
Weekly Report 2024/08/07 (wed)
個人的に気になったニュースや自主制作などの週報メモです。
自主制作 / 記事
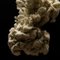
Elemental Anima #0148
Elemental Anima #0148
— takio koizumi | takion.eth (@takion0105) August 5, 2024
Created by :
takio koizumi (Human) x HAL (AI)
🔽Detail / Link pic.twitter.com/xcuRB5ZLPX
[MainPrompt] EA, photo realistic of white pigeon on oleander tree, white pigeon made wispy smoke and feather, wing, sun, spirit, soul, fission, fusion, quantum fluctuation, particle, peace mark, peace, pray, hope, gentle light, blue clear sky, depth of field,
[Relationship] Parent [Element] Flower, Light, Particle, Aves, Pigeon
[Special] 1945/08/06 08:15, Oleander, Pray, Peace
作業BGM:kraftwerk『radioactivity』
[ニュース] AI関連
[オープンソース] Open Model Initiative × Linux Foundation
Open Model Initiative(OMI)がLinux Foundationコミュニティに参加する動きは、信頼性のある環境の築き方も含めて素晴らしいですね。また、OMIコミュニティでのアナウンスの中では、Black Forest Labsのチームと連絡を取っていて協力の機会を探っているとの事です。Fluxが合流するかを自分も含めて気になってる人が多かったのでアナウンスしてくれてありがたいです。StableDiffusionが公開された時と同じぐらいの大きな流れが水面下で動き始めている感じがします。
[画像] Black Forest Labs - Flux 開発周り
Flux周りの開発スピードが尋常じゃないです。ControlNetもCannyぐらいかと思っていましたが、DepthもHEDも対応しました。また、ComfyUI上でLoRAも気軽に作れるようになり、生成にVRAM16GBは必要だったのものがRTX3050 Mobile 4GBまでオプティマイズされたり加速し過ぎてますね。実際に触れてみた感じ、直感的で素直な反応をする為、シンプルな精度以外にも感覚の面で何か惹きつける魅力があり、この熱量になるのも分かりました。今まで仕事で制作したワークフローはFluxに移行していこうと思います。
[画像] Black Forest Labs × xAI
Welcome to the forest @xai https://t.co/lkXq6O0eQu pic.twitter.com/h7rqSmI6wA
— Black Forest Labs (@bfl_ml) August 14, 2024
xAIはMidjouneyを採用するかと思っていましたが、Black Forest Labsになりました。情勢が一気に変わりましたね。その中でMidjouneyがどう反応していくのか楽しみです。
[LLM] xAI - Grok-2 Beta Release
Premium入っていない為自分は使えませんが、今の所SNS上で画像生成が出来るものはXのみなのでどのような影響が出ていくのか気になります。
[LLM] Google - Gemini Live
GPT-4oのボイスモードの様な機能がGemini Liveとして提供が開始されました。Geminiはコストもかなり下がりましたし、LLM系はGoogle Geminiにしようかと考え始めています。
[LLM] Sakana AI - The AI Scientist
LLMを複数組み合わせてアイデアの生成、必要なコードの記述、実験の実行/結果の要約、視覚化、レビューまで、論文作成のライフサイクル全体を自動化するAI駆動型の論文作成システム。Sakana AIらしいアプローチで素晴らしいですし、様々な分野にスケールでき、加速していきそうです。AIが研究論文を出して、AIが査読する。大手テック企業との異なるアプローチですが、この発想で進み過ぎると自律分散的に動くAIのルーツになりそうで少し怖さも感じてきました。
[ComfyUI] ComfyUI Leadership Summit - TOKYO
🏆来了朋友们!!!ComfyUI 全球领导力峰会第二站·东京站!!!
— -Zho- (@ZHOZHO672070) August 11, 2024
🚤11月CLSCN东京站开启报名!AI开源社区首次出海!
🤣CLS深圳获得海外强烈反响,我们趁热将中国AI活动带到东京,会见到亚洲领域内知名开源开发者、头部AI企业、艺术家和学术团队等,相信开源的力量!… https://t.co/9GykRiRHcD pic.twitter.com/XAlFrfBVWa
11月16日-17日にComfyUI Leadership Summitが東京で開催されます!ComfyUIヘビーユーザーとしては楽しみすぎますね!あと、告知のデザインもComfyUI愛が溢れてて好きですw
[画像] Unity Technologies - IP Adapter Instruct
ControlNetとIP Adapterのメリットを混ぜたアプローチで素晴らしいです。一つのIP Adapterでスタイル、背景、ポーズなどを選択できるのはワークフローがかなり省略できるので助かります。またUnityがこの様なアプローチでモデルを発表するとは思わなかったです。
[ComfyUI] AI Assistant
とりにくさんが作ったお絵描き補助AI AI AssistantのComfyUI版ですね。ワークフローに組み込みたかったので、これは助かります。
[3D] CSM - Cube メジャーアップデート
We're super excited to ship 3 major updates to Cube:
— Common Sense Machines (@CSM_ai) August 12, 2024
⏲️ Textured meshes in minutes
🎨 Improved AI retexturing (with text & high-frequency details)
🦾 Fewer defects in slow refines
Upgrade to access all the latest features and workflows: https://t.co/YYW52ACeaN#3D #AI #Cube pic.twitter.com/x4S3aFYfdB
テクスチャー付きのメッシュの精度が向上した上に高速化してます。
[ComfyUI] kijai - ComfyUI-LLaVA-OneVision
LLaVAをComfyUIで動かせるカスタムノードです。可能性が広がりまくるので、色々なワークフローを作りたいです。
[画像/動画] ControlNeXt
SD3やSVDなどに幅広く対応するControlNetですね。特にSVD周りは興味深いです。ComfyUIにも実装されたので検証してみます。
[3D] UniTalker: Scaling up Audio-Driven 3D Facial Animation through A Unified Model
音声入力から3Dフェイシャルアニメーションを作成するフレームワークです。CGワークフローに組み込みたいです。
[音楽] stable audio controlnet
Stable AudioのControlNetやLoRAは興味があるのですが、抽象的過ぎて難しすぎますね。いずれこの辺りも踏み込んでみようと思います。
[3D] Autodepth Ai
Blenderで画像からAIを使用して奥行きのある深度マップ、ディスプレイスメントマップを作成し、モデルを作成出来るアドオンです。見た感じDepth Anythingを使ってる感じですね。
[動画] KEEP - Kalman-Inspired FEaturE Propagation for Video Face Super-Resolution
映像内の顔のアップスケールするフレームワークです。ノイズが少なくて素晴らしいです。
[動画] Viggle - 新機能 Multi
Introducing #Viggle's new feature - Multi.
— ViggleAI (@ViggleAI) August 12, 2024
Now you can replace multiple characters in a video. Ever imaged you and your friend dance in the iconic La La Land scene? We make it happen!
Stay tuned for more cool templates. We’d love to hear what videos you want to create! pic.twitter.com/dE4GHXWVLg
映像内の複数のキャラクターを置き換える新機能です。PV映像としてどうかと思うことだらけですが、技術だけを観ればこの分野では一番強いサービスですね。
[AI活用] Krea ai × Runway Gen-3
Hey, this is the future of storytelling :D#art #ai pic.twitter.com/P5DOGzVWvQ
— Martin Nebelong (@MartinNebelong) August 12, 2024
このワークフローは凄いですね。AfterEffectsのGS空間でレイアウトして、エフェクトなどを加筆しながら生成して、Gen-3で映像化した上でElevenLabsで音を付ける。
[3D] AvatarPose
マルチアングルから3Dアバターとモーションを生成するフレームワークです。これが公開されれば、move.aiのようなことが出来そうですね。
[動画] Rendernet - Narrator
🚀 Introducing Narrator 🎉
— rendernet (@rendernet_ai) July 30, 2024
Now, you can upload a video, add a script, and seamlessly lip-sync the character to your words.
Some crazy examples below👇
(1/7) pic.twitter.com/4G5kGmwSHg
ナレーター機能。厳密に見れば口元のノイズが気になるところありますが、ぱっと見はもうわからなくなってきてますね。
[3D] Meta - VFusion3D
Metaの動画生成モデルから3D生成するAIがHuggingfaceで試せるようになっています。
[動画] Runway - Gen-3 Alpha GVFX
Explore adding GVFX to any footage you have. From shot on your phone to high quality cinematic action.
— Runway (@runwayml) August 8, 2024
Learn how: https://t.co/TPagVHroKk
(1/7) pic.twitter.com/95BlwuUsCl
もう凄いです。
[画像] Apple - Matryoshka Diffusion Models
Appleの画像生成モデルMatryoshkaが公開されてました。
[3DGS] SuperSplat
3d gaussian splattingを操作するためのオープンソースエディター。誰か触ってみて下さい・・・。
[政府] 東京都 - 「文章生成AI利活用ガイドライン」の策定について
分かり易くまとまっています。