BigQuery ML の自然言語処理機能でどんなことができるか・どう実行するか?

マネーフォワードケッサイの tamiya です。
この記事では、前回に引き続きスリランカカレーの魅力について BigQuery ML で提供されている自然言語処理機能について紹介します。
BigQuery ML(以下、BQML)は、BigQuery (以下、BQ)上で通常の SQL を拡張したクエリを用いて機械学習タスクを行うことができる機能です。
以前の記事で概要と基本的な使い方を紹介しましたが、BQML はデータ加工〜モデル作成・予測実行までが BQ 上で完結するという強力なメリットがありました。
また、回帰・分類に加えて、時系列予測・クラスタリング・レコメンドなど標準的な機械学習アルゴリズムが一通り揃っている点も嬉しいポイントです。
加えて近年では、生成 AI 含む自然言語処理機能も急速に充実しつつあります。
そこで今回は、BQML の自然言語処理機能でどのようなことが行えるか、どのように使うかについて紹介していこうと思います。
BQML の自然言語処理機能でできること
早速ですが、BQML で行える自然言語処理タスクについて、代表的な例をいくつか挙げます:
テキスト分類
感情分析
文章翻訳
テキスト類似度評価〜クラスタリング
テキスト生成
それぞれ簡単に紹介します。
テキスト分類
入力テキストのカテゴリを推定してくれます。
使用関数:ML.UNDERSTAND_TEXT
オプション指定 … 'CLASSIFY_TEXT' AS nlu_option
活用例:会社名や取引明細品目をカテゴリ分けする
感情分析
入力テキストから感情の正負とその強さを推定してくれます。
使用関数:ML.UNDERSTAND_TEXT
オプション指定 … 'ANALYZE_SENTIMENT' AS nlu_option
活用例:カスタマーレビューコメントの分析
文章翻訳
入力したテキストを指定した言語へと翻訳してくれます。
使用関数:ML.TRANSLATE
テキスト類似度評価〜クラスタリング
テキスト埋め込み (text embedding) という手法を使って入力テキストをベクトル化し、内容の「近さ」を評価することができます。
生成されたベクトルを BQML の K-Means などにかけることで、文章のクラスタリング(グループ分け)を行うこともできます。
活用例:カスタマーレビューコメントや取引明細品目のクラスタリング
テキスト生成
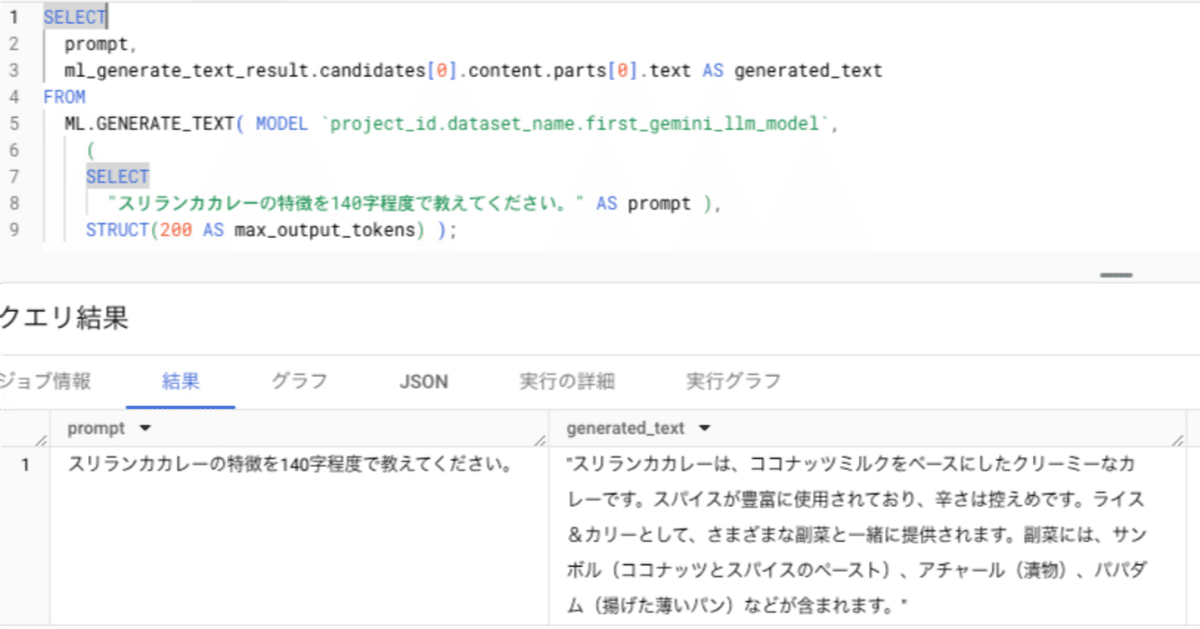
指定した内容に沿って文章を生成することができます。ChatGPT などでいうところのプロンプトをクエリで入力するイメージです(ヘッダー画像参照)。
モデルが選択可能で、最近話題になっている Gemini も利用できます。
ただし、2024/02/23時点では Gemini のバージョン指定はできません。
明記はされていないものの、 BQML から利用できるものは Gemini 1.0 Pro であり Gemini 1.0 Ultra や Gemini 1.5 Pro はまだ使えないものと思われます(が、最近のリリースのスピード感からするとそう遠くないうちに対応するかもしれません)。
詳しくはこちらをご確認ください。
入力するプロンプト次第で様々なタスクを実行することができます。
使用関数:ML.GENERATE_TEXT
活用例: 会社名から業種を推定する(プロンプト例「次の会社名の業種を推定してください: 株式会社TAMIYAカレー」)
そのほか
上記で挙げたほかにも、固有表現分析 (ANALYZE_ENTITIES) や構文解析 (ANALYZE_SYNTAX) なども実行できます。
以降では、いくつかピックアップして具体的に使い方をみていこうと思います。
テキスト分類の活用例
ここでは具体的なイメージが湧きやすいようにテキスト分類を例に BQML の自然言語処理機能を実際に使ってみようと思います。
例えば以下のような架空の取引データがあったとします(ChatGPTにより生成):
SELECT
*
FROM
`project_id.dataset_name.sample_transactions`
ORDER BY transaction_id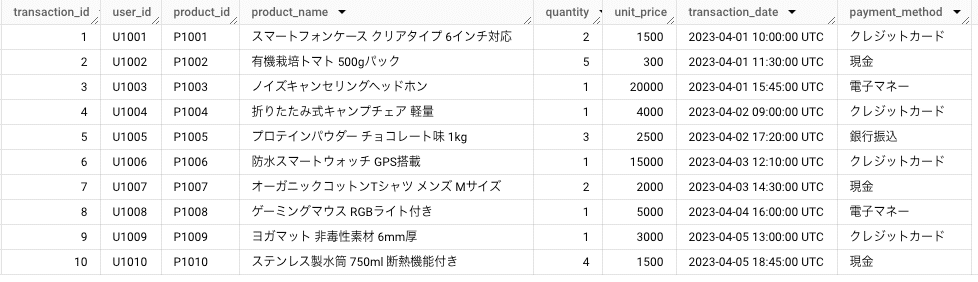
このうち、商品名 (product_name) をいくつかのカテゴリーに分けてカテゴリー別の売れ行き分析などに役立てたいと考えています。
そこで、BQML のテキスト分類機能を用いて商品名をカテゴリー分けしてみようと思います。
BQML のテキスト分類について
テキスト分類を行うには、ML.UNDERSTAND_TEXT という関数を使います。
この関数は、オプションに応じてテキスト分類・感情分析・固有表現抽出・構文解析など様々なタスクを行えます。
このうち 'CLASSIFY_TEXT' というオプションを指定して実行することで、入力したテキストを全 1091 カテゴリーの中から割り当て、その確からしさ(confidence)と共に出力することができます。
テキスト分類タスクの実行結果
詳細な使い方については後で解説することにして、ここでは先に実行結果をお見せします。
以下のように、`first_language_model` という名前で作成したモデルを使用して、商品名に ML.UNDERSTAND_TEXT 関数を適用しました。
SELECT
transaction_id,
text_content AS product_name,
STRING(ml_understand_text_result.categories[0].name) AS `Classified Name`,
FLOAT64(ml_understand_text_result.categories[0].confidence) AS `Confidence`,
FROM
ML.UNDERSTAND_TEXT( MODEL `project_id.dataset_name.first_language_model`,
(
SELECT
transaction_id,
product_name AS text_content
FROM
`project_id.dataset_name.sample_transactions`
ORDER BY
transaction_id ),
STRUCT('CLASSIFY_TEXT' AS nlu_option) )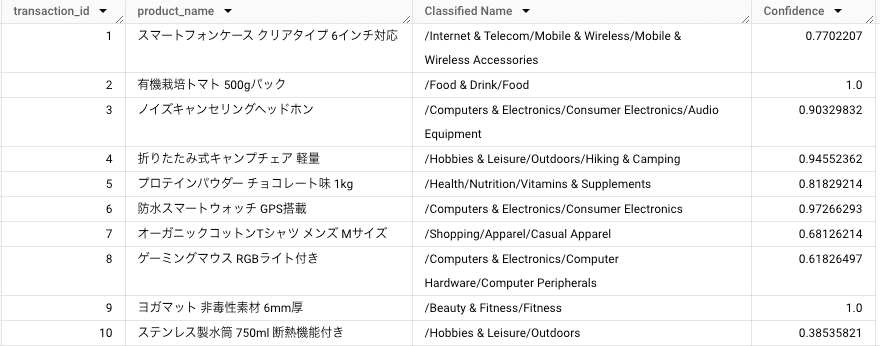
Classified Name が分類結果、Confidence はその確らしさを 0~1 の数値で表したものです。
1行目のスマホケースが 77.0% の確らしさで Mobile & Wireless Accessories に割り当てられていたりと、全体的にそれっぽい分類結果になっていることがわかります。
10行目の水筒がアウトドアに割り当てられていることにやや違和感はあるものの、Confidence を見ると 38.5%と他と比べて低めに出ていますね。
実行手順
ここでは、BQML の自然言語処理機能の実行手順を簡単に解説します。
引き続き先ほどと同様のテキスト分類を例にしますが、付与する権限やオプション設定が異なるだけで他のタスクでも流れは基本的に共通します。
事前準備
テキスト分類に限らず BQML の自然言語機能は、GCP の提供する API や Vertex AI 上の既成のモデルを呼び出すことで実行します。
そのため、最初に以下の操作をする必要があります:
API の有効化
Vertex AI remote model との接続を作成
Service Account への必要なアクセス権の付与
詳細は省きますが、テキスト分類を含む ML.UNDERSTAND_TEXT 関数を利用する場合であれば、下記のドキュメントの手順に従って Natural Language API を有効化したうえで接続の作成と Service Account へのアクセス権の付与を行なってください。
これらを行ったうえで remote model を作成することで、 BQ からクエリで処理を実行できるようになります。
remote model の作成
前述の準備が整ったら、remote model の作成を行います。
自然言語処理機能では、回帰や分類など他の BQML の機械学習モデルと異なり BQ からはモデル学習を行いません。
その代わり、remote model という形で API や Vertex AI 上のモデルの呼び出し設定を定義します。
以下のように `first_language_model` という名前で remote model を作成することで BQ から Natural Language API を呼び出せるようになります。
CREATE OR REPLACE MODEL
`project_id.dataset_name.first_language_model`
REMOTE WITH CONNECTION `project_id.us.try_bqml_nlp`
OPTIONS (REMOTE_SERVICE_TYPE = 'CLOUD_AI_NATURAL_LANGUAGE_V1');3行目の `project_id.us.try_bqml_nlp` は、前段で触れた手順で作成した Vertex AI remote model との接続です。
タスクの実行
次に先ほど作成した remote model `project_id.dataset_name.first_language_model`と対象データセットを指定して、ML.UNDERSTAND_TEXT 関数を呼び出すクエリを書きます。
SELECT
*
FROM
ML.UNDERSTAND_TEXT( MODEL `project_id.dataset_name.first_language_model`,
(
SELECT
product_name AS text_content
FROM
`project_id.dataset_name.sample_transactions`
ORDER BY
transaction_id ),
STRUCT('CLASSIFY_TEXT' AS nlu_option) )この時のポイントは2つです:
処理を適用したいカラムの名前を text_content にする
オプション STRUCT('CLASSIFY_TEXT' AS nlu_option) によりテキスト分類を指定する
上記クエリの実行結果は以下のようになります:

ml_understand_text_result というカラムに、テキスト分類結果が JSON で入っています。
このうち「スマートフォンケース クリアタイプ 6インチ対応」についての結果を詳しく見ると、以下のようになっています:
{"categories":[
{
"confidence":0.7702207,
"name":"/Internet & Telecom/Mobile & Wireless/Mobile & Wireless Accessories"
},
{
"confidence":0.1710894,
"name":"/Internet & Telecom/Mobile & Wireless/Mobile Phones"
}
]}"name" に推定カテゴリが、"confidence" に推定の確からしさのスコアが入っています。
また、当てはまる候補が複数ある場合は、confidence が高い順に複数の推定結果が返ってきます。
上記の例では、携帯アクセサリ (77.0%)、携帯電話 (17.1%) と推定されたと読むことができます。
このままだと読みにくいので、前章で紹介した実行結果では以下のように各商品名について最も確からしいカテゴリ候補とその confidence の値を列にして取ってきました:
SELECT
transaction_id,
text_content AS product_name,
STRING(ml_understand_text_result.categories[0].name) AS `Classified Name`,
FLOAT64(ml_understand_text_result.categories[0].confidence) AS `Confidence`,
FROM -- 以下略その他のタスクの実行例
テキスト分類と同様の手順で、他の自然言語処理タスクも実行することができます。
ただし、使用する関数によっては新たに API の有効化を行ったり Service Account へ追加でアクセス権を付与する必要が生じる場合がありますので、その都度ドキュメントを確認しましょう。
以下では、感情分析とテキスト生成の実行例を簡単に紹介します。
感情分析
以下のような架空の商品への口コミレビューデータが手元にあるとします。
SELECT
*
FROM
`project_id.dataset_name.sample_product_reviews`
ORDER BY
review_id
この中の review_text について、購入者の感情がネガティブかポジティブかを自動で判別しようと思います。
これを実行するには、先ほどのテキスト分類と同じ ML.UNDERSTAND_TEXT 関数で、オプションとして STRUCT('ANALYZE_SENTIMENT' AS nlu_option) を指定します。
その実行結果がこちらです:
SELECT
review_id,
text_content AS review_text,
FLOAT64(ml_understand_text_result.document_sentiment.magnitude) AS sentiment_magnitude,
FLOAT64(ml_understand_text_result.document_sentiment.score) AS sentiment_score
FROM
ML.UNDERSTAND_TEXT( MODEL `project_id.dataset_name.first_language_model`,
(
SELECT
review_id,
review_text AS text_content
FROM
`project_id.dataset_name.sample_product_reviews`
ORDER BY
review_id),
STRUCT('ANALYZE_SENTIMENT' AS nlu_option) );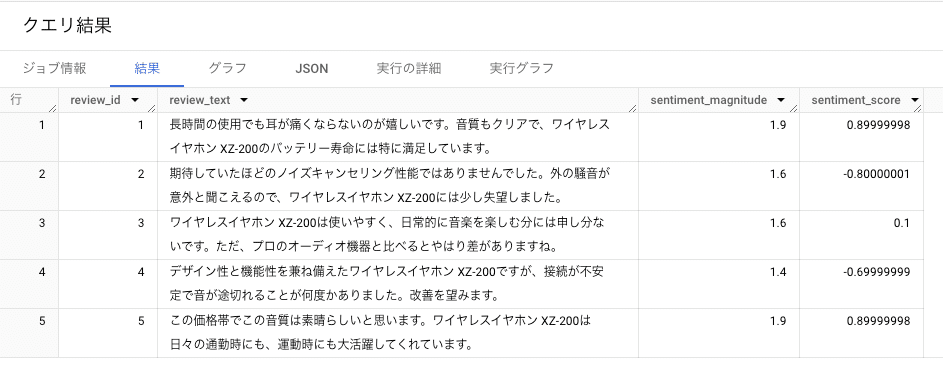
sentiment_score が感情のネガティブ・ポジティブの度合いを-1.0~+1.0 の数値で表しています。sentiment_magnitude は感情の強さを数値化したものです。
これを見ると、商品に対して好印象なレビューでは score がプラスに、不満を訴えているものではマイナスになっていることがわかります。
なお、上記の例では文章全体での感情を見ましたが、ml_understand_text_result の中身を見ると文ごとの感情分析結果を取得することもできます。
{"document_sentiment":{"magnitude":1.9,"score":0.89999998},
"language":"ja",
"sentences":[
{"sentiment":{"magnitude":0.89999998,"score":0.89999998},
"text":{"begin_offset":-1,"content":"長時間の使用でも耳が痛くならないのが嬉しいです。"}},
{"sentiment":{"magnitude":0.89999998,"score":0.89999998},
"text":{"begin_offset":-1,"content":"音質もクリアで、ワイヤレスイヤホン XZ-200のバッテリー寿命には特に満足しています。"}}
]}テキスト生成
以下では、テキスト分類のところで行った商品名のカテゴリ分けを、 ML.GENERATE_TEXT 関数によるテキスト生成機能を用いて実行してみようと思います。
先ほどの ML.UNDERSTAND_TEXT 関数を使ったテキスト分類ではカテゴリは API 側で用意された既存のものが適用されましたが、今回はあらかじめこちらで指定したカテゴリに分類してもらうために以下のようなプロンプトを与えます:
次の商品名のカテゴリを、「アクセサリー」「食料品」「電子機器」「家具」「衣類」「雑貨」「その他」のいずれかに分類してください: (商品名)
`(商品名)` の部分に入力データの product_name カラムの内容を入れます。
これを実行するクエリは以下のようになります:
SELECT
transaction_id,
product_name,
ml_generate_text_result.candidates[0].content.parts[0].text AS suggested_category
FROM
ML.GENERATE_TEXT( MODEL `project_id.dataset_name.first_gemini_llm_model`,
(
SELECT
transaction_id,
product_name,
"次の商品名のカテゴリを、「アクセサリー」「食料品」「電子機器」「家具」「衣類」「雑貨」「その他」のいずれかに分類してください: " || product_name AS prompt
FROM
`project_id.dataset_name.sample_transactions`
ORDER BY
transaction_id ));`project_id.dataset_name.first_gemini_llm_model` はあらかじめ作成しておいた Gemini によるテキスト生成の remote model です(後述)。
プロンプト文は prompt というカラム名にして入力しています。
実行結果は以下のようになります:
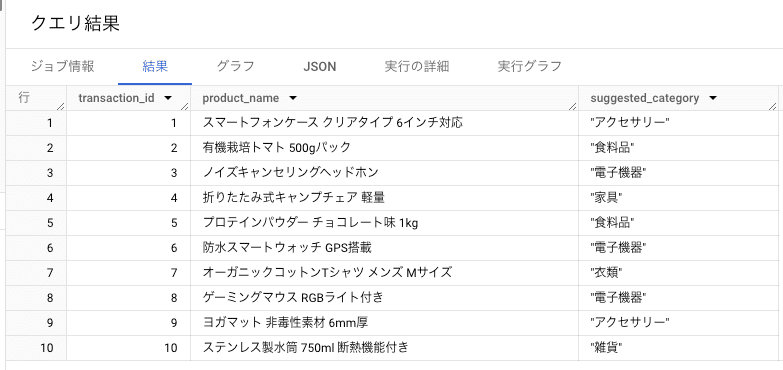
ヨガマットがアクセサリーに割り当てられるなどやや微妙な点もありますが、全体的にそれっぽい分類になっていることが見て取れます。
以下、実行手順について簡単に補足します。
ML.GENERATE_TEXT 関数を使うためには、前準備として ML.UNDERSTAND_TEXT の時に設定した内容に加えて Vertex AI API の有効化と Service Account への追加の権限付与が必要になります。
詳しくは以下のドキュメントに沿って設定してください:
そのうえで、先ほどと同様に remote model を作成します。
ここでは、ENDPOINT として使用するモデルを指定します。
指定可能なモデルの種類はこちらのドキュメントを参照してください。
今回はせっかくなので gemini-pro を使いました。
CREATE OR REPLACE MODEL `project_id.dataset_name.first_gemini_llm_model`
REMOTE WITH CONNECTION `project_id.us.try_bqml_nlp`
OPTIONS (ENDPOINT = 'gemini-pro');ここまでできたら、あとはこれまでと同様に ML.GENERATE_TEXT 関数に作成した remote model と入力データを指定して実行します。
プロンプト文のカラム名を prompt にすることをお忘れなく。
利用料金についての注意
さて、ここまでいくつかの例と共に BQML の自然言語処理機能を見てきましたが、気になるのは実行にかかるお値段です。
基本的には、BQML の自然言語処理機能は Unicode での入力文字数単位で課金されます(テキスト生成のみ、出力文字列数に対しても課金されます)。
だいたい1,000文字あたり $0.0005 ~ $0.0020 程度の課金なので、よほどの長文を入出力したり行数の多いテーブルに適用したりしない限り多額の請求が来て BQ 破産といった事態には陥らないでしょう。
とはいえ安全を考えるのであれば少量のデータで実験してみて料金を見積もってみることをおすすめします。
課金額は使用する関数や実行するタスク、使用するモデルによって異なるので、ドキュメントを参照してください。
ML.UNDERSTAND_TEXT (テキスト分類、感情分析ほか)
ML.TRANSLATE(テキスト翻訳)
ML.GENERATE_TEXT(テキスト生成)、ML.GENERATE_TEXT_EMBEDDING(文章類似度評価〜クラスタリング)
以下では、参考までにテキスト分類を行った場合についてシミュレーションしてみます。
テキスト分類の場合、ドキュメントによると毎月3万文字までは無料、3万文字〜25万文字であれば1,000文字あたり$0.002 とのことです。
従って、25万文字入力した場合の料金は $0.44、$1 = 150円として66円になります。
なお、25万文字〜500万文字では $0.0005 / 1,000 文字ユニットですので、500万文字入力した場合は422.25円になります。
まとめ
今回は BigQuery ML の自然言語処理機能について見てきましたが、事前準備設定がやや面倒なものの他の機械学習機能と同様に簡単に試すことができ、さらに扱えるタスクの幅も広いことがお分かりいただけたと思います。
いわゆる生成AIをはじめとして近年の自然言語処理技術の発展スピードは目を見張るものがありますが、BigQuery でも最新技術を取り込んだ新規機能の公開や機能追加が頻繁に行われています。
実際、直近1~2週間だけでも text embedding 機能 とテキスト生成の gemini-pro モデルが GA (Generally Available) になりました。
今後の動向も引き続き注視していきましょう。