
【データ分析】構造方程式モデリング(SEM)の問題点と注意点について(吉田他, 2020)

今日も今日とてデータと向き合っており、更新がすっかり遅くなっているこの頃です。仕事も、次年度に向けた計画やら何やらの時期でもあってバタバタしており、研究ではデータ分析以外のことが全く手につかない日々ですが、何とかやっております。
データ分析の知見を深める中で、大変興味深い文献を発見したので、ご紹介します。要は、SEMがあまりよろしくない使われ方をしているのでは?というご指摘です。
吉田寿夫, 村井潤一郎, 宇佐美慧, 荘島宏二郎, 小塩真司, 鈴木雅之, & 椎名乾平. (2020). SEM は心理学に何をもたらしたか?. 教育心理学年報, 59, 292-303.
どんな文献?
簡単に言えば、構造方程式モデリング(Structural Equasion Modeling:SEM)の「ゆるい」使い方の蔓延によって、心理学における常識に欠けた主張や、データと乖離した提案が増えたという問題提起と、その問題点の指摘を行った、教育心理学会のシンポジウムをまとめた文献です。
比較的新しい統計的分析手法であるSEMは、統計ソフトの計算によって、「A→B→C」とか、「A・B→C」とか、様々な変数間の関係をモデル化するわかりやすい手法です。
SEMは、人文科学分野と社会科学分野に広く普及しているのですが、その理由として、以下2点が挙げられています。
パス図による分析結果の視覚的わかりやすさ
マルチレベル分析、潜在クラス分析、欠測データ分析などの複雑な計算を必要とする高度な分析が可能
そして、モデルのあてはまりの良さを表す「適合度」の指標がいくつかあるのですが、このあてはまりを良くしようとすることを目的化してしまったり、常識から外れたモデルを作って主張してしまう傾向がみられるとのこと。
多くの問題や指摘に本文献の紙面を割いていることから、著者らのかなり大きな危機感と問題意識が伝わってきます。
何が注意すべき点であり、分析から漏れがちなのか?
ここが最も大切な点であり、かつ押さえておきたい点です。個人的にも、SEMを行う際のチェックリストとしても活用できそう、と感じました。
1.因果に関する誤った認識
著者らは、「基本的に調査データから因果を論じることができない」にも関わらず、SEM結果から因果が導かれた、という主張をしてしまうのが誤認である、と説明します。
一時点で取得したデータはもちろんのこと、二時点データで時間的に先行する説明変数と、遅行する目的変数における有意な回帰係数を得たとしても、それは必要条件の一部が満たされただけで、十分条件ではない、というのが定説のようです。
2.誤差間共分散の多用(乱用)
ある変数Aが、違う変数Bを説明するモデルを組む際に、A以外の要因を「誤差」と言います。モデル内に、C→Dも存在するとした際に、BとDが同様に変動するというのを誤差間共分散と言います(ものすごくデフォルメして説明しています)。
この誤差間共分散が適切なのは、縦断データ分析など限られた用途のはずが、モデルのあてはまりをよくするために使われることがあり、それが問題であるとの指摘です。そもそも、統計的には、誤差は何物にも相関しないはず、という本来的定義に反するようです。
また、例えば、確認的因子分析において、変数の誤差同士が共変動するなら、それは因子が観測変数を説明できていないことを示す、つまり、自身の仮定した因子の存在意義を薄めることに他ならない、とのこと。
3.甘い適合度指標に依存
SEMの適合度、つまりモデルのあてはまりを示す指標はいくつかありますが、CFIとRMSEAが2強のようです。しかし、これらは甘い指標としても知られているようで、この2つのみで適合度を判断するのは心もとない、とのこと。(CFIは.95以上、RMSEAは0.06以下、が基準)こうした基準の無批判な受け入れが問題な様子。
4.懸垂項目数
1つの因子にぶら下がる項目(下の図でいけば、楕円=因子/潜在変数、そこにぶら下がる長方形が懸垂項目です)の数が少ないことがあるそう。懸垂項目数は4つ程度なければ、内容的妥当性の観点で、本当にその因子を測定できているのか疑念が生ずる場合があるとのこと。
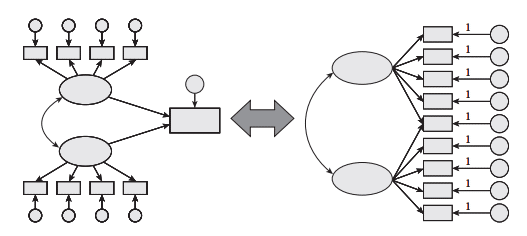
5.構造同値問題
上の画像の、左と右は、数学的に同じことを示しているのに、配置の仕方で違う印象を与えるようです。間違いではないにせよ、恣意的な見せ方をしていると誤解を与えかねないとのこと。
6.論文での報告不足
パス図や回帰係数、因子分析結果などを載せても、標準誤差や信頼区間を報告していないケースがよく見られるようです。(文字数制限の中で、どこまで載せるのか問題はありそうですが、、、)共分散行列も載せた方が、その後の研究をも含めた再現性の観点で望ましい、とのこと。
7.測定モデルと構造モデルを分離して2段階で分析していない
測定モデルは観測変数と潜在変数の因果関係を定義するモデル、構造モデルは潜在変数間の因果関係を定義するモデル、を指すようです。
(以下のサイトから表現をお借りしました)
8.モデル修正時の報告不足
有意性検定や適合度指標に基づいたモデルの修正を行った際に、修正過程や修正の根拠が示されず、恣意性が感じられるとのこと。理論的に説明が可能か、という観点からモデルの修正を行うべきであるようです。
これ以外にも、「個々人に働く心理過程や、個々人が保持している知識や態度の構造」を究明するという、心理学観点を無視した、個人間変動に基づく分析なども問題なようです。
実態としてのケース
文献の中で、ある教授は自分の過去の研究を振り返り、以下のように述べられていました。(少し救われる思いです)
「有意性検定の結果や適合度に振り回されていなかったかと問われれば、決してそんなことはないと断言することはできない。正直なことを言えば、事前に仮説は立てていたものの、想定していなかったパスを引いたら(または削除したら)どうなるのか、ということが気になっていた。
(中略)
しかし、心理学における理論は弱く、多くの場合、先行研究の知見は一貫していないことあら、厳密的な理論的予測を立てることはそもそも容易ではない。
感じたこと
実際に統計ソフトを使用して、モデル構築を試している立場とすると、耳の痛い話が多いです。。ただ、SEMというツールにより、モデル構築を目的化してしまう弊害や、研究において何に注意すべきか、という点を学ぶ教材としては大変有用でした。
しかし、統計手法そのものにより、ここまで厳しい目を向けられるものかと驚くばかりです。ツールの(ちょっとした)誤用・報告不足で、研究者たちが血のにじむ思いで作り上げてきた研究結果が世に出なくなる、ということも想像されます。
こうした、学問領域における作法は、スタンダードを下げないためにも重要なのだろうと感じ、まずは郷に入っては郷に従えの精神で取り組もうと思いました。