
BigQuery ML でお手軽機械学習

マネーフォワード CTO 室 AI 推進部の tamiya と申します。
好きなものはスリランカカレーで、最近オフィスの近くに R スリランカ三田という福岡(※注1)にある有名店の新店舗ができてテンション上がってます。
※注1: 実は九州では福岡を中心にスリランカ料理が独自の進化・発展を遂げており、スリランカカレーのお店がたくさんあるのです。「九州ランカ」という造語まであるくらいです。
福岡スリランカカレーの代表店「ツナパハ」については、こちらの記事もご覧ください: https://note.com/ryoga_nishimoto/n/n83e9c08d77ff
さて、みなさん、 BigQuery ML ってご存知でしょうか?
データ系に携わる方なら、一度くらいは聞いたことがあるかもしれません。
BigQuery ML (以下 BQML) は、BigQuery から機械学習モデルの作成・予測といったタスクを行える機能です。
機械学習って、正直面倒ですよね?
データを引っ張ってきて、データの前処理して、データを学習用・検証用・テスト用に分けて、精度評価して… といった具合にステップが多いうえに、これらを Python や R といったプログラミング言語で一つ一つ書かなくてはいけない。
とてもじゃないですが、機械学習を専門にやってきた人じゃないとハードルが高くてとっかかりが悪いのではないかと思ってます。
しかし、 BQML を使えば、SQL さえ書ければその延長線上で簡単に機械学習モデルを作ることができます!
この記事では、簡単なタスク例を交えつつ、BQML で何ができるか、どれだけ簡単に使えるのかを紹介していきたいと思います。
概要(ダイジェスト)
BQML を用いれば、BigQuery 上で SQL の拡張クエリを書くだけで手軽に機械学習モデルを作り、精度評価・モデル説明まで行える。
データが BigQuery に揃っていて機械学習を適用したらどうなるかをサクッと試してみたい場合に非常におすすめ。
ただし、利用料金には注意(特にデータサイズが大きい時や、 Deep Learning や AutoML などの複雑なアルゴリズム・機能を使う場合)。
BQML とは?
BQML は、上記で述べたように BigQuery 上で機械学習のモデル作成や関連したタスクを実行できる機能です。
そのメリットはというと、ざっと以下のようなものが挙げられます:
BigQuery で機械学習タスクがほぼ完結する
SQL を拡張したクエリで簡潔に実行できる
扱えるタスクの種類も、オーソドックスな手法であれば一通りはカバーしています。
そのため、BQ 上にあるデータでサクッと手軽に予測・分類などを試したいときにうってつけです。
簡単な例: GA4 を用いたユーザー行動予測
細々と機能について解説するよりも、百聞は一見にしかず、まずは実際に使っているところを見ていただきたいと思います。
以下では、Google Analytics 4 (GA4) の公開データを用いたユーザー行動分析を、 BQML の 勾配ブースティング (XGBoost) モデルを用いて行ってみます。
題材としては、Google が公開している ga4_obfuscated_sample_ecommerce という Google Analytics 4 のサンプルデータセットを加工して用います。これは、EC サイトにおけるユーザー行動を記録したものです。
あらかじめセッション単位で集計を行ってテーブルに保存しておいたデータがこちらになります(集計クエリは割愛)。
SELECT
*
FROM
`sample-project.sample_dataset.demo_ga_sessions`
LIMIT
100
内容としては、
use_session_id: セッションID(primary key)
event_date: セッション開始日
session_start_at: セッション開始日時
flg_purchase: セッション内で購買が行われたかを表す二値フラグ
flg_first_visit: 初回アクセスかどうかを表す二値フラグ
device_category, mobile_brand_name, … デバイス種類やアクセス環境などの情報
といったものを用意しました。
これをもとに、「どのような特徴を持つセッションであれば、購買行動を起こしやすいか?」を見ていくことを考えます。
早速ですが、購買した or しないの二値分類問題として分類モデルを作ろうと思います。
それには、以下のようなクエリを書きます:
CREATE OR REPLACE MODEL
`sample-project.sample_dataset.demo_ga_boosted_tree_model`
OPTIONS(
MODEL_TYPE='BOOSTED_TREE_CLASSIFIER',
DATA_SPLIT_METHOD="CUSTOM",
DATA_SPLIT_COL="is_test",
INPUT_LABEL_COLS = ['flg_purchase']) AS
SELECT
* EXCEPT(event_date, session_start_at,
user_session_id),
IF(event_date >= "2021-01-01", TRUE, FALSE) AS is_test
FROM
`sample-project.sample_dataset.demo_ga_sessions`え?これだけ?
と思うかもしれませんが、このクエリを実行して 3~4分ほど待てばモデルが出来上がり、精度評価まで完了します。
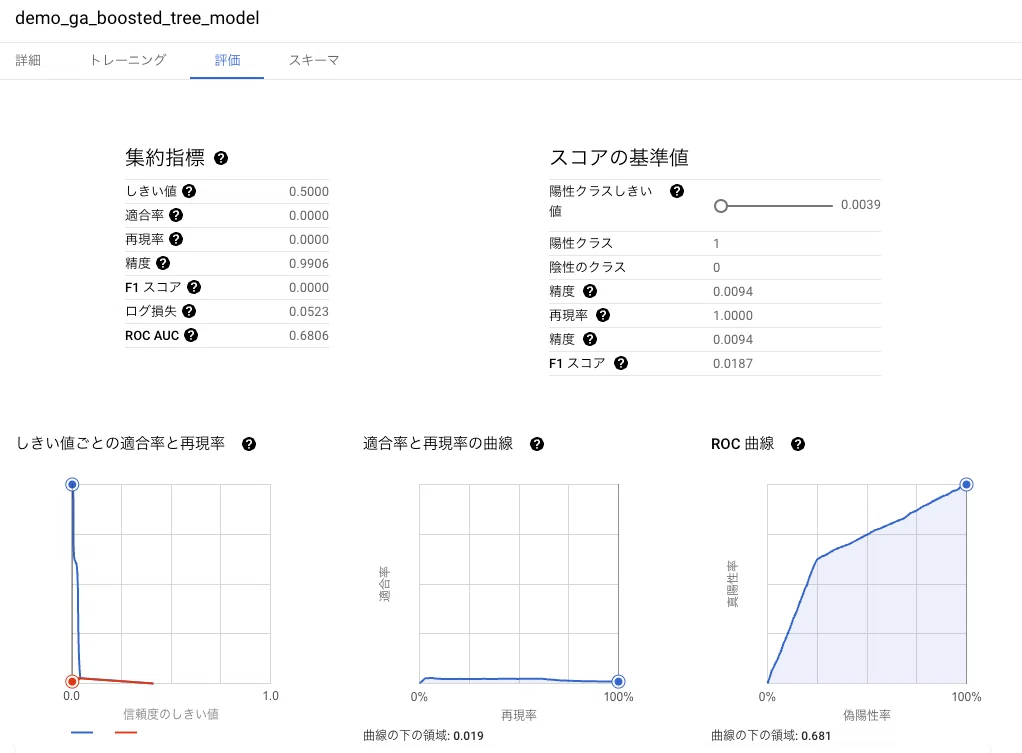
ほら、この通り!
UI 上から作成したモデルの精度評価指標を見ることができます。
今回はデモのために強引なモデルの作り方をしましたが、 ROC AUC という指標を見ると 0.68 なので、当てずっぽうに予測を行った場合(ROC AUC が0.50になる)よりはマシ、ということになります。
ついでに、今回の勾配ブースティングモデルの場合、どの特徴量が予測に寄与したかを示す重要度を見ることもできます:
SELECT
feature,
importance_gain
FROM
ML.FEATURE_IMPORTANCE(MODEL `sample-project.sample_dataset.demo_ga_boosted_tree_model`)
ORDER BY
importance_gain DESC
`importance_gain` のカラムを見ると、flg_first_visit が圧倒的に効いていています。初回アクセスかどうかで購買のしやすさが変わるようです。
BQML を使うメリット
上記で見ていただいた通り、BQML を使って機械学習タスクを行うと、 R や Python を書く場合と比べて以下のような2つのメリットがあります。
メリット1. 一つの環境で作業が(ほぼ)完結する
R や Python では分析を実行するための環境を用意する必要がありますが、BQML であれば BigQuery と必要な権限さえあればすぐに実行することができます。
また、BQML はデータの抽出・加工から全て BigQuery 上で行うことができるため、DB から抽出したデータを分析環境に持っていって… といった作業も不要です(データが BigQuery 上にある限り)。
環境構築も環境を跨いだデータの移動も、機械学習に取り掛かるまでのハードルを地味に押し上げる要因となっていますが、 BQML ではこれらがないおかげでスムーズにストレスなく思い立ったらすぐ分析・モデル構築に着手できます。
ただし、結果の可視化に関しては BigQuery の UI 上で行えるものだけでは不十分なので、別途 Looker Studio、Google Colaboratory、Spread Sheet といった別のツールを利用する必要があります。
とはいえ、これらのツールとの連携も UI 上から比較的スムーズに行えるようにできているので、慣れればそこまで困ることはないでしょう。
メリット2. コードを書く手間が少なくて済む
BQML を使うと、R や Python を使う場合と比べて複数のパッケージやライブラリを使い分ける必要がないことに加えて、コードを書く量自体も少なくてすみます。
これも、実例を持ってお見せしましょう。
先程紹介した実行例とほぼ同一内容のモデル作成〜精度評価までの処理を Python で書いてみたのがこちらになります(XGBoost の代わりに決定木を用いたなどの細かい差異はあります)。
import datetime
import pandas as pd
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.preprocessing import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.metrics import RocCurveDisplay
import pydata_google_auth
# credential の取得 (BigQuery 接続用)
credentials = pydata_google_auth.get_user_credentials(
['https://www.googleapis.com/auth/bigquery'],
use_local_webserver=False
)
# データの読み込み
query = """
SELECT
*
FROM
`sample-project.sample_dataset.demo_ga_sessions`
"""
df = pd.read_gbq(query=query, project_id="sample-project", credentials=credentials)
# 前処理
categorical_cols = df.columns[(df.dtypes == "object") & ~(df.columns.isin(["user_session_id", "event_date", "session_start_at"]))]
cols_to_use_directly = ["flg_first_visit"]
label_to_pred = "flg_purchase"
date_test_start_at = datetime.date(2021,1,1)
df_train = df[df["event_date"]<date_test_start_at]
df_test = df[df["event_date"] >= date_test_start_at]
## 訓練データ
train_original = df_train[categorical_cols]
### 欠損値の補完
si = SimpleImputer(strategy="constant", fill_value="(missing)")
train_imputerd = si.fit_transform(train_original)
df_train_imputed = pd.DataFrame(train_imputerd, columns=si.get_feature_names_out())
### カテゴリカル変数の加工
ohe = OneHotEncoder(handle_unknown="ignore", sparse_output=False, min_frequency=0.001)
train_encoded = ohe.fit_transform(df_train_imputed)
X_train_encoded = pd.DataFrame(train_encoded, columns=ohe.get_feature_names_out())
X_train = pd.concat([df_train[cols_to_use_directly].reset_index(drop=True), X_train_encoded], axis=1)
y_train = df_train[label_to_pred]
df_train[cols_to_use_directly].isna().any(0)
## テストデータ
test_original = df_test[categorical_cols]
test_imputerd = si.transform(test_original)
df_test_imputed = pd.DataFrame(test_imputerd, columns=si.get_feature_names_out())
test_encoded = ohe.transform(df_test_imputed)
X_test_encoded = pd.DataFrame(test_encoded, columns=ohe.get_feature_names_out())
X_test = pd.concat([df_test[cols_to_use_directly].reset_index(drop=True), X_test_encoded], axis=1)
y_test = df_test[label_to_pred]
# モデル作成
tclf = DecisionTreeClassifier(max_depth=5, min_samples_leaf=0.05, criterion="entropy")#, class_weight="balanced")
tclf.fit(X_train, y_train)
# 精度評価 (ROC曲線、ROC AUC)
RocCurveDisplay.from_estimator(tclf, X_test, y_test)いかがでしょう?Python では72行になりました。BQML では13行でしたので、単純計算でおおよそ5.5倍の行数あることがわかります。
なぜ BQML だと行数が少なくて済むかですが、これにはいくつかの理由があります:
パッケージの import やデータ読み込みのための設定などの細かい操作がいらない
データの読み込み、前処理、モデル作成までを一つのクエリで行える
前処理を特に指定しなくても自動でよしなにやってくれる
この中でも、3つ目の前処理等を自動でやってくれるのは非常に助かります。
機械学習を少しでもやったことがある方ならわかるかと思いますが、モデル構築の前段階の処理は結構面倒です。
例えば、特徴量として数字ではなく商品名などの文字列を使う場合、One-hot-encoding といってカテゴリーごとに 0 or 1 のフラグを付与することがよくあります。
こうした処理を必要なカラムだけ抜き出して行う、ということを通常はしなくてはいけません。
実際、上記の Python コードの半分近くがこのような前処理に費やされています。
それがなんと、BQML なら特徴量として使いたいカラムを SELECT 句の中に含めておけば、処理が必要かどうかを自動で判断してくれるのです!(もちろん、カスタムで指定することもできます)
その他にも、処理内容に応じて複数のパッケージ・ライブラリを行き来する必要がないのも地味にありがたいです。
例えば、 Python なら前処理は Pandas と Scikit-Learn でやって、モデルは LightGBM で、ハイパーパラメータチューニングには Optuna を使って、予測結果の説明には SHAP を… などと、それぞれインターフェイスの異なる複数のパッケージを使い分けなくてはいけません。
その点 BQML であれば、SQL の拡張表記だけで全てを行うことができます。
もちろんタスクに応じてインターフェースが少しずつ異なりますが、比較的統一感があるのでそこまで困ることは多くないと思います。
BQML で扱えるタスク
さて、ここまで見ていただいたようにお手軽な BQML ですが、扱えるタスク・アルゴリズムの種類もそこそこに豊富です。
流石になんでもできるとまではいきませんが、下記のような標準的なタスクは一通り実行できます:
予測(回帰、分類)
レコメンド
クラスタリング
異常検知
時系列予測
アルゴリズムも、シンプルな線形回帰やコンペなどで人気の Boosted Tree (XGBoost) から、Deep Learning 系の手法まで使うことができます。

また、モデル作成以外にも前処理・ハイパーパラメータチューニング・精度評価・モデル説明といった周辺プロセスについても機能が揃っている点も注目ポイントです。
特にモデル説明については、SHAP という予測結果の根拠を提示してくれるアルゴリズムが利用できたりと便利です。
アルゴリズムごとのモデル構築サイクルと利用可能な機能については、下記の一覧を参照してください。
以上に加えて、より advanced なオプションとしてテキスト分析や翻訳、テキスト生成などといった機能も提供されています。
ご興味のある方は以下の記事を参考にしてみてください。
使用上の注意
このように便利で色々できる BQML ですが、いくつか気をつけるべき事項があるのでそれについても触れておきます。
BQML ではできないこと
BQML は標準的な処理・アルゴリズムを一通り扱えると書きましたが、逆にいうと標準から外れたことは苦手なケースも多いです。
たとえば、カスタマイズの自由度は低いです。
基本的にアルゴリズムをいじることはできません。設定可能なパラメータが豊富に用意されているのでその範囲でのチューニングはできるものの、アルゴリズムの中身を部分的に変えるといったことは不可能です。
また、使いたい評価指標が BQML 側で用意されていない場合は自分でクエリを書く必要が出てきます。
また、高度な手法については提供されていないものも多いです。
先ほど触れたようにいわゆる「生成 AI」は最近部分的に追加されましたが、例えばベイズ推定や状態空間時系列モデルの類は提供されていません。
予測アルゴリズム以外にも、交差検証(Cross Validation)や Permutation Importance も現時点では提供されていないことにも注意が必要です。
コスト
BigQuery を利用する際に気をつけなければいけないのが利用料金です。
通常のクエリであればデータスキャン量に応じて課金されているため、気が付かないうちに数百 TB のクエリを何回も打って数百万の請求が来た、なんていう怖い話もしばしば聞きます。
BQML ではどうでしょう?
BQML でも同様に、モデル作成時・推論時のデータスキャン量に対して課金が行われます。
したがって、スキャン量には引き続き注意をする必要があります。
特に機械学習の場合はチューニングなどのために何度も試行を繰り返すことも多いので、入力データはあらかじめ必要な分だけテーブルに保存して使い回すなどの工夫をしておくのが良いでしょう。
それ加えて、アルゴリズムによってはモデル学習を Vertex AI で行うため、そちらのコストもかかります。
対象となるのは、Boosted Tree などの決定木系の手法、Deep Learning 系の手法、Auto ML などといった、複雑なアルゴリズムです。
これらの場合は Vertex AI 側での課金額が事前に想定しづらいので、少ないデータ量から始めて様子を見るなどの工夫が必要です。
詳しくは、下記のドキュメントをご確認ください。
まとめ
いかがでしたでしょうか?
BQML を使うと、BigQuery 上にデータがある限りは簡単に機械学習モデルを作って評価まで行うことができます。
一方で、標準的な手法から外れたことはやりづらいほか、データ量や使用アルゴリズム次第では課金額にも注意が必要になります。
以上を踏まえると、下記のようなシチュエーションでは BQML の使い所だと考えます:
データが BigQuery 上に全て揃っている
とりあえず機械学習を使うとどのような感じになるかサクッと試してみたい
複雑なアルゴリズムを使う場合やデータスキャン量の多い処理を何度も繰り返すような場合は、スキャン量を減らす工夫をしたうえで事前にどれくらい課金されそうか見積もっておきましょう。
また、アルゴリズム自体を細かく調整する必要がある場合は BQML の利用を諦めてローカル環境かクラウドに立てたインスタンス上で Python や R でコードを書くことをお勧めします。