
Weekly Report 2024/11/27 (wed)
個人的に気になったニュースや自主制作などの週報メモです。
自主制作 / 記事
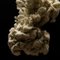
Elemental Anima #0163
Elemental Anima #0163
— takio koizumi | デザフェス60 A-285 両日 (@takion0105) November 24, 2024
Created by :
takio koizumi (Human) x HAL (AI)
🔽Detail / Link pic.twitter.com/HMnboYgOFw
ここ3作は、朱雀・白虎・青龍と来ていましたので、四神最後の"玄武"をモチーフにしました。太陰神とされたり、陰陽が根底にあるElemental Animaと相性の良いモチーフでした。"玄武"が冬の象徴でもあるというのは、制作した後に知りました。玄=黒なので全体的に暗い雰囲気にしましたが、亀と蛇の表情や絡まり方、月明りでぼんやりと照らされる湖など個人的に気に入っています。インターステラー再上映を観に行く前だったので、一瞬、"ミラーの星"のような背景にしようと思いましたが辞めました。
作業BGM:Hans Zimmer『Interstellar (Original Motion Picture Soundtrack)』
[お知らせ] 近未来教育フォーラム 2024
11/30に近未来教育フォーラム 2024で登壇させていただきます。ご興味がありましたら是非。
[映画] インターステラーIMAX 再上映
【映画】
— takio koizumi | デザフェス60 A-285 両日 (@takion0105) November 24, 2024
「インターステラー」
監督:クリストファー・ノーラン
池袋グランドシネマサンシャインIMAX
行ってきます
“Do not go gentle into that good night”https://t.co/Qao44RFQHH pic.twitter.com/uD1xE6mUK4
オリジナル画角でインターステラー"を観るのは約4年ぶりですが、最高でした。また観に行きます。あと、同じ回に山崎貴監督も来ていて驚きました。
“Do not go gentle into that good night”
[ニュース] AI関連
[画像] Black Forest Labs - FLUX.1 Tools
Fill (inpainting and outpainting) / Depth, Canny / Redux
どのモデルもクオリティが高くて重宝しております。個人的には、Fillのアウトペイントの機能がかなり精度が高いのでありがたいですね。ですが、どのモデルも重すぎるので、もう少し軽量化して頂けると助かります。あと、ReduxがClip経由なのがちょっと自分のワークフロー的に使いづらいです。
[動画] Luma AI - new Dream Machine
Say hello to the all-new #DreamMachine. 🚀 Your visual thought partner—where ideas become reality. Ideate, visualize, and share your ideas with the world. Available now. pic.twitter.com/1NhexUa0Xl
— Luma AI (@LumaLabsAI) November 25, 2024
Creators Programで先行で色々検証させて頂いておりました。Boards機能やBrainstorm機能など便利な機能が増えて動画生成がかなり捗りますね。画像を生成するにもプロンプトを補助・拡張してくれる上に、ImagenFXの様にバリエーションの候補も選択しやすいのでありがたいです。iOSでも生成できるようになったり、色々洗練してきました。
[動画] Runway - Expand Video
Introducing, Expand Video.
— Runway (@runwayml) November 22, 2024
This new feature allows you to transform videos into new aspect ratios by generating new areas around your input video. Expand Video has begun gradually rolling out and will soon be available to everyone.
See below for more examples and results.… pic.twitter.com/liF0qF9d0S
この拡張機能はシンプルに応用が利く範囲が広いので素晴らしいです。
[画像] Runway - Frames
Runwayの新しい画像生成モデルが発表されました。フィルムグレインなどの質感がかなり向上していますね。早く触ってみたいです。
[動画] Mochi - Mochi 1 LoRA Fine-tuner
How to Train Your Mochi: Introducing LoRA fine-tuning.
— Genmo (@genmoai) November 26, 2024
Customize Mochi on a single GPU with just a few videos. Create any effect or create consistent characters.
Make Mochi 1 truly yours. pic.twitter.com/P57vi2OcrY
これは嬉しすぎますね!遂に精度の高い動画モデルに対してLoRAを制作できるようになりました!学習のさせ方もかなり丁寧に共有してくれているので、今まで制作したエフェクトR&Dの動画などを学習させて色々検証してみようと思います!
[画像] Stability.ai - ControlNets for Stable Diffusion 3.5 Large
Stable Diffusion 3.5 LargeのControlNets系は揃いましたね。Flux.1 toolsの公開と被って埋もれてしまったの少し残念ですね。容量やライセンスも含めるとかなり使い易くなってきたので、SD3.5とFluxどちらで行くかを再検討したいと思います。
[動画] SAMURAI
Segment Anything Model 2の課題を改善したトラッキングフレームワークです。このトラッキング性能は凄いですね。映画"1917"のシーケンスが検証に最適過ぎてちょっと感動しました。
[画像] nVidia - Sana model release
遂に待望のSanaが公開されましたが、他にもアップデートや公開されたものが多すぎて全く追いつけません!
[動画] KLING AI - LEVELED UP
For more information, dive into the video👇 #klingai #upgrades pic.twitter.com/sks9cckSpw
— Kling AI (@Kling_ai) November 22, 2024
🔥KLING AI has LEVELED UP once again! 🎉We're excited to announce the latest upgrades of KLING AI.
— Kling AI (@Kling_ai) November 22, 2024
The key upgrades include:
1️⃣KLING 1.5 Model (Image-to-Video) Professional Mode: Now supports Motion Brush and Camera Movement!🚗
2️⃣KLING 1.5 Model (Image-to-Video) Standard Mode:… pic.twitter.com/HuzTHvTzmd
Kling AIは、モーションブラシなど全体的に必要な機能は全て揃っているのですが、生成速度がかなり遅かったので向上するのは助かりますね。
[動画] LTX-Video
突如オープンソースの動画生成モデルLTX-Videoが公開されました。モデルが9.5GB程度でこの精度は素晴らしいですね。生成速度も含めてかなり使い勝手が良いので、色々展開していきそうです。
[3D] nVidia - Edify 3D demo
先週紹介したnVidiaの3Dモデル生成Edify 3Dが触れるDemoが公開されていたので興味がありましたら是非。USDZでもダウンロードできるが素晴らしいです。
[ゲーム] The Matrix
リアルタイムでインタラクティブに生成するプロジェクトの中では一番凄い気がします。ネーミングも良いですね。
[動画] EchoMimic V2
表情だけでなく、上半身の身振り手振りも生成できるフレームワーク。これがオープンソースで使えるのが凄すぎますね。
[画像] Manga Editor
SD WebUI / Forge or ComfyUI + Manga Editor =💪💪
— Sankaku@Desu! (@hypersankaku2) November 23, 2024
A completely free web manga creation app. No annoying paywalls. Any feedback would be appreciated! It works perfectly on the web and as an extension.
[Web site] https://t.co/34WrDy2n2W #aitools #mangatwt #ComfyUI #sdxl
ローカル環境を活用した設計が素晴らしいです。
[画像] OminiControl
IC-LoRAやReduxなど選択肢がかなり増えた中で、精度だけではなく容量やスピードなども重要になってきてます。Ominiも精度は1024pxに対応したモデルが公開されたら検証してみたいですね。
[動画] GoEnhance AI - Video-to-Video V3
✨ Exciting Update! GoEnhance AI's Video-to-Video V3 is here! 🚀
— GoEnhance (@GoEnhance) November 25, 2024
🔥 Stronger Stylization: Now your videos look like true anime, not just traced conversions.
⚡ 20% Speed Boost: Create faster than ever with our optimized V3 engine.
🎨 Enhanced Color Vibrancy: Rich, vivid colors… pic.twitter.com/ttGisOxmHK
アニメ系のVideo to Videoの中では他のモデルよりは精度高いですね。
[画像] OneDiffusion
正直、モデルが多様化され過ぎていて、ストレージ的にもワークフロー的にも限界なので、このOneDiffusionの様にすべてを統合する思想は応援したいですね。
[画像] Tencent - Depth Crafter v1.0.1
Depth生成ではかなり使っているので、シンプルに精度が上がって早くなるのはありがちです。
[画像] Tencent - FitDiT
Tencentさんの最新のVirtual Try-onです。再現度とディティールが向上してますね。Codeが公開されたらすぐ検証したいと思います。
[画像] Qwen2vl-Flux
FluxにQwen2vlを追加したモデルです。現在自分のワークフロー内でやっているものをモデルに統一化されています。これで容量が削減されて精度がキープされるのであれば移行したいです。
[3DGS] Google - Quark
3DGS系は沢山見てきましたが、ぶっちぎりで凄いです。特に車の反射は引きました。
[動画] arcads.ai - generated street interview
introducing ai generated street interview...
— Romain Torres (@rom1trs) November 21, 2024
available today, only on Arcads AI
you can make hundreds of these in minutes... pic.twitter.com/jcXj4rKmeY
あまり良い使われ方はしない気がしますが、興味深いアプローチですね。データセットも大量にあると思いますし、カメラも大きく動かないのでAI向きなコンテンツではあります。バキのインタビューの様な動画を作りまくるのは面白そうです。
[動画] AI Video Composer
Introducing: AI Video Composer 🔥
— Victor M (@victormustar) November 24, 2024
Drag and drop your assets (images/videos/audios) to create any video you want using natural language!
100% Open Source and powered by Qwen2.5-Coder-32B (this thing is a beast)https://t.co/ZEvz2WOePt pic.twitter.com/zdyEmo4EES
動画、画像、音楽を入れるとまとめてくれるフレームワークです。これがどんどん精度が高くなっていた先の映像制作はどうなっているのか。
[記事] OpenAIの動画生成AI「Sora」へのアクセス方法がリークされる
Dall-Eの時から同じようなことが繰り返されていますね。
[記事] グーグルのAIがいきなり「死んでください」と言ってきたという報告
"インターネット"を学習していくと、AIはこの様な事になってしまうのでしょうか。"ハルシネーション"だったのかどうか。
[政府] NAFCA - パブリックコメント「「生成AIを巡る競争」に関する情報・意見」
”アニメ産業における不正行為の具体例” (2)は、色々なツッコミが入りそうですね。
[記事] 株式会社グリオグルーヴ、AI×CGの開発プロダクションを設立
昔一緒に働いたことがあるDanielさんがAI×CGの開発プロダクションを設立しました。