
手描きと AI 描画を Loopback して行うキャラ描画 【Case B】

English Version: https://medium.com/@neoclassicalribbon/character-drawing-using-hand-drawing-and-ai-loopback-methodology-case-b-3c4e26430f0c
概要
前回の記事に引き続き、手作業と AI 描画を反復しながら画を完成させる。
今回は 3D を使用してリアル系のスタイルで描画することを目指した。
また、背景とキャラを両立させる方法や、部分的な再描画でディテールを描きこむ手法も試した。
以下に各段階での作業結果を示す。

目的
手作業と AI を反復して、意図したキャラや構図での描画を行いたい。
前回の記事と異なるのは、3D を使用してより確度の高いキャラ指定を行うこと、背景も含めて構図を作りながら AI で生成させることである。
ワークフロー解説
1. 3D 制作
東方 Project より八雲紫を作成する。
Daz Studio, Blender, Marvelous Designer を使用してベースになるモデルを作った。
顔のみ手書きで調整した。

傘を持つポージングや衣服の翻りなどは AI での再現が難しい部分なので、確度の高いモデルを作るようにした。
ここで作ったシルエットは CN Lineart によって最後まで固定するので、きちんと詰めておく。
漂うドレスの合間から覗くオーバーニーと素肌の境に現れる水平線は、スキマ妖怪・境界の妖怪である彼女を表現するのにまったく相応しいものであり、しっかりキープしながら仕事を進めたい。
(後付けである。ただの性癖だ)
逆に、マテリアルについては AI によって模様も含めて生成する計画なので、ごく簡単に済ませた。
2. 背景の描画
失敗例
最初に前段で作成した画像を CN Tile と Lineart に入れて、再描画を行った。
しかし、どれだけパラメータや Prompt をいじってもさっぱり思ったような画像が出てこない。

結局 AI 任せにするだけでは所望の背景は生成できないと考え、手作業で背景の下絵を作ることとした。
手作業による入力画像の作成
素材サイトなどから集めた画像を配置しておおまかに背景を作った。
今回も技術研究のためのフェアユースとして見逃してほしい。
この時点でライティングにも大まかな方向性を与えている。

筆者の画像編集能力の乏しさからどうにもイマイチなコラージュだが、とりあえず先に進むこととする。
なお、手順が前後してしまうが、後程述べる傘のディテールアップを先に実施してから合成している。
3. AI による一次描画
下絵の準備ができたところで、全体を AI によって再描画させる。
下絵を i2i, CN Tile, Lineart, Normal に入れる。
i2i を使用することで、"Denoising Strength" と Tile の "Weight" の組み合わせによる元画像への忠実度のコントロールが可能になる。
CN Tile の Preprocessor には tile_colorfix を使用した。
Lineart ではキャラと背景の線画が混ざってしまわないよう、キャラのみの画像を入れている。
背景が黒いと潰れてしまう部分があったため、線画を検出しやすいよう Input の背景は灰色とした。
再描画の余地を大きくするために Tile の Weight をやや下げる関係上、Normal を追加して全体の構図が保たれるようにした。
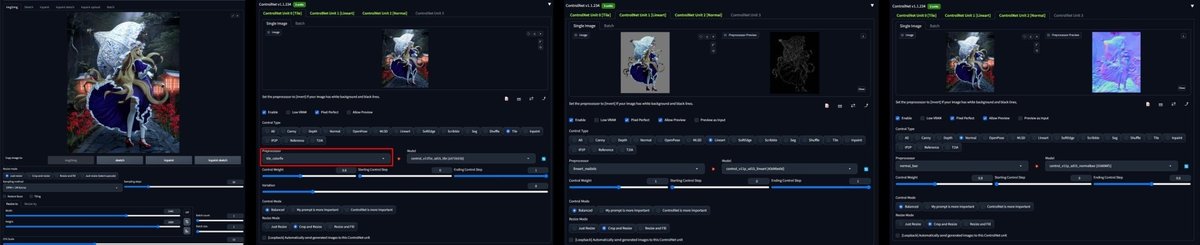
モデルには MajicMix Sombre v2.0 を使用した。
絵柄 LoRA として、The forest light, Soda Girl, 百花酿 を用いた。
Prompt はキャラの特徴を示すタグと、背景の情報を追加した。
また、前回の記事同様、絵柄への影響を懸念してキャラクター LoRA は使用せず進めることとした。
ただ、今回は公式衣装準拠のデザインなのでキャラ LoRA を使ってもよかったかもしれない。
工程を通じて Majic Mix モデル作者の推奨する CFG Scale Fix Plugin を有効にしている。
何枚か作成した後、Photoshop に読み込んで良い部分をピックアップしながら Mask で合成した。

4. 部分的なディテールアップ
キャラを表現するのに特に重要になる顔と手については、部分的に再描画してディテールと正確性を上げる。
また、最初の 3D 画像では、傘が広い面積を持つ割に書き込みに乏しく、スカスカした印象を受ける。
この点についても AI で模様を生成させることで解決を試みる。
顔
前段までで作った画像を i2i, CN Tile に入力した。
Lineart には引き続き灰色背景の 3D 元画像を入れる。
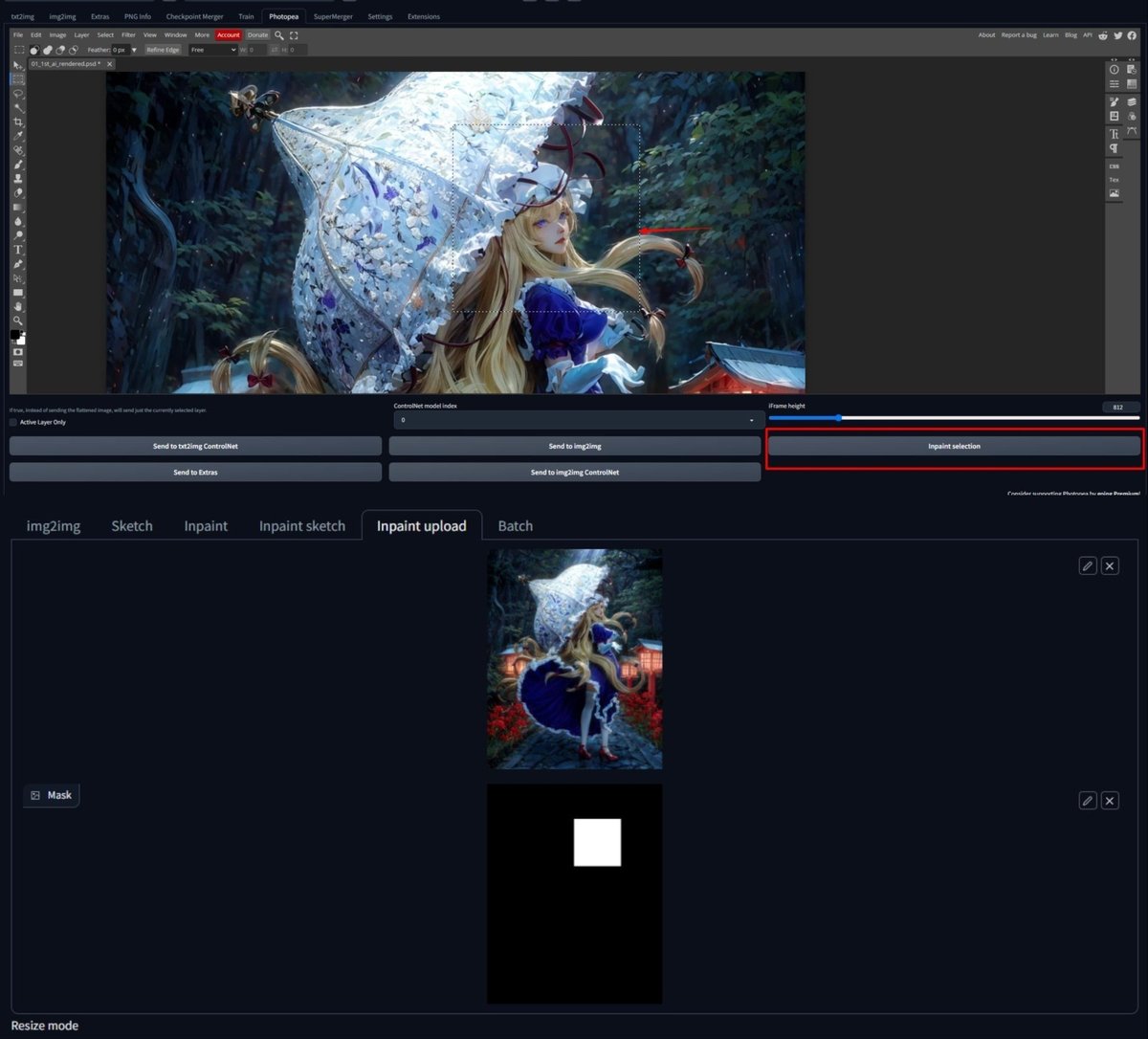
書き直す領域は Photopea Plugin で顔の周辺に矩形領域を作って、inpaint に送った。
Control Net については、マスクした領域の部分が自動的に切り取られて使用されるため、矩形領域に合わせるような操作は必要ない。
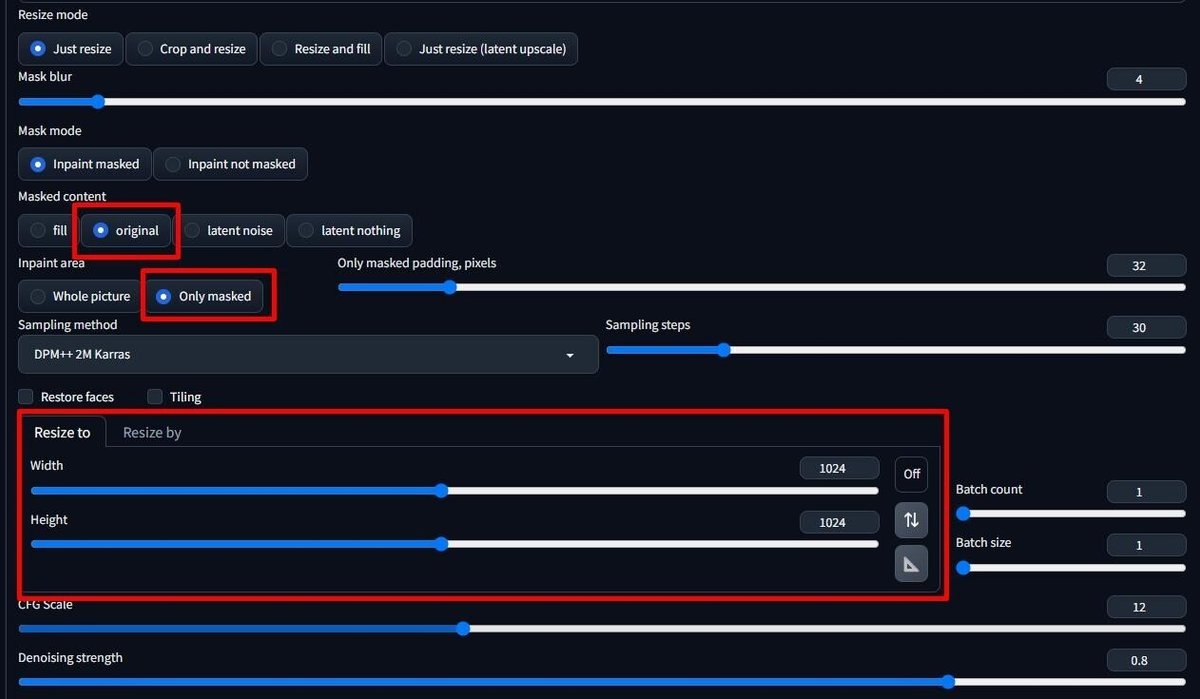
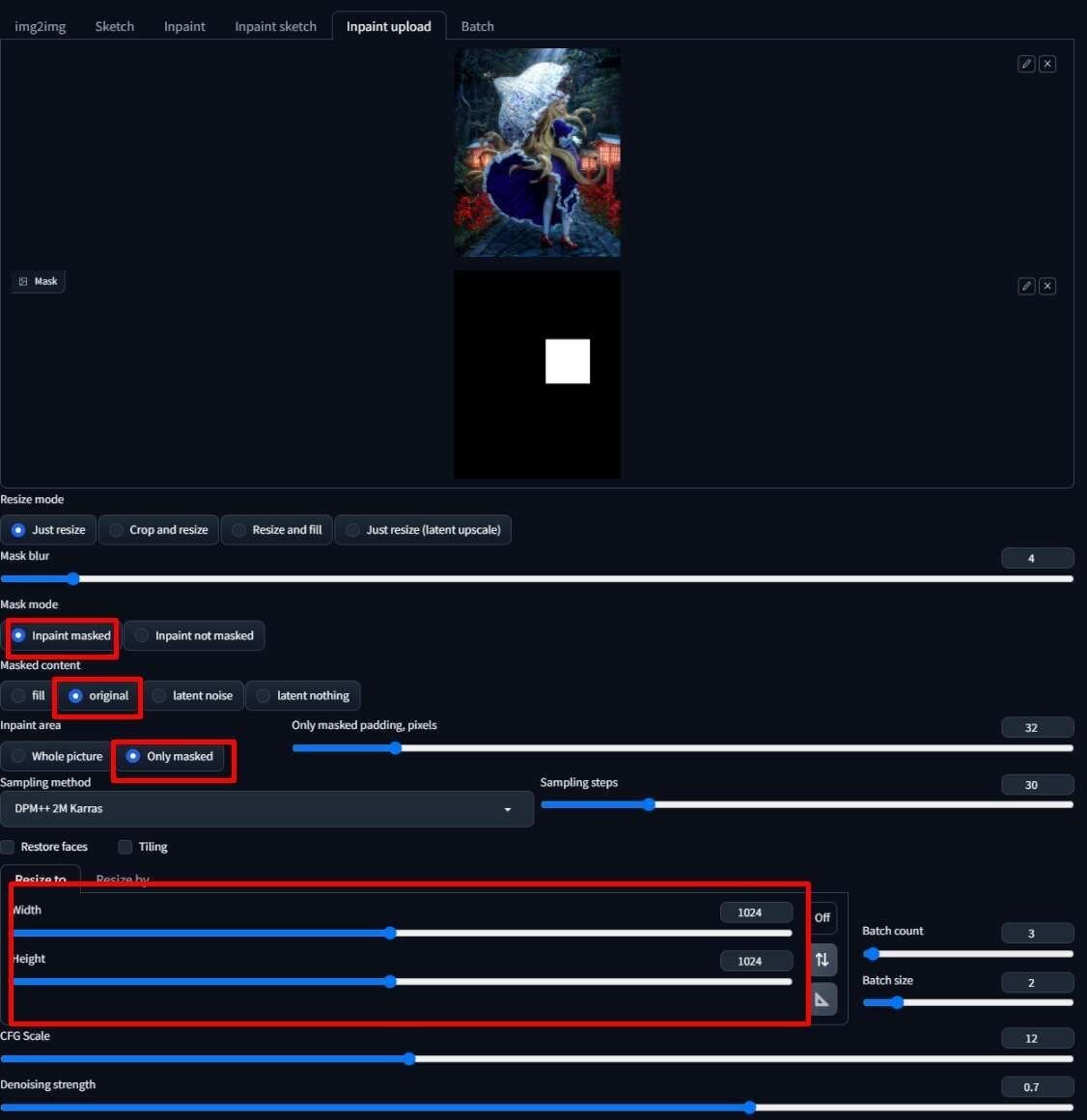
”Inpaint area” を "Only masked" 、"Masked content" を "original", ”Resize To” を "1024x1024" に設定する。
Prompt には顔周辺に関するものだけを残す。
ここでモデルを差し替えたり顔の造形を調整する LoRA を入れて、少し癖を付けてみるのもよい。
今回は顔のみ MajicMix Lux を使用した。
何枚か生成して、よさそうな部分を手動で組み合わせる。
また、Photoshop の Puppet Warp を使って、伏し目がちにするなど調整を行った。

自分の中で八雲紫ってこういう人(妖怪ね)という明確なイメージがあったので、ここはしっかりこだわりをぶつける。

手
今回の画のテーマとして手招きをする所作は非常に重要であったため、再描画で形状を整える。
また、傘を持つ手も AI での再現が難しい部分であるが改善を試みる。
前節と同様に、Photopea Plugin で手の周辺に inpaint mask を作成する。
i2i と CN Tile に前段の画像を配置する。
ここでは元画像の色味より AI による再生成を優先したかったため tile_resample を選択した。
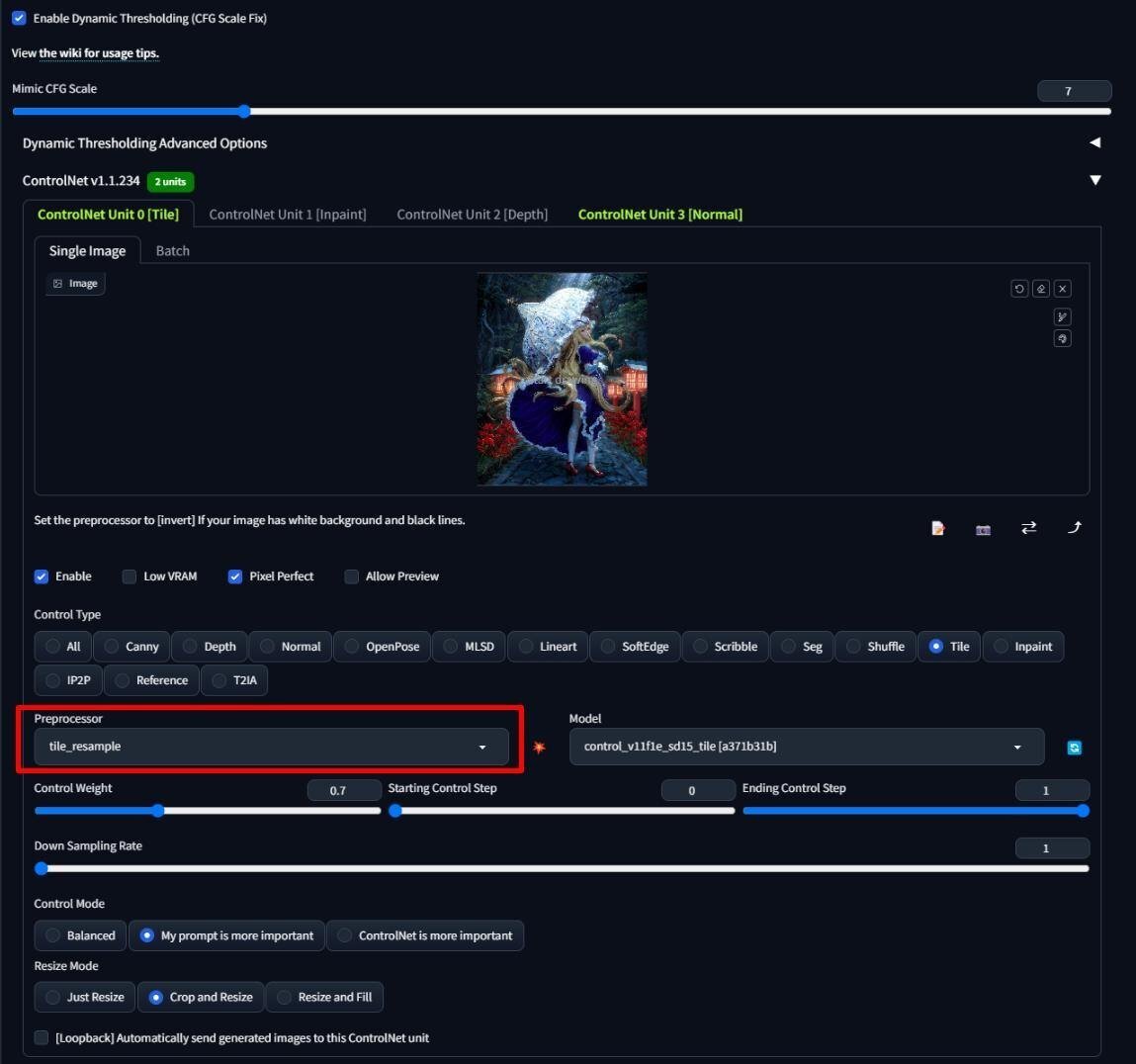
最初、ここまでと同様 Lineart を使用して手の形状をコントロールしようとしたのだが、奥行きや面の情報を持たない関係上正確なコントロールが難しいようであった。
そこで Blender から出力した Normal を使用することとした。
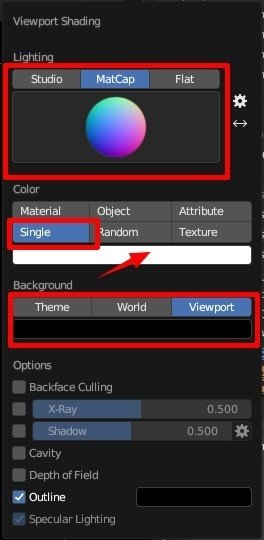
Matcap を Normal にして、Color を Single, 色は White 100% とする。
Background は Viewport を選択し、Black を選択する。
ちなみに、いまだに Blender から Normal を出力する方法がこれで正しいのか分かっていない。
これだと Material で設定した Normal が出力されないが…。
出力した Normal を CN Normal に入力する。
Preprocessor は none としておく。
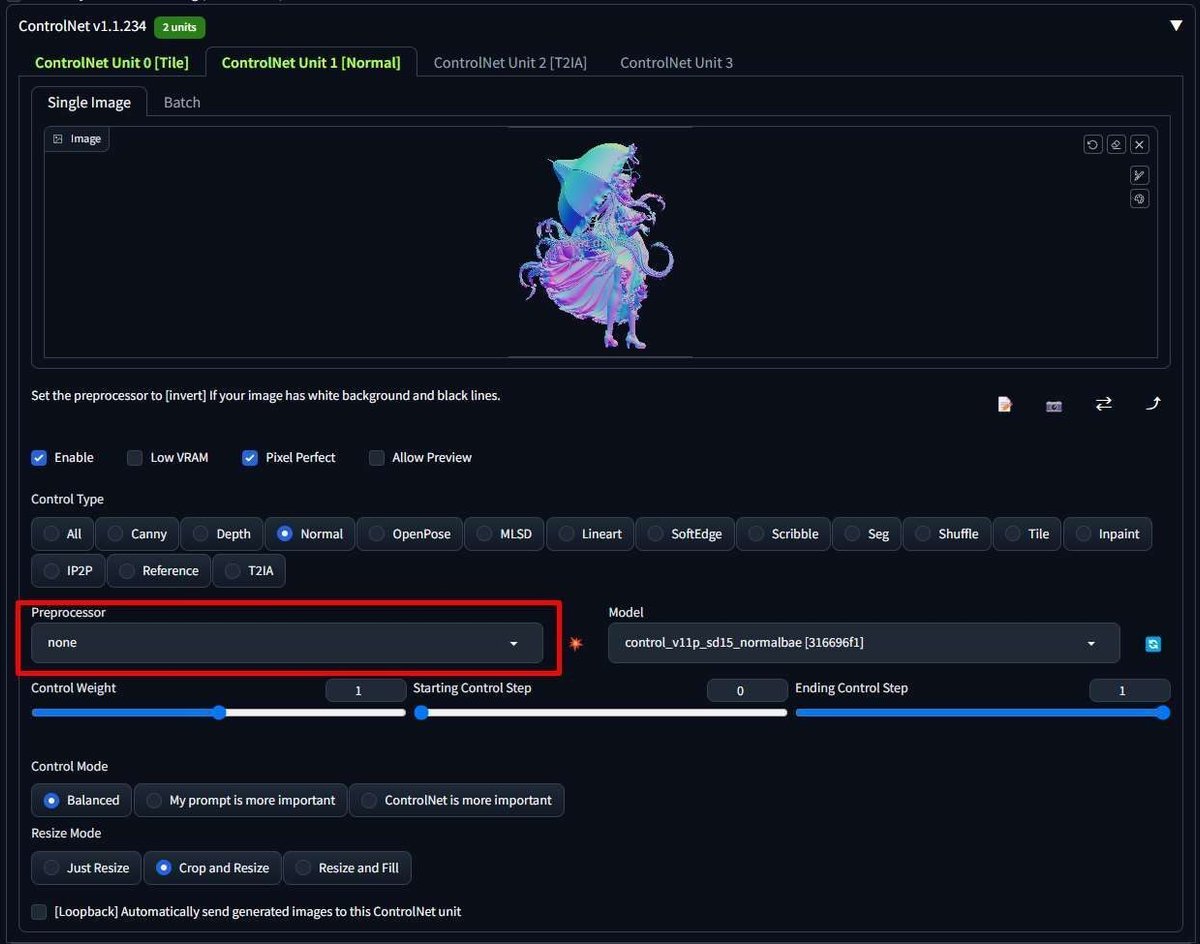
プロンプトには "holding", "reaching", "open hand" など手の仕草に関するものを入れた。
また、レース模様が欲しかったため、LaceAI LoRA を使用した。
最後に良い部分を合成したり、手作業での調整を行った。
手の仕草はそのままに、レースのディテールが追加されており良好な結果が得られた。

傘
これまで同様 Photopea Plugin でマスクを作って inpaint を行う。
元画像を i2i, CN Tile に、線画用画像を Lineart に配置する。
大きく再描画をかけたかったため、Tile の Weight は 0.2 まで落とした。
また、ここでは CN inpaint を有効にした。
Preprocessor は "inpaint_global_harmonious", "My prompt is more important" にチェックを入れた
傘には豪奢な模様が欲しかったため、Chinese traditional pattern LoRA を使用して再描画を行った。

ここまでの結果を組み合わせた画像は以下の通り。

5. AI Upscale
前段までで AI を使った作業は完了としてもよかったのだが、Upscale をかけることにより、ディテールの増加や解像感の向上ができないかを試みた。
Tile Upscale
i2i, CN Tile, Lineart を使用して、生成解像度を上げながらディテールを増やすことができるかを試した。
ただ、結果としてディテールを増やそうとすると元の画が大きく崩れ、反対に画の崩れを抑えようとするとあまりディテールが増えず、好ましい形でディテールが増えることはなかった。

背景が少しくっきりしたので、その部分だけ Mask して重ねた。
Ultimate SD Upscale
Ultimate SD Upscale を使用して解像度の向上を試みた。
設定値は以下。
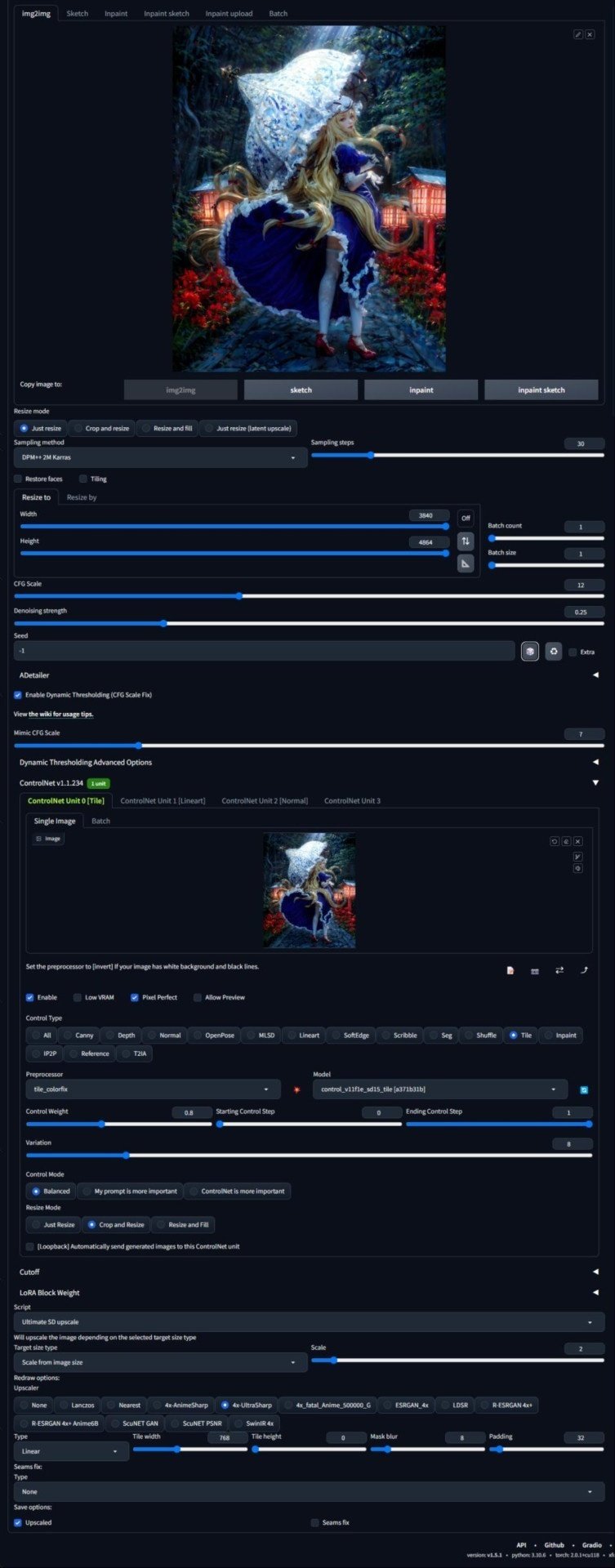
2 倍に拡大した後、Photoshop でサイズを半分にする(入力画像と同じサイズにする)ことで Supersampling の効果を得ることを狙った。

Upscaling 自体は上手く動作した。
しかし、これもキャラクターを伝えるうえで大きな効果があるかというとそういうわけでもなく、SD Upscale の仕組み上タイルの継ぎ目に縞が発生するという悪影響も考えると、必須の工程ではないように感じる。
6. 手動後処理
AI で推定した Depth Map を使用して被写界深度効果を得る。
作成した画像を CN Depth に入れ、Preprocessor を "depth_midas" にする。
"Run Preprocessor" を押して Depth Map を出力させ、保存する。

以降の手順は Photoshop で Depth Channel を作り、そこに Depth Map を入力、Lens Blur Filter の Depth Source に入れるという一般的な手順である。
実際の操作はこの動画が参考になる。
あとは、手動で色味調整やライトの効果を追加した。

7. 背景の拡大(おまけ)
Photoshop Beta の Generative Expand を使用して、背景を拡大してみた。元の背景が割とぐだついているにも関わらず割合それっぽくしてくれてえらいと思った。


Tips
Negative Prompt による形状保持能力の違い
はじめ Negative Prompt には MajicMix Sombre のモデル公式画像のプロンプトを使用していた。
ng_deepnegative_v1_75t, (badhandv4:1.2), (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, bad hands, ((monochrome)), ((grayscale)) watermarkしかし、この状態で生成を行ってると、背景が元画像から大きく変化してしまいがちなのが悩みどころだった。
次に Negative Prompt を以下のものに変えると、体感で元画像の形状が保持される確率が上がったようだった。
(worst quality:2),(low quality:2),(normal quality:2),lowres,normal quality,((monochrome)),((grayscale)),skin spots,acnes,skin blemishes,age spot,(ugly:1.33),(duplicate:1.33),(morbid:1.21),(mutilated:1.21),(tranny:1.33),mutated hands,(poorly drawn hands:1.5),blurry,(bad anatomy:1.21),(bad proportions:1.33),extra limbs,(disfigured:1.33),(missing arms:1.33),(extra legs:1.33),(fused fingers:1.61),(too many fingers:1.61),(unclear eyes:1.33),lowers,bad hands,missing fingers,extra digit,bad hands,missing fingers,(((extra arms and legs))),ng_deepnegative_v1_75t,EasyNegative,EasyNegativeV2,仕組みとしてこういうことが起きるのかは不明だし、気のせいかもしれないが、一度試してみて損はないかもしれない。
tile_resample と tile_colorfix の使いどころ
resample を使用すると色がシフトしてしまう問題があり、それを修正したのが colorfix ということだが、単純に上位互換というわけでもないようであり、使いどころを考える必要がありそうだ。
筆者の体感として、resample は色味の変更も含めて AI によるディテールの再生成を許すもの、colorfix は色を固定するために AI による再描画の自由度を絞ったもの、と理解している。
実際に、PR のコメントにも Limitation としてそれを示唆するような記述がある。
例えば今回の場合、最初黒背景にキャラクターを配置した画像を Tile の入力として背景の生成を試みていたのだが、resample では比較的自由に背景を描いてくれた一方、colorfix ではほとんど背景が現れなかった。

逆に、背景を手動で追加したものを入力とした場合、resample では全体が明るくなって夜の雰囲気が失われるという現象が起きた。
入力画像と生成したいものの関係からどちらを使用するか考えるのがよさそうである。
モデル公式画像の生成データを用いても再現できない問題
作業開始直後、MajicMix Sombre の動作確認をするためモデル公式画像とまったく同じパラメータを使用して生成しても、まったく似ても似つかない画像が生成されるという問題が発生した。

あれこれ試したが結局原因がわからず、最終的に WebUI をインストールしなおすことで解決した。
Settings を変更した時や WebUI に更新があった時には、挙動がおかしくなっていないかチェックすると謎のトラブルを防げそうだ。
まとめと今後の展望
今回作業していて何かと悩ましいことが多かったが、最終的には自分なりの八雲紫みたいなものを詰め込めたような気がしている。
最後にポエムをひとつまみして完成。
ポエムは自作だよ。AI じゃない。ふふ。
「この人に付いて行ってはいけない」本能の警告が鳴り響く。
— NeoClassicalRibbon【3D|AI】 (@takumi_NCR) August 8, 2023
あるいは、取り返しのつかないことだけが甘美なのだと、囁くように。
ただ、今、その手を取ることに躊躇いはなかった。
──────「神隠しの主犯」 八雲 紫#東方Project #AIArtwork pic.twitter.com/H1hfdXMBMC
今回強く感じたのが、AI と共同作業をするといいつつ自分のスキルの低さが AI の足を引っ張っているということである。
AI で自分のしょぼい元画像をお手軽にきれいにしてもらいたい、くらいの甘えた考えだったのだが、AI 自身の描画能力の発揮と元画像からの改変度はトレードオフの関係にあり、中途半端な入力画像に対して「キャラデザとか全体の雰囲気はキープしてね。でも全体の見栄えはモデルの絵柄に沿って良い感じにしてね」という都合のいい落としどころを見つけるのは困難なのである。
画の構成要素をもう少し高い精度で表現して AI に伝えられるよう、基本的な学習を避けて通ることはできないことを痛感した。背景なんかせめてパースを合わせる努力くらいしようよという感じなのだが。
あるいは、キャラと背景の作成それぞれを分離して行い、後から統合するという方法でも良かったのかもしれない。
反省点は多いものの、次回も同様のワークフローに則りつつ、複数のコマでキャラクターの一貫性を保つ手法を検討する予定である。