
マッチングサイトpython集計分析最終章~女性を引き寄せる男子部屋を作成する~

前回の記事はこちら
前回男子部屋で女性が入室する方が連絡先の交換率などが高いことが分かったため、今回は最後の難関である女性が入室しやすい男子部屋を作る方法について分析したい。
1、空室含めて部屋情報を抽出するスクリプトを作る
まず、これまで空室の部屋情報を取得してなかったので、空室/満室に関わらず部屋情報を自動的に抽出するためのスクリプトを作成する。今回は時間や日付も重要な要素になってくるので、取得日時の列も追加した。
#ライブラリのインポート
import requests;
from bs4 import BeautifulSoup;
#始めに空のDataFrameを作成。
import pandas as pd
import datetime
import time
import csv
room_df = pd.DataFrame(index=[], columns=['room_id','sex','age','introduction','status','datetime-utc'])
#空のリスト(room)
nos = []
room_ids = []
sexes=[]
ages=[]
introductions=[]
statuses=[]
dts=[]
no = 0
#対象要素の属性値取得
def print_roominfo(no):
room_rows = soup.select("tr.roomcol")
for room_row in room_rows:
#room_id取得
room_id = room_row.find('input', {'name':"room_id"})['value']
#性別取得
room_elements = room_row.select("td")
sex = room_elements[3].text
#年齢取得
age = room_elements[4].text
#紹介文・ステータス取得
if room_row.find("td", {"class": "wait"}):
introduction = room_elements[5].text
status = 1
else:
introduction = room_elements[5].select("span")[-1].text
status = 0
dt = datetime.datetime.now()
no += 1
nos.append('{:0=3}'.format(no))
room_ids.append(room_id)
sexes.append(sex)
ages.append(age)
introductions.append(introduction)
statuses.append(status)
dts.append(dt)
return no
def main():
while True:
t1 = time.time() #経過時間確認用
for num in range(1, 21):
url = "http://chat.shalove.net/g/kanto/vsex/1/vnonpub/2/pageID/" + str(num) + "/"
res_room = requests.get(url)
soup = BeautifulSoup(res_room.content, "html.parser")
no = print_roominfo(no)
time.sleep(1)
for num in range(1, 5):
url = "http://chat.shalove.net/g/kanto/vsex/2/vnonpub/2/pageID/" + str(num) + "/"
res_room = requests.get(url)
soup = BeautifulSoup(res_room.content, "html.parser")
no = print_roominfo(no)
time.sleep(1)
new_room_df = pd.DataFrame({'room_id':room_ids, 'sex':sexes, 'age':ages,'introduction':introductions, 'status':statuses, 'datetime-utc':dts})
room_df = pd.concat([room_df, new_room_df])
room_df = room_df.groupby('room_id',as_index=False).min().reset_index(drop=True)
room_df.to_csv("mens-womens_room.csv")
print(room_df)
#経過時間確認用
t2 = time.time()
elapsed_time = t2-t1
print(f"経過時間:{elapsed_time}")
#空のリスト(room)
nos = []
room_ids = []
sexes=[]
ages=[]
introductions=[]
statuses=[]
dts=[]
no = 0
if __name__=="__main__":
main() これを5/25~6/4の約10日の間動かしてみたところ、

25万部屋もの部屋が作られているようだ。なんと、ラブルームでは1日で2万部屋も開設されているということが分かった。
2、女性が入室しやすい時間帯を探る
取ってきたデータからまず日別×時刻別で部屋の状況を集計して、女性が入りやすい時間帯を探ってみる。
#fullかどうかの列を追加(fullが1の場合が入室あり)
mens_womens_room_df.loc[mens_womens_room_df['status']==1,'full']=0
mens_womens_room_df.loc[mens_womens_room_df['status']==0,'full']=1
#時間をUTC→JSTに変換
import datetime
mens_womens_room_df['datetime_jst'] = pd.to_datetime(mens_womens_room_df['datetime-utc'], utc=True)
mens_womens_room_df['datetime_jst'] = mens_womens_room_df['datetime_jst'].dt.tz_convert('Asia/Tokyo')
mens_womens_room_df['date'] = mens_womens_room_df['datetime_jst'].dt.date
mens_womens_room_df['time'] = mens_womens_room_df['datetime_jst'].dt.time
mens_womens_room_df['hour'] = mens_womens_room_df['datetime_jst'].dt.hour
#見やすいように列を選別
mens_womens_room_df_dt = mens_womens_room_df[['room_id','sex','age','introduction','date','hour','full']]
#男子部屋と女子部屋の抽出
mens_room_df = mens_womens_room_df_dt[mens_womens_room_df_dt['sex']=="男"].copy()
womens_room_df = mens_womens_room_df_dt[mens_womens_room_df_dt['sex']=="女"].copy()
#日別×時間別で部屋の数と満室数を集計
all_rooms_dt = mens_womens_room_df_dt.groupby(['date','hour'])['full'].agg(['count','sum'])
mens_rooms_dt = mens_room_df.groupby(['date','hour'])['full'].agg(['count','sum'])
womens_rooms_dt = womens_room_df.groupby(['date','hour'])['full'].agg(['count','sum'])部屋の開設数は↓のようになった。
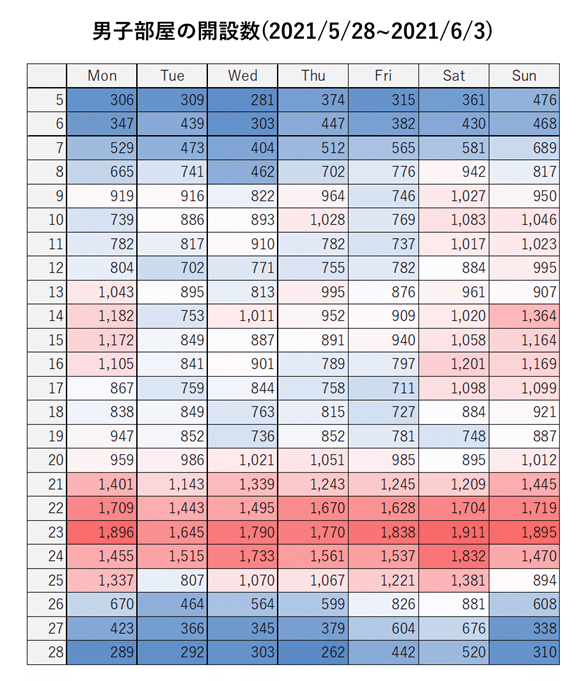
21時台~1時台がラブルームの部屋数が増えるピークタイムであることが一目で分かる。あとは月、土、日の昼下がりにも比較的多くの男性が集まっているようだ。
続いて同じ考え方で曜日×時間帯別で満室率を見てみる。
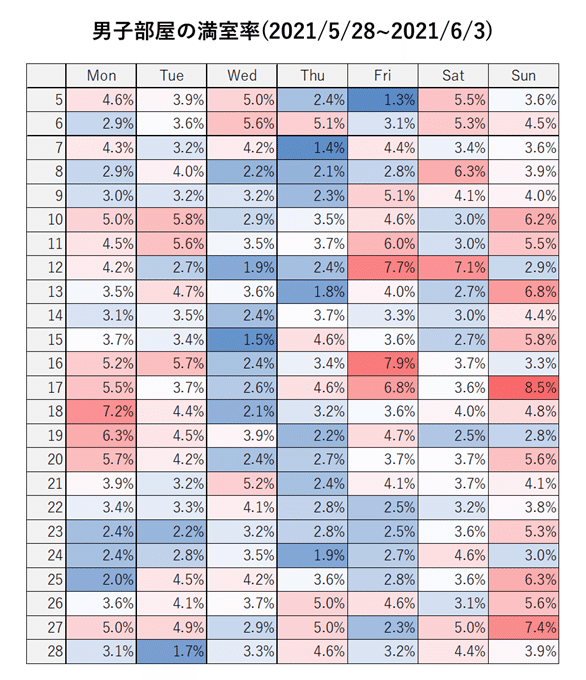
ピークタイムの21時~1時は比較的満室率が低いことがわかるので、にぎわっている時間に部屋を開設するやり方は得策ではなさそうだ。
という訳で、最後に開設数と満室率の二つを組み合わせて、穴場の時間帯を探ってみる。

どうやら金曜の16時台〜17時台の時間帯が、男子部屋の開設数が少なく、満室率が高いようだ。
これはいわば「競争相手の男性が少なく」「女性の入室率が高い」ということなので、この時間帯を狙って部屋を開設すれば、女性とマッチする確率が高い、ということだ。
ラブルームで男子部屋を開設するなら、金曜の16時台〜17時台が狙い目
ということが分かった!
3、女性が入室しやすい紹介文を探る(機械学習によるモデル作成)
続いて部屋を開設する時にポイントになるのが、紹介文をいかに魅力的に書くかである。女性から見たときに目に入るのはほとんど紹介文だけなので紹介文が勝負の分かれ目になる。

今回は紹介文のテキストから入室確率を判別するモデルを機械学習で作成する、という挑戦を偉大な先人の記事を見ながら行ってみた。
参考リンク:自然言語処理を用いたデータの分類
# Mecabのインストール
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null
!pip install mecab-python3 > /dev/null
# シンボリックリンクによるエラー回避
!ln -s /etc/mecabrc /usr/local/etc/mecabrc
# 辞書(mecab-ipadic-NEologd)のインストール
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1
path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd"
!echo `mecab-config --dicdir`"/mecab-ipadic-neologd"
#紹介文の形態素解析を行う
mens_introduction = mens_room_df["introduction"]
import MeCab
# インスタンスの生成
mecab = MeCab.Tagger(path)
# 区切ったレス群ごとに形態素解析を実行
chasen_list = [mecab.parse(sentence) for sentence in mens_introduction]
#chasen_listの中身を確認。
#空のリストを作っておく。
word_list = []
word = ""
i=0
# ノイズ(不要品詞)の除去
for chasen in chasen_list:
for line in chasen.splitlines():
if len(line) <= 1: break
speech = line.split()[-1] ## 品詞情報を抽出
if "名詞" in speech:
if (not "非自立" in speech) and (not "代名詞" in speech) and (not "数" in speech):
word = word + line.split()[0] + " "
word_list.append(word)
word = ""
i = i+1
mens_room_df['word_list']=word_list
#モデルの精度を上げるため重複した紹介文をカット
mens_room_unique = mens_room_df.drop_duplicates(subset='introduction')
##ここからがモデル作成の作業##
#Vec化
vectorizer = TfidfVectorizer(use_idf=True, token_pattern=u'(?u)\\b\\w+\\b')
vecs = vectorizer.fit_transform(mens_room_unique.word_list)
vecs
#2,000次元に次元削減
skb = SelectKBest(k=2000)
res2 = skb.fit_transform(vecs,mens_room_unique.full)
res2
#訓練用とテスト用に分割。データ量が多すぎたので訓練用データの割合を0.1とした。
vecs2_train, vecs2_test = train_test_split(res2, random_state=0,train_size=0.1)
y_train, y_test = train_test_split(mens_room_unique.full, random_state=0,train_size=0.1)
#ライブラリのインポート
from sklearn import svm
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
from sklearn.metrics import confusion_matrix
#rbfは固定でgammaとCは色々試してみる。
svm_tuned_parameters = [
{
'kernel': ['rbf'],
'gamma': [0.05,0.1,0.5],
'C': [5,20,40,60],
'probability':[True]
}
]
gscv2 = GridSearchCV(
svm.SVC(),
svm_tuned_parameters,
cv=5, # クロスバリデーションの分割数
n_jobs=1, # 並列スレッド数
verbose=3 # 途中結果の出力レベル 0 だと出力しない
)
#list化した上で学習開始
y_train_list = y_train.tolist()
gscv2.fit(vecs2_train, list(y_train_list))
# 最も精度の良かったモデルのパラメータを代入
svm2_model = gscv2.best_estimator_
print(svm2_model) #パラメータを念のためプリントクロスバリデーションとグリッドサーチを組み合わせて機械学習を行い、最終的に↓のようなパラメータを持ったモデルがベストだと判断された。

これを実際のデータに当てはめて予測の精度を確認する。
#ROC曲線
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
y_pred = svm2_model.predict(vecs2_train)
# AUCの算出
fpr, tpr, thresholds = roc_curve(y_train_list, y_pred)
roc_auc = auc(fpr, tpr)
# ROC曲線の描画
plt.plot(fpr, tpr, color='red', label='ROC curve (area = %.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='black', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('Receiver operating characteristic')
自分でも何をやっているか半分くらいしか分かっていないが、結論として精度が低いモデルが生成されてしまった。
左上に記載がある0.57という数字(AUC)が0.7以上であれば良いモデルと言えるのだが、ランダムに予測した時の精度である0.5に近しいモデルになった(つまり、適当に予測してるのとほぼ同じ)。
4、女性が入室しやすい紹介文を探る(autoMLを使った高度な機械学習)
途方に暮れて色々と調べた結果、Google Cloud PlatformのautoMLなるものを使えばより高度な機械学習が簡単に出来ることが判明した。しかも紹介文と満室or空室の情報を組み合わせたファイルをアップロードするだけで勝手に自然言語解析を行なってくれるという優れものである。google様やっぱりすごい。。(ちなみに、今回は無料体験枠で実装した。本来はお金がかかるみたいだ。)
参考リンク:AutoML Natural Language を使って文豪っぽさを推定する
↓のような感じで「紹介文, 空室(empty)/満室(full)」の2列のcsvを作ってGoogle Cloud Platformに上げる。


あとは、「トレーニング」ボタンを押して5時間ほどgoogleに学習してもらうだけ、という何とも素晴らしい方法で空室/満室の予測モデルが完成した。

もはや機械学習の中身は分からないが笑、それっぽいモデルができたので、これを紹介文の魅力を判定するモデルとして採用することにした。
4、女性が入室しやすい紹介文を作る
googleで作ったモデルに試しに思いついた紹介文を入力してスコア判定を行ってみた。

こんな感じで紹介文に対してスコアが付く。
同じ要領で思いついた紹介文を片っ端からスコア判定していく。

色々書いてみたが、この中で最も女性の入室確率が高そうな紹介文は、
高身長、高学歴、高収入のエリートサラリーマン。今夜東京で夜景デートしませんか?
ということが分かった!
5、いよいよラブルームで実践!
ここまで1ヶ月以上をかけて全ての週末を潰してラブルームの研究に明け暮れてきたが、ついに実戦の瞬間を迎えることができた。
きたる2021年6月11日の金曜日16時台を見計らって、ルーム開設を行った。

・・・・・・
・・・・・
・・・・

・・・
・・
・

〜完〜
6、まとめ
1ヶ月以上をかけて行ってきたラブルーム分析はルーム閉鎖を告げるアラームと共にあっけなく幕を閉じた。
ただ、女性には出会うことができなかったが、ラブルームを分析する過程で偉大な先人達の記事やGoogleやAmazonの素晴らしいツールと沢山出会うことができた。
女性との出会いよりも大切な出会いがたくさんあった、と言っても過言ではないだろう。
そして、最後に、もしこのnoteを見ている女性がいれば、
高身長、高学歴、高収入のエリートサラリーマン。今夜東京で夜景デートしませんか?
ご連絡お待ちしております。