとしたアドバイスやコメントあればいただけるととても励みになります!