
夜に駆けるのTalkboxミックス(前処理編)

Yoasobiさんの夜に駆けるをカバーしました。
たまにしかミックス作業をやらないので備忘録としてミックス作業を残しておきます。DAW は Ableton Live 11 を利用し、ミックスは Ableton Live ビルトインプラグイン + Waves プラグイン、マスタリングは iZotope Ozone 9 を利用しました。
お願い :これはTalkboxもミックスもド素人が書いた単なるメモです。常識から外れたおかしな事もたくさん言っていると思います。私を信用せずあなた自身の知識と耳を信用してください。そしてもし優しい方がいれば私にヒントを教えてくださるとうれしいです。
レコーディングまで
インスト
まず、インストトラックは公式のものを利用させていただきました。改変しなければYoutubeへの投稿が可能なようです(2022/7現在)。毎回カラオケを作るのがとても大変だったので高品質のトラックを公式に提供いただきとても感謝しています。
レコーディング
ボーカルトラックは自宅録音をしました。録音をかなりミスっており、生データは聴くに堪えません。主な反省点はうめき声(短いゲップ?)のようなものが入ってしまったこととペチャクチャ音を拾い過ぎてしまったことです。今回は両耳をモニターヘッドフォンでふさぎながら録音しましたが、次回からは片耳はイヤホン、片耳は口から出る音を直接聞く方法でやってみようと思います。自分の今の実力ではモニターの返りの音を聴きながらだとどうしてもベストパフォーマンスは出せなさそうです。
録音環境は以下です。
場所:自室
マイク: MXL 2003A
ショックマウント:マイク付属品(もうボロボロ)
ポップガード:STEDMAN PROSCREEN101 メタル
リフレクションフィルタ:marantz Professional SOUND SHIELD
インターフェース:steinberg UR242
素の音はだいぶこもっているように聞こえます。そもそもこれが素の音として適切なのか、適切でないなら何が原因かがわからないですね。。いろいろと一気に買いそろえる余裕がそんなにないので少しずつ検証していきたいと思います。
事前準備
ミックスの事前準備として以下を行いました。
1. ベストテイクのつなぎ合わせ
2. ノーマライズ処理
3. ディエッサー処理(地獄の手コンプ)
1. ベストテイクのつなぎ合わせ
今回のレコーディングはどのパート(1番、サビ、2番とか)も1回で録ったので単にそれぞれのテイクをつなぎ合わせて1つのオーディオファイルにしただけです。また、このタイミングで音が鳴っていない部分は全てカットしておきます。Talkboxの場合、モジュレーションホイールでビブラートをかけて音が鳴り終わったあとにホイールを戻す音が入ってしまっているため特にその部分は注意して処理をします。
2. ノーマライズ処理
後の処理をやりやすくするためここで一旦ノーマライズしておきます。Ableton Live でもノーマライズできるようですが、やり方を忘れてしまい、Audacity で処理しました。Ableton Live の場合には書き出すタイミングでノーマライズができるので次回は忘れずに Live でやります。
3. ディエッサー処理
ここでディエッサー処理をします。Talkbox は特性上子音を強く発音するためどうしても s, t の音が強く出過ぎてしまいます。ディエッサーのプラグインで処理してもいいのですが、プラグインで処理すると細かな部分まで行き届かないので手動で処理を行います。これを手コンプ(手動コンプレッサー処理)と言います。
手コンプで調べるとまず Waves Vocal Rider が出てきます。これはボーカルに特化したゲインコントロールです。しかしこれはディエッサー処理ではなくボーカル全体のコントロールです。また、「手コンプは時間がかかりすぎる、どうせコンプはかけるのだからアタックタイムをいじって子音部分のコントロールをすべきだ」といった主旨の主張も見かけます。しかし、Talkboxは特性上子音は通常歌うよりも強く発音するものでありむしろ抑えるべきもの、またチューブを咥えているためにより小さくなってしまう子音はミックスで強調したいといった事情があるため手コンプに頼らざるを得ない現状があると思います。ここが通常のボーカル処理と大きく異なる部分です。もっともTalkboxの腕が上がればこの負担は減るものかもしれませんが。
手コンプだけではどうしても耳障りな部分が残ってしまうため、この後のミックス時にディエッサープラグイン Waves Sibilance を噛ませました。Sibilanceで削った後に手コンプで微修正したほうが効率的で音もよくなる気がします。これは次回の検証課題として覚えておきたいと思います(たぶん忘れて同じことやる)。
オートメーションの基本的な方針は以下です。※もちろん音のつながりやプレーヤーの発音の癖があるので一概には言えません。
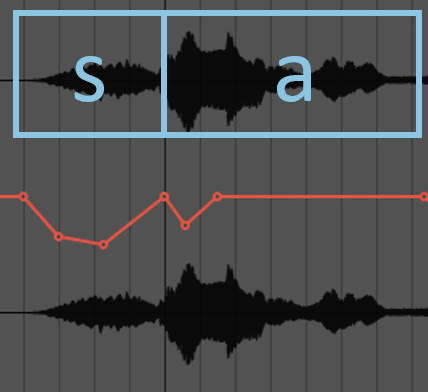
s, t の部分だけゲインを下げます。例えば1番の「さよならだけだった」の「さ」の "s" の部分だけをゲインを下げます。
"a" の部分は聞こえ始めの一瞬だけちょっと下げてあげることで音の輪郭がはっきりするような気がします。
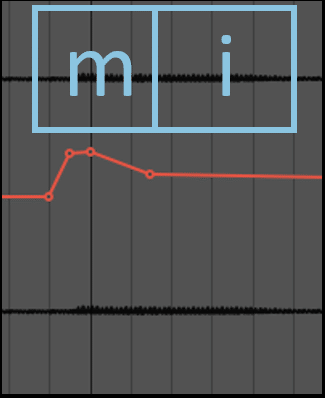
m, n の部分はゲインを上げます。m, n は口を閉じるのでマイクではなかなか拾えないためです。
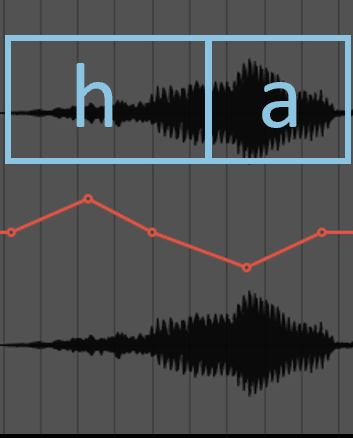
h, f も基本的にはゲインを上げます。ただし、これらの子音は他に比べて音価が長いのでがっつり上げるというよりもメリハリをつけて色付けしていくのがよいと思います。
k については後ろの母音毎に傾向が異なります。例えば、ka の "k" はゲインを下げますが、逆に ko の "k" はゲインを上げます。個人的に思っていることで何の裏付けもありませんが、ka, ki の "k" は尖っていて ku, ke, ko の "k" は少しやわらかいイメージですかね。

他にも ラ※ の子音は持ち上げるなど tips はありますが、最終的にはプレーヤーの癖と歌詞中の音のつながりに依存するため全ては紹介しません。ここで述べたいことは自分の耳で聞いて1音1音地道に処理するということです。
※日本語のラは la とも ra とも言い切れないためカタカナ表記としています。
最終的にはこんな感じになります。めちゃくちゃ大変です。
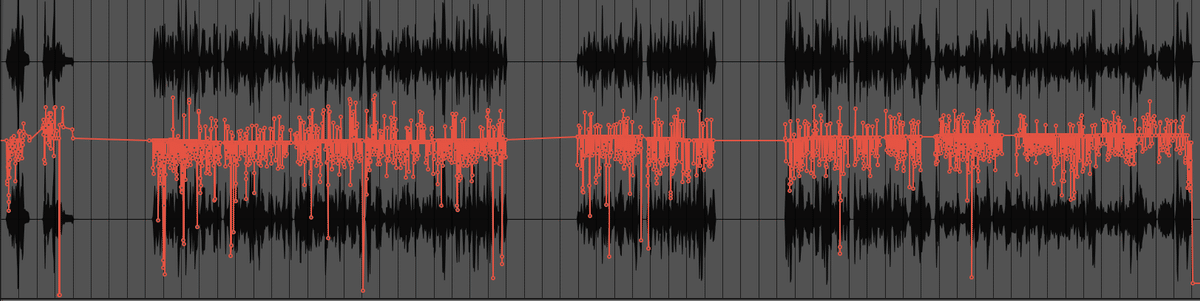
この処理が終わったら一旦オーディオファイルに書き出して前処理は終了です。次回はミックス編を書こうと思います。
ミックス編はこちら