
バイクでツーリングしながらChatGPTと会話したい(2)

前回、Pythonのプログラムを動作させる環境を作るところまで行いました。
今回は動作チェックまで行っていきます。
Open AIでアカウントを作成(前回)
VOICEVOXをインストール(前回)
Pythonの環境を整える(前回)
コード書く(今回)
動作チェック(今回)
バイクでツーリングしながら試してみる(次回)
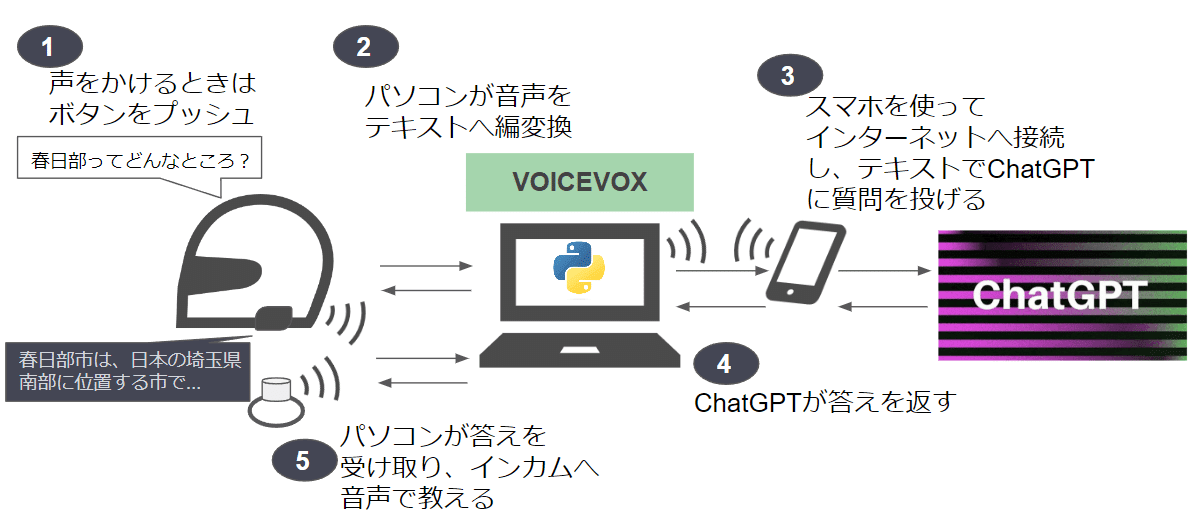
4.コードを書く
今回は、コードを書くところから行います。
コードは、下記のサイトを参考にさせていただきました。
そのままコピーして使わず、私の環境とコスト、趣味の観点から下記のところを修正しました。
音声認識キーを「alt」から「b」に変更
ボタンデバイスで、押しっぱなしが認識できるのはキーボードの「b」に当たる「BLACK OUT」ボタンだけしかなかったため、「b」ボタンを押しているときだけ音声入力を受け付けるように修正。
API Keyは環境変数から読み込むように変更
なんとなくセキュリティ的にこの方が良いかと思い。
langchainは使わないように修正
langchainを使うと過去のやり取りを踏まえた会話をすることができるのですが料金が高くなる傾向になるため、使わないように修正しました。
ChatCPTのモデルをGPT-3を明示的に使うように修正
こちらの方がなんとなく反応が返ってくるのが早い感じがしたため。
気のせいかな・・・。
他にも名前や性格付けをなくしてみたり、声を冥鳴ひまりから春日部つむぎに変更しました。
具体的なコードはこちら
というわけで、下記のようにコードを修正しました。
ChatGPTさんに教えてもらいながら。
import io
import json
import keyboard
import openai
import pyaudio
import queue
import requests
import speech_recognition as sr
import threading
import time
import wave
import os
openai.api_key = os.getenv("OPENAI_API_KEY")
class PyAudioContextManager(pyaudio.PyAudio):
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.terminate()
def get_chatgpt_response(prompt):
completions = openai.Completion.create(
engine='text-davinci-003', # 使用するモデル設定
prompt=prompt,
max_tokens=2000,
n=1,
stop=None,
temperature=0.5,
)
message = completions.choices[0].text.strip()
return message
class Voicevox:
def __init__(self, host="127.0.0.1", port=50021):
self.host = host
self.port = port
def speak(self, text=None, speaker=8): # VOICEVOXのIDを設定
params = (
("text", text),
("speaker", speaker)
)
init_q = requests.post(
f"http://{self.host}:{self.port}/audio_query",
params=params
)
res = requests.post(
f"http://{self.host}:{self.port}/synthesis",
headers={"Content-Type": "application/json"},
params=params,
data=json.dumps(init_q.json())
)
# メモリ上で展開
audio = io.BytesIO(res.content)
with wave.open(audio, 'rb') as f, PyAudioContextManager() as p:
# 以下再生用処理
p = pyaudio.PyAudio()
def _callback(in_data, frame_count, time_info, status):
data = f.readframes(frame_count)
return (data, pyaudio.paContinue)
stream = p.open(format=p.get_format_from_width(width=f.getsampwidth()),
channels=f.getnchannels(),
rate=f.getframerate(),
output=True,
stream_callback=_callback)
# Voice再生
stream.start_stream()
while stream.is_active():
time.sleep(0.1)
stream.stop_stream()
stream.close()
p.terminate()
def voicevox_speak(ai_response):
vv = Voicevox()
vv.speak(ai_response)
def process_input(input_queue, exit_event):
while not exit_event.is_set():
try:
input_type, input_data = input_queue.get(timeout=1)
except queue.Empty:
continue
if input_data == "終了":
print("プログラムを終了します。")
exit_event.set()
keyboard.press('b')
keyboard.release('b')
break
chatgpt_prompt = f"User: {input_data}\nAssistant:"
response_text = get_chatgpt_response(chatgpt_prompt)
print(f"アシスタント: {response_text}")
voicevox_speak(response_text)
def voice_input(input_queue, exit_event):
recognizer = sr.Recognizer()
microphone = sr.Microphone()
def on_b_key():
nonlocal exit_event
if exit_event.is_set():
return
print("あなた(音声入力): しばらくお待ちください...")
with microphone as source:
recognizer.adjust_for_ambient_noise(source)
audio = recognizer.listen(source)
try:
text = recognizer.recognize_google(audio, language="ja-JP")
input_queue.put(('voice', text))
print(f"音声入力: {text}")
except sr.UnknownValueError:
print("音声を認識できませんでした。もう一度お試しください。")
except sr.RequestError as e:
print(f"音声認識サービスに問題が発生しました。エラー: {e}")
keyboard.add_hotkey("b", on_b_key)
while not exit_event.is_set():
print("bを押して音声入力を開始してください...")
keyboard.wait("b")
def main():
input_queue = queue.Queue()
exit_event = threading.Event()
# 音声入力スレッド
voice_thread = threading.Thread(target=voice_input, args=(input_queue, exit_event))
voice_thread.daemon = True
voice_thread.start()
# 入力処理スレッド
process_thread = threading.Thread(target=process_input, args=(input_queue, exit_event))
process_thread.daemon = True
process_thread.start()
process_thread.join()
voice_thread.join()
if __name__ == "__main__":
main()main.pyというファイル名で保存しました。
必要モジュールのインストール
Microsoft StoreでインストールしたPythonには、下記の4つのモジュールは入っていないためインストールをします。
keyboard
openai
pyaudio
speechrecognition
Visual Studio Codeのターミナルで下記のコマンドを入力してください。
pip install モジュール名
例えばkeyboardなら下記のようになります。
c:\> pip install keyboard必要モジュールをこんな感じでインストールしてください。
環境変数にAPI keyを設定
環境変数を設定する画面を開きます。
Windows11のスタートメニューから設定を選んで開いてください。
左メニューの「システム」>「バージョン情報」と選んでください。
バージョン情報画面が開いたら、関連リンクのところに「システムの詳細設定」というリンクがありますので開きます。
システムのプロパティが開きますので、画面下にある「環境変数」をクリックしてください。
システム環境変数を設定するところがあるので、「新規」ボタンをクリックして以下のように設定してください。
変数名:OPENAI_API_KEY
変数値:Open AIのサイトで取得したAPIキー
環境変数を設定したらパソコンを再起動させておいてください。
5.動作チェック
Pythonのモジュールをインストールし、環境変数を設定したら、VOICEVOXを起動させ、インカムとボタンデバイスをパソコンに接続します。
そして、このプログラムを起動させます。
Visual Sutudio Codeを使っているなら、画面左側のメニューにあるデバッグを選んでクリックしてください。
「実行とデバッグ」をクリックすると、選択されているプログラムが起動します。
ターミナル画面に下記のようにメッセージが表示されます。
bを押して音声入力を開始してください...ボタンデバイスの「BLACK OUT」ボタンが「b」ボタンとして動作します。
「BLACK OUT」ボタンを押しながら話しかけ、話し終わったらボタンを放してください。
パソコンの性能によりますが、今回使っているパソコンでは、簡単な質問なら5秒程度で返事を返してくれます(私は有料版のChatGPTを使っています)。
動作チェック中、エラーが表示され正常動作しない場合や、エラーは出ないけど動作しない場合は下記のチェックをしてください。
Pythonのモジュールが足りない。
VOICEVOXの起動忘れ。
インカムじゃないマイクがパソコンに接続されており、そちらがマイクを押させているため、インカムのマイクでは声が入力できてない。
ChatGPTが無料版の場合、混んでいるとなかなか返事が返ってこない。
ボタンデバイスの「BACK」か「NEXT」を押している。
動作することを確認したら、VOICEVOXと動作チェックしたmain.pyをパソコンが立ち上がったら自動起動するようにWindows 11に設定します。
タスクスケジューラーに設定するのが簡単化と思います。
こちらのサイトで詳しく解説されております。
ちなみにVOICEVOXのフルパスはデフォルトでは下記のようになっています。
C:\Users\{ユーザー名}\AppData\Local\Programs\VOICEVOX\VOICEVOX.exe
次回はいよいよバイクに乗りながら使ってみたいと思います。
いいなと思ったら応援しよう!
