
ChatGPTの裏側 シリーズ2

はじめに
この記事は前回のLLMを理解するシリーズ第二弾です。
今回はLLMの核となるAttentionとは何かについて解説していきます。なるだけ数式を使わずに直感的に理解できるように頑張ります!これが理解できればあとは本を読んで理解できるようなるはずです!
復習
前回は、入力されたテキストをLLMが解釈できる高次元ベクトルに変換するというところまで見ていきました。例えば、「たくさん実ったみかんの木がある船の名前は」という入力があった場合、この文章をトークンごとに分割し、各トークンが各ベクトルを持っているということです。(前回と同様に1トークン=1単語とします。実際は違いますが理解のしやすさのため)
「たくさん」「実っ」「た」「みかん」「の」「木」「が」 ...というように分割され、それぞれのトークンは12,288次元のベクトルです。
詳しくは前回の投稿をご覧ください
概要
前回のベクトル情報(埋め込み)を使って、Attentionがどのようなことをするのかについて見ていきます。ゴールは1つのAttentionブロックを通った後に、最初の埋め込みがどのようになっているのかを理解することです。
LLM全体としては、Attentionブロックを何個も同時に計算し、それを多層パーセプトロンなどを通らせることを1つの処理レイヤーとして、それを何層分も繰り返します。そして最後の計算結果から最も次にくる確率の高いトークンを取得し、次のトークンを予測、生成します。
今回はこの中のAttentionブロック1つ分が何をしているのかを説明していきます。ここが理解できれば、LLMがどうやって次の単語を予測しているのかが直感的に理解できるはずです。
注意
ちなみにAttentionブロックを何個も同時に計算することをMulti-head-attentionと呼び、今回みていくのはsingle-headのself-attentionです。
Attention
先ほどの例に沿って入力が「たくさん実ったみかんの木がある船の名前は」が入力だとします。LLMはこの文章の次に来る可能性が最も高い単語を選び、文章を生成していきます。
ここでは便宜的に、入力が以下の埋め込みに変換されたと考えます。(理解のしやすさのためにところどころ単語よりも大きい単位で区切っています。)
「たくさん」
「実った」
「みかんの」
「木がある」
「船」
「の」
「名前は」
ここで各埋め込みが、「私に関係している他の埋め込みは何ですか?」というような質問を作ります。(埋め込みに意思があるものだと思ってください笑)
これに対して、さらに各埋め込みが「私こそがあなたに関係しています」という答えを出します。ここはもうこういうものだと思ってください笑。
注意
これをAttention is All you need という論文では質問の部分をQuery, 答えの部分をKeyとしています。
以下は原論文です。
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key
次に各質問(Query)と各答え(Key)がどれくらいあっているかを計算します。これにより、どれくらい二つの埋め込みが関連しているのかが分かります。実際にはここは上記2つのベクトルの内積で計算されます。
これらの結果を以下に記します。(結果は空想です。)円が大きいほど関連性が高いと思ってください。ちなみに、self-attentionでは自分よりも後の単語は無視するので左下半分は空欄にしています。

この表では、船に注目してみます。「みかんの」と「木がある」が関連度が高いようです。他の埋め込みは関連性が低いという結果になります。ここでは、「みかんの」が0.6, 「木がある」を0.4として、他の埋め込みは0とします。ここでの0.6や0.4という数字は上記の内積の計算結果と思ってください。
次に、「みかんの」と「木がある」という埋め込みの情報を「船」という埋め込みに付与します。この際に、大規模言語モデルがValueという埋め込みの情報に変換できるパラメーターを持っていると思ってください。ここはもう想像で大丈夫です。
直感的には以下のようになります。
Value * 「たくさん」 * 0 + ... + Value * 「みかんの」 * 0.6 + Value * 「木がある」 * 0.4 + ..
= Value * 「みかんの」 * 0.6 + Value * 「木がある」 * 0.4
計算結果を「船」という埋め込みに付与する変化量と考えます。ここでは、Δ船としましょう。
最後に「船」に上記の変化量をすべて足し合わせることで、文脈を考慮した新しい「船」の埋め込みが取得できます。
「船」 + 「Δ船」= 「ちょっと文脈を考慮した船」
同じように他のすべての埋め込みに対しても関連性を考慮した計算をしていき、
「たくさん」 + 「Δたくさん」= 「ちょっと文脈を考慮した「たくさん」」, 「実った」 + 「Δ実った」= 「ちょっと文脈を考慮した「実った」」などを取得します。そしてすべての埋め込みに対して、文脈を考慮した新しい埋め込みを取得できます。これが1つのAttentionで行われる結果です。
この処理を何回も行い、文脈の情報が入っている埋め込みから、さらに文脈の情報が入っている埋め込みを計算していきます。そして最終的に「かなり詳細の文脈の情報が入っている埋め込み」が取得できます。最後にその埋め込みを利用して最も次にくるトークンを取得し生成していくというのがLLMの推論フェーズの仕組みなのです。
ちなみに、先ほどの「私に関係している他の埋め込みは何ですか?」というような質問のことをQuery(クエリ)、「私こそがあなたに関係しています」という答えをKey(キー)、と呼び、かつValueという埋め込みの情報に変換できるパラメーターと合わせてQueryKeyValueと呼びます。もしLLMについて勉強するなら最初に躓くところだと思うのでここでその大体の意味を理解しておくと数式が頭に入ってきやすいはずです。
注意:
論文ではこの計算を以下のように一行で表しています笑
厳密にはQueryとKeyの内積を計算した後、QとKの次元数の平方根で割ってその後にsoftmaxという関数で値を0~1に正規化しています。
これを理解するまで結構時間かかりました。
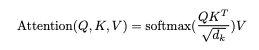
余談
余談ですが、先ほどのどれくらい関連度が高いかを計算した表のことをAttention Patternと呼びます。勘の良い方はわかるかもしれませんが、このAttention Patternは入力された文章の2乗になります。つまり、入力が大きければ大きいほどこの表は指数関数的に大きくなります。この上限がコンテキストサイズとよく言われるもので、コンテキストサイズが大きいモデルはより多くの入力を処理できる = 多くの文脈情報を計算できる ことになります。これがよく質問される、「ChatGPTが今までの入力を覚えている気がすることの正体」です。同時に、この膨大なコンテキストサイズがLLMのボトルネックにもなるとも言われています。
次にやること
Attentionのやっていることが直感的に分かりましたでしょうか?実際にはAttention Patternの関連度を計算する際に正規化を使ったりMaskingという処理をしたりもっと複雑なことをしています。そのため、本当は計算式を用いて説明した方がより理解が深まるかと思いますが、直感的な理解という面ではこちらの方がわかりやすいだろうと思いこのような形式にしました。むしろわかりにくかったらすみません。
ここまで理解できたら次に以下の本を読むことをオススメします。
より詳しくLLMについて書かれていて、数式で実際にやっていることや、そしてMulti-head-attentionとの違いがより理解できると思います。次に、原論文を読むのがいいでしょう。そうすることでより理解が深まるはずです。
私は最初に原論文を読み、ほぼ分からず、次にこの本を読み、その後で色々試してみることでやっと理解が深まりましたが、それだと結構きついです笑。前回の記事と今回の記事で直感的に理解できたら上記本を読むことをオススメします。
理解した上で Llamaとかをいじってみると楽しいし、いろんな発想も浮かぶかもしれません。技術の裏側を知って使える人になりましょう!最後まで読んでくださりありがとうございました。
この記事が気に入ったらサポートをしてみませんか?