
障害対応のふりかえりとその後の取り組み

こんにちは、那須です。
システム運用していると必ずついてまわるのが障害対応ですね。障害発生した時にどう対応するか、その後再発させないためにはどうすればいいか、などをこれを読まれている運用担当の方は常に考えられていると思います。私たちも同じで、onedog のサービスを利用して得られる価値をユーザのみなさまに継続的に届けられるように運用しています、、と思い込んでいました。
少し前になりますが、2021/2/6(土) と 7(日) のそれぞれ夕方に onedog のサービス提供ができなくなる障害が発生しました。今思い返してみると、2 月時点ではインフラ観点でみるとあまりいい運用ができていなかったと思います。その時の障害対応の振り返りだと思って、障害原因の確認と復旧対応、そしてその後の同じ障害を再発させないための取り組みについて公開することにしました。まだまだ完全な形には程遠いですが、少しずつ運用の姿を進化させていきたいと思っています。
障害発生(2/6(土) 16:55〜17:55)
最初の障害発生がこの日時でした。ユーザのみなさまからは onedog を使ったお散歩ができない!とお問い合わせを多数いただいておりました。システム側でも 500 エラーが出続けている状態で、かなり焦ったのを覚えています。
リリース作業は数日やっていないこと、この時刻に突然発生したことを踏まえて、AWS 側で何か障害発生しているのかと最初は思いました。いろいろ見ていると、Lambda のエラーで 1040, 'Too many connections' が多数発生していることがわかりました。この時点で AWS 側の障害ではないことに気づけられればよかったんですが、気持ちが焦っていて AWS サポートに問い合わせる事ばかり考えていたのが残念です。
AWS サポートに問い合わせるための文章をダッシュで書いているうちに障害が自然復旧しました。この自然復旧、その時点では解決するのでいいんですが、原因追求がしにくい状況になるのがとても厄介なんですよね。ただ再発はさせたくないので、翌日の午前中まで使ってどういう状況だったのかを把握することにしました。
状況把握と考えたこと
いまいち状況がわからなかったので、アクセス数(API Gatewayのカウント)や Lambda の遅延等を CloudWatch で見てみました。その時の画像が↓こちらです(UTC 時刻表示です。左側の山が高くなっている時間帯が障害発生時間帯です)
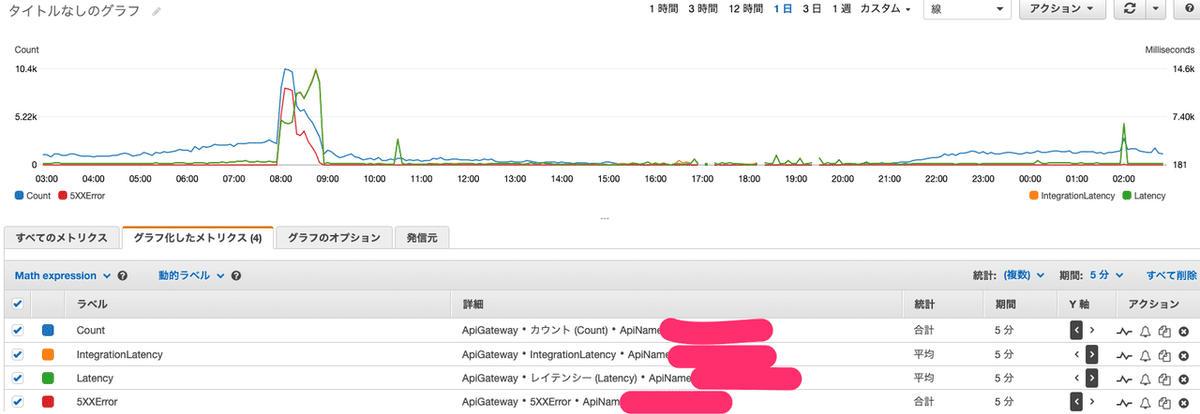
これを見て気づいたことが以下の 2 つです。
・障害発生日時に突然アクセス数が普段のピークの 4 倍になっていた
・RDS の CPU 使用率が障害発生時間帯で 100% に張り付いていた
これで確信しました。これ AWS の障害じゃない、単純にアクセス数が増えただけだ、と。そして障害のボトルネックが RDS だということもわかりました。
障害発生前の当該部分の構成は、API Gateway → Lambda → RDS となっていました。アクセス増に対応する観点だと、API Gateway と Lambda については AWS にて自動的にある程度やってくれるので、こちらでは RDS をどうにかする必要がありました。単純にインスタンスタイプを上げるという選択肢もありましたが、いろんなメトリクスから計算してみると 1 つ上げるだけではとても負荷に耐えられないことが容易に想像できました。なんとか ELB の Auto Scaling のように対処できないものかと調べていたら、RDS Proxy の存在に気づきました。RDS Proxy が何なのかは↓このドキュメントを見てください。
Lambda から RDS への DB 接続数が多すぎるエラーが出ていたので、RDS Proxy を以下の図のように導入すれば今回のようなケースでもなんとかなるんじゃないかと思い、実際にやってみることにしました。また、RDS Proxy を使えば多少レイテンシは増えるもののフェイルオーバの時のダウンタイムを短縮できる可能性もあったので、可用性を高めるためという理由も兼ねています。

ただ、流石にアクセス数増えすぎだと思って、日曜日はいつもの推移なんじゃないかと予想して構成変更は月曜にやろうと思っていました…
障害再発(2/7(日) 16:20〜17:30)
障害は油断した時にやってきます。今回も漏れなくそうでした…
状況は全く同じです。相変わらず RDS の CPU 使用率が 100% に張り付いています。このまま見てるだけというわけにもいかないので、ダメもとで RDS Proxy を導入してみることにしました。
結果どうなったか?
何も状況は変わりませんでした…
よく考えてみるとそうですよね。コネクションプーリングしてくれるだけで、DB 接続数の最大値が増えるわけではないので、多少の DB 接続数の増加には効果がありますが度を超えた DB 接続増加には耐えられません。そして、この日もまた自然に復旧してしまいました。
再発防止対応
ひとまず RDS Proxy が入ったことで多少の DB 接続数の増加には耐えられるようになりました。しかしその許容範囲以上の DB 接続数が 2 日にわたって発生したことは事実です。しかも RDS の CPU 使用率は 100% に張り付いていました。もうどう考えても RDS のインスタンスタイプを上げるしか再発防止できないと考え、その日の夜に実施しました。
インスタンスタイプを上げてから 3 日間の RDS の CPU 使用率メトリクスを確認すると、いい感じで半分程度になっていました。また、数ヶ月前まで遡って CPU の負荷を確認したところ、平日の CPU 使用率が約 55% を超えている状態だと土日に危ない状況になる可能性があることがわかってきました。なので水平注釈もつけて見るようにしました。

さらに発生するヒヤリハット
もうこれで大丈夫だろうと油断してしまったのが正直なところです。システム運用に油断は厳禁だとこれまで何度も体験してきたはずなのに。
同じ週の金曜日、アプリへのプッシュ通知が 18:00 に配信されたのですが、その時の状況がこちらです。RDS の CPU 使用率が約 60% に跳ね上がっていました。プッシュ通知はそれなりの頻度で行われるので、このままではまた RDS のインスタンスタイプを上げないといけないかもしれない、と考えていました。

しかし、プッシュ通知を配信する仕組みの中に、1 分ごとの配信数を設定できることがわかったので、インフラ側では特に対応はせずにプッシュ通知配信時に約 10 分にわたって分割配信することで対応することにしています。この効果は抜群で、RDS の負荷も 5% ほどの上昇だけで済んでいます。
再発させないための取り組み
さて、これまでは障害を復旧させる観点でのお話でした。システム運用では同じような障害を発生させないための仕組みを作ることが大切です。仕組みまで作れなくても、傾向を見れるようにするだけでも結果は変わってきます。
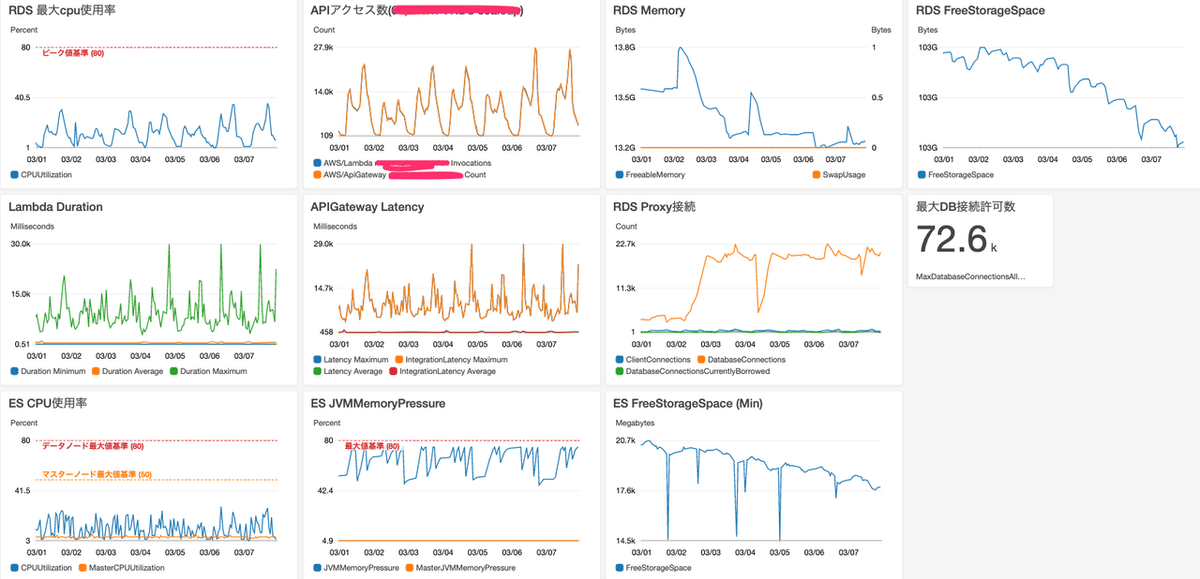
まず最初にやったことは、onedog のシステム全体の状況を 1 画面で見れるダッシュボードの作成です。これまでは、何かあれば各サービスのコンソールにアクセスしてメトリクスを確認していたのですが、これでは全体像が見えないだけではなく何かあった場合のリソース間の関連が全くわかりません。これを解消するために、以下のようなダッシュボードを作成しました。
私が一番見る機会が多いので、ひとまず自分がわかりやすいように作っています。左上の 4 つがアクセス数と RDS の負荷状況、右上が RDS の DB 接続とその関連情報、下は Elasticsearch の負荷状況がそれぞれ出ています。これを毎週見るようにすることで、その週の推移やそれ以前との比較が簡単にできるようになりました。これで、傾向とアプリのイベントを合わせてどのようにインフラ側で対応すればいいかの検討材料が揃いました。当面はこれでやってみようと思います。ある程度材料が揃えば、それを CloudWatch アラームの閾値として設定したり 、内容によっては Datadog や New Relic の Forecast Alert 等も使ったりして自動的に気づける環境を少しずつ作っていきたいという気持ちはあります。
これまでも、システム監視は重要だと自分のブログでも書いてきたのに、傾向を見るという基本的なことができてなかったので、今回の件は心の底から反省しています。ひとまず障害発生から 1 ヶ月、大きな障害を発生させることなく運用できているので、気を抜かずにユーザのみなさまにわんちゃんとの素晴らしい日々を記録していただけるよう頑張っていこうと思います!
最後に
わんちゃんと一緒に暮らしている方、是非 onedog を使ってみてください!
そして、一緒にインフラを支えてくれるエンジニアの方、バックエンドの仕組みをガンガン開発してくれるエンジニアの方、Web や iOS、Android のフロントエンドをガンガン開発してくれるエンジニアの方を大募集しています!
↓こちらを見てちょっとでも気になった方は気軽にお問い合わせいただけるととても嬉しいです!