
OpenAIのモデル活用ガイド:GPTからReasoningモデル、DALL·Eまで

OpenAIは多種多様なAIモデルを提供しており、テキスト生成や画像生成、音声認識など幅広い用途(ユースケース)に対応しています。近年は「GPT-4」や「ChatGPT」が話題を集めていますが、実はそれ以外にも「Reasoning(推論)モデル」や「DALL·E」「Whisper」といった個性的なモデル群が存在します。先日公開されたo3-miniも記憶に新しいことでしょう。これらのモデルの特徴や用途を正確に理解することで、より効果的なAI活用が可能になります。
本記事では、OpenAIドキュメントの「Models」ページをベースに、主なモデルの技術的背景や実装上のポイントを整理して解説していきます。中級者向けの記事として、APIやプログラミングにある程度慣れた方を想定していますが、初心者の方にもなるべく分かりやすい形を意識しました。

1. OpenAIの主要モデル一覧
OpenAIには多様なモデルが存在します。以下に、ドキュメントで紹介されている主なカテゴリと、執筆時点で提供されているモデルの一覧を示します。

これらの中にはさらに複数のバージョン・スナップショットが存在します。バージョンによって最大コンテキスト長や機能に違いがあるので、用途やコスト、最新の推奨事項を踏まえながらモデルを選択するとよいでしょう。
GPTファミリー & Reasoningファミリーの主なモデル

2. GPT系モデル:GPT-4oとGPT-4o-mini
2.1 GPT-4oとは
GPT-4o(“o”は“omni”を意味します)は、OpenAIのフラッグシップともいえるマルチモーダル対応の大規模言語モデルです。高い知性と汎用性が特徴で、テキスト入力だけでなく、画像入力にも対応できます。応答はテキストベースで返され、場合によっては構造化された形式(JSONなど)を生成することも可能です。
主な特徴
マルチモーダル対応:テキストだけでなく画像も入力可能。
最大128,000トークンのコンテキスト長(一部バージョンで16,384トークンまで)。
高度な推論:知識カットオフ(最新バージョンで2024年6月)以前の広範なデータを学習しており、学習済み知識が豊富。
カスタマイズ性:ファインチューニングや蒸留(Model Distillation)で用途に合わせた最適化が可能。
GPT-4oを使ったサンプルコード(JavaScript)
import OpenAI from "openai";
const openai = new OpenAI();
const completion = await openai.chat.completions.create({
model: "gpt-4o",
messages: [
{ role: "developer", content: "You are a helpful assistant." },
{
role: "user",
content: "Write a haiku about recursion in programming.",
},
],
store: true, // 例:応答を30日間保存するオプション
});
console.log(completion.choices[0].message);
ここで注目されるのは、model: "gpt-4o"がエイリアス(別名)として指定されている場合、実際には現在の最新スナップショット(例:gpt-4o-2024-08-06)が使われる点です。レスポンスでは、実際に使用されたモデルIDが返されるため、モデル管理をしやすくなる利点があります。
2.2 GPT-4o-mini:軽量版モデル
GPT-4o-miniは、GPT-4oから派生した小型モデルで、高速かつ低コストが売りです。性能面では本家より劣るものの、特定領域に絞ったタスクや大量のリクエストを処理するユースケースに向いています。
特徴
マルチモーダル対応はそのままに、計算量やコストを抑えた設計。
GPT-4oで得られた出力を蒸留して性能を近づけるテクニックが有効。
最大128,000トークンのコンテキスト長など、スペックはバージョンに応じて異なる。
利用例
チャットボットの常時稼働など、レイテンシとコストに敏感なサービス。
特定分野に特化したAIアシスタント(アプリ内サポート、QAシステムなど)
3. Reasoningモデル:o1・o1-mini・o3-mini
Reasoningモデル(推論モデル)は、単にテキストを生成するだけでなく、内部で「思考(chain-of-thought)」を行い、複雑な問題を段階的に解決する能力があります。数理的な問題や論理的推論が必要なタスクに特に強みを発揮します。
3.1 o1シリーズ
o1:強力な推論性能を持ち、最大200,000トークンもの巨大なコンテキストウィンドウを使えるのが特徴。画像入力にも対応。
o1-mini:o1を軽量化したモデル。パフォーマンスは低下するが、その分低コスト・高速。
o1-preview:プレビュー版のモデルです(o1正式版より前のリリース段階に相当します)。
3.2 o3-mini
o3-miniはo1-miniの新世代版とも言える小型推論モデルです。o1-miniより高い知能を保ちつつ、コストと速度は同等を目指しています。構造化されたアウトプットや関数呼び出しなど、開発者にとって便利な機能をサポートしていることが特徴です。
以下に一部抜粋します。
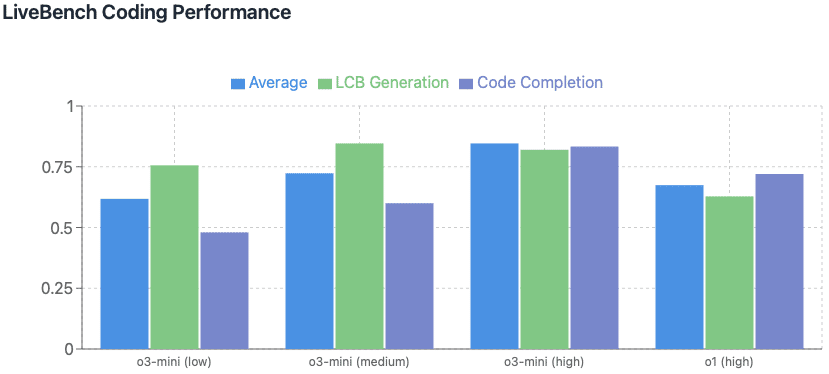

Reasoningモデルの活用例
複雑なコード生成:たとえばアルゴリズム設計や数理モデルなど、ステップバイステップの思考が必要なタスク。
数学や科学分野の課題:長い推論を要する学術的な質問に対応。
マルチステップの会話型エージェント:ユーザーが質問を追加していく形式のやりとりに対応し、適切に論理展開を保つ。
小説・ストーリーテリングへの応用:キャラクターの動機や設定、ストーリーの山場や伏線を練り込みつつ、創作に活かせる。
補足:o1 pro mode
APIでの展開がないため、本記事での解説は省略させていただきます。
4. そのほか注目のモデルと機能

4.1 GPT-4o Realtime / Audio
GPT-4o Realtime:WebRTCやWebSocketを通じてリアルタイムにテキストや音声を入出力可能。音声ベースのチャットボットや、ストリーミング形式の対話システムに有用。
GPT-4o Audio:REST API経由で音声の入出力が可能。日本語対応の拡張や音声のマルチターン会話が求められる場合などに注目。
4.2 GPT-4とGPT-3.5
GPT-4:かつて最先端と呼ばれた高知能モデル(2023年12月時点)。一部のモデルは8,192トークンが最大だが、Turbo版では128,000トークンなど大きなコンテキストにも対応。
GPT-3.5:Chat Completionsに最適化された旧世代モデル。現在はGPT-4o-miniに置き換えが推奨されるが、既存システムとの互換性などでまだ使われる場合もある。
4.3 DALL·E
自然言語のプロンプトから新規画像を生成したり、既存の画像を編集・バリエーション生成できるモデルです。DALL·E 3が最新で、解像度や実写感がかなり向上しています。
主なユースケース
ウェブサイト・記事用のイメージ素材生成
プロトタイプデザイン時のアイデア出し
広告・SNSキャンペーン用のビジュアル作成
4.4 TTS
TTS(Text to Speech)はテキストを音声に変換するモデルです。tts-1とtts-1-hdの2種類が存在し、前者はリアルタイム性を重視、後者は品質を重視しているのがポイントです。音声インターフェースやバーチャルアナウンスに使いやすいでしょう。
4.5 Whisper
Whisperは音声からテキストへの変換を行うモデルで、翻訳や多言語対応にも強みがあります。APIを介して高速化された推論を利用できるため、自前でモデルをデプロイするよりも手間を減らせるメリットがあります。
4.6 Embeddings
テキストを数値ベクトルに変換するモデル群で、ドキュメント検索やクラスタリング、レコメンデーションなど、様々なNLPタスクの基盤技術として活躍します。text-embedding-3-largeなどが最新世代です。
4.7 Moderation
有害なコンテンツや規約違反コンテンツの検出を行うモデルです。テキスト・画像両方に対応するものもあり、サービス運営上の安全対策として重宝します。
4.8 GPT base
GPT baseは、かつてのGPT-3シリーズを継承するレガシー系統です。completionsエンドポイントでのみ利用可能で、基本的にはGPT-4oやReasoningモデルのほうが推奨されます。
5. コンテキストウィンドウとトークンについて
OpenAIの各モデルには「コンテキストウィンドウ」という上限が設定されており、この範囲内で入力トークン・出力トークン・推論トークン(モデルが内部で思考に使うトークン)が合計で収まる必要があります。
コンテキストウィンドウ: 例) GPT-4oなら128,000トークン、o1なら200,000トークン など。
トークン数の見積り: Tokenizerツールなどが公式提供されており、API呼び出し前に使用すると便利です。

もしトークンが上限を超えた場合、出力が途中で切れてしまう(トランケーション)可能性があります。大量のコンテンツを扱う場合は、適宜要約を挟む・必要部分だけを抜き出すなどの対処が必要です。

補足:トークンとは何か
トークンとは、モデルに入力されるテキストやモデルから出力されるテキストを、機械学習的に処理しやすい単位に分割したものです。英語の文章であれば単語や部分的なサブワード、日本語では文節やサブワードなどに分割されます。たとえば「OpenAI」という単語がそのまま1トークンになる場合もあれば、複数のサブワードに分割されて複数トークンとして扱われるケースもあります。
OpenAIのAPIでは「1つのリクエスト内に含まれる入力トークン(ユーザーが送るプロンプトなど)+ 出力トークン(モデルが生成する応答)+ 推論トークン(モデルが内部のチェーン・オブ・ソートなどに使う分も含む)」の合計が、そのモデルの最大コンテキスト長を超えないようにする必要があります。超えてしまうと出力が途中で切れる(トランケーションされる)可能性があるので注意が必要です。
6. モデルIDとエイリアスの考え方
ドキュメントには、gpt-4oやo1などの「エイリアス(alias)」と、実際に動作しているgpt-4o-2024-08-06のような「日付入りスナップショットID」が併記されています。本番運用では日付入りスナップショットIDを固定して使うのが推奨とされています。その理由は、エイリアスは定期的に最新モデルに更新されるため、推論結果の再現性や性能面の安定性が揺らぐ可能性があるため、安定運用が難しくなります。
API呼び出し例(モデルエイリアス)
curl "https://api.openai.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4o",
"messages": [
{ "role": "developer", "content": "You are a helpful assistant." },
{ "role": "user", "content": "Write a haiku about recursion in programming." }
]
}'
レスポンスには、"model": "gpt-4o-2024-08-06"など、実際に使用されたモデルが示されます。本番環境での安定利用を重視するなら、直接gpt-4o-2024-08-06を指定する方法が良いでしょう。
7. データの取り扱いと使用ポリシー
OpenAIは2023年3月以降、API経由で送信されたデータを学習用には使用しないと明記しています(ユーザーが明示的に許可しない限り)。また、標準設定ではAPIリクエストは最大30日間保持されますが、「ゼロ・データ保持(Zero data retention)」を選択すると、リクエスト・レスポンスの本体はログに残らず、リアルタイム処理のメモリ内にしか存在しません。
主なAPIエンドポイントとデータ保持可否(例)

商用サービスで個人情報や機密情報を扱う場合は、ゼロ保持や自前の暗号化などを組み合わせ、適切なデータ保護を行うことが重要です。
8. 実践的な活用ポイント
8.1 ファインチューニングと蒸留(Distillation)
OpenAIの多くのモデルはカスタマイズが可能で、特にGPT-4oやGPT-4o-miniなどではファインチューニングや蒸留(Distillation)を行えます。たとえば大量の顧客データや専門知識を含んだドキュメントを使い、よりドメイン特化したモデルに仕上げることができます。
ファインチューニング(Fine-tuning): APIを通じてデータをアップロードし、モデルの重みを部分的に調整して独自タスクの精度を向上。
蒸留(Distillation): 大きいモデル(例:GPT-4o)が生成した出力をデータセット化し、小さいモデル(GPT-4o-mini)に学習させて近似性能を実現。

8.2 モデル選択の基準
タスクの内容: 会話・文章生成がメインなのか、数理推論なのか、画像生成なのかでモデルが変わる。
コストと速度: 大規模モデルほど高性能だがコスト高。大量リクエストならミニモデルが向く。
コンテキスト長: 長文を扱う場合はコンテキストが十分大きいモデルを選択。
安定性: 研究目的なら最新エイリアス、本番運用なら日付スナップショットを利用。
8.3 APIリクエスト設計のポイント
トークン数の管理
事前にテキストを分割したり、要約機能を組み合わせるなどしてコンテキストウィンドウを越えないようにする。
エラーハンドリング
トランケーションやAPIリミット超過など、異常系を考慮。HTTPステータスコードやエラーメッセージを検知して再試行やログを記録する。
モデルのバージョン指定
再現性が重要な場合は日付入りスナップショットIDを明示する。
9.レートリミットと利用者階層(Usage Tier)の仕組み
9-1 レートリミットとは
以下の理由で制限が課せられています。
APIの安定稼働
不正使用や過度なリクエスト集中を防ぎ、サービス全体を安定稼働させるため。公平なリソース分配
一部のユーザーによる大量リクエストでほかのユーザーが影響を受けないようにする。インフラ負荷の管理
サーバの負荷増大を抑制し、全ユーザーへ一貫したパフォーマンスを提供する。
レートリミットの指標
OpenAIのAPIでは、主に以下の指標が用いられます。
RPM (Requests Per Minute): 1分あたりのリクエスト数上限
RPD (Requests Per Day): 1日あたりのリクエスト数上限
TPM (Tokens Per Minute): 1分あたりに処理できるトークン数上限
TPD (Tokens Per Day): 1日あたりに処理できるトークン数上限
IPM (Images Per Minute): 1分あたりに生成・処理できる画像数上限(DALL·Eなど)
どの指標の上限に先に達しても利用が制限される点に注意してください。たとえば、RPMが20なら、1分間に20回のリクエストを行った時点で制限に到達し、たとえトークン数の余裕があっても追加リクエストを送れなくなります。
9-2 Usage Tier(利用者階層)とは
利用者階層(Usage Tier)は、ユーザー・組織ごとに割り当てられた月間利用限度額(Usage Limit)に応じて分かれています。支払い実績や利用実績に応じてティアが自動で上がり、それに伴いレートリミットの上限も緩和されます。

ティアが上がるとAPIの呼び出し回数やトークン処理量の制限枠も拡大。
さらに高い利用量が必要な場合は、ダッシュボードのLimits設定画面からリミット引き上げを依頼できます。
9-3 Tier別のレートリミット例
以下は主要Tier(Free, Tier 1 など)での一例です。実際にはモデルごとに異なる上限が設定されており、アカウント設定のレートリミットページから正確な値を確認できます。
9.3.1 Free tierの例

9.3.2 Tier 1の例

9.3.3 上位ティアの例(Tier 5など)

このように、ティアが上がるとリクエスト数(RPM)やトークン数(TPM)などの制限が大幅に緩和されるのがポイントです。
9.4 レートリミットを超えそうな場合の対処法
9.4.1 エラー回避の基本
リトライ戦略(Exponential Backoff)
レートリミットを超えた際、自動的に一定時間待機してから再リクエストを行う。
Pythonではtenacityやbackoffライブラリを利用すると簡単に実装可能。
max_tokensを適切に設定
必要以上に大きいmax_tokensを指定しない。
レスポンスサイズに見合ったトークン数にすることでTPMの過剰消費を防ぐ。
9.4.2 Batch APIの活用
リアルタイム処理が不要な場合、Batch APIを使って一括処理。
同時に多数のリクエストを送るよりも、まとめて送ってサーバ負荷を軽減する方が安定性を高めやすい。
9.4.3 高いティアへの昇格
使用実績に応じて自動または手動でより高いティアに移行でき、レートリミット枠が増加します。
大量にリクエストが必要なケースや、ビジネス規模が拡大しそうな場合は事前に準備しておくと安心。
9.5 レスポンスヘッダーでのリミット確認
API呼び出しのレスポンスヘッダーには、現在のレートリミット状況を示す以下のようなフィールドが含まれます。
x-ratelimit-limit-requests (設定されている最大リクエスト数)
x-ratelimit-remaining-requests (残リクエスト数)
x-ratelimit-reset-requests (リセットまでの残り時間)
など
これらを参考にリアルタイムでリミット消費状況をチェックしながら、アプリケーション側でリトライタイミングやキューイングを管理できます。
10. まとめと今後の展望
本記事ではOpenAIのモデル一覧を「GPT系」「Reasoning(推論)系」「DALL·E」「TTS」「Whisper」「Embeddings」「Moderation」「GPT base」とカテゴリに分け、それぞれの特徴や使いどころを紹介しました。また、コンテキストウィンドウやデータの取り扱い、モデルIDの管理、APIのレートリミットなど、実務で注意すべきポイントにも触れました。
OpenAIは新機能やモデルを頻繁にアップデートしており、今回紹介した日付入りスナップショットも将来的に更新される可能性があります。特にリアルタイム音声対応やマルチモーダル対応は、今後さらなる発展が見込まれます。最新動向を追いつつ、実際にAPIを使って試してみることをおすすめします。
今後のポイント
大規模推論モデルの一般化:ReasoningモデルやGPT-4oの能力が統合・強化される動き。
マルチモーダルのさらなる拡張:テキスト・画像・音声だけでなく、動画やセンサー情報などへの対応も視野に。
プライバシー・セキュリティ:企業利用や個人情報保護においてAPIやデータ保持ポリシーがより厳しくなる可能性。
ぜひOpenAIの公式ドキュメントやサンプルコードを参照しながら、本記事の情報を活かしてみてください。適切なモデルを選択し、ファインチューニングやスナップショットID管理を組み合わせれば、さまざまな場面で高性能なAIアシスタントやシステムを実現できます。
必要・不要に関わらず、実際に作って試してみることは良い学びの機会になるでしょう。以下の記事にもあるように、勉強になります。
参考リンク
記事中のリンクおよび、下記リンク、ドキュメントを参考にしています。