
Tableau Prepの作業を変えるTips集 5 ーデータの並べ替え、フィールド数を増やさずに並び替え(Lookup関数利用)ー

Tableau Prepユーザー会のNakajima2です。
Japan Preppin Data FamメンバーのPrep Tips集をご紹介します。
今回は第5回目、データの並び替えに関する2つのTipsです。
Prep Tips (9) : データの並べ替え PARTITION、ORDERBY関数
<中級者〜上級者>
Prepでデータ処理の作業を進めていると、データの並び順が不自然になってしますこと、けっこうありませんか? 規則性もなく、なんとなく、、
気分的に納得いかないことと共に、データの確認をしたい時に分かりづらいと感じた方も多いと思います。
こんな時に使える技が、PARTITION、ORDERBY関数。何回か前のバージョンアップで利用できる様になり、活用できるケースが多々あります。
初心者の方も、この関数が使える様になると、「ちょっと力ついたかな!」と思える関数です。これを機会に、是非覚えてみてください。
SQLとの比較
SQLでは、グループ化の構文として GROUP BY が使われます。また、並べ替えの命令としては、ORDER BY があります。
これに対応したPrepの関数が、
GROUP BY → PARTITION 関数 (グループ化)
ORDER BY → ORDERBY 関数 (並び替え)
になります。ただ、全く一緒の概念ではなく、Prep独特の利用方法があります。
この点、我がPrepユーザー会のマエストロ maes_data(マエス) さんがNOTE記事として「Tableau Prep分析関数Partitionを試したお話(SQLにあるが、Desktopにない)」で纏められています。
とても分かりやすい内容ですので、そちらもご参照頂ければと思います。
Prepでの利用方法は、独自の考えあり
PARTITION と ORDERBY。どちらの関数も他の四則演算などの関数と異なり、特殊な記載方法を取ります。また、分析関数(WINDOW関数とも言います)との組み合わせ記述が必要になります。
PARTIOTION関数
分析関数であるPARTITIONは、全体またはデータ セット内の選択行 (パーティション) を対象に計算を実行できます。
縦に並んだ状態でグループを作ってくれるところがポイントになります。

Prepでは PARTITION関数だけで利用することは出来ず、ORDERBYとセットで利用することが前提となります。
使い方は、次の通りです。選択行にランクを適用する場合は、次の計算構文の例です。
{PARTITION [Field]: {ORDERBY [Field]: RANK() }}
PARTITION (オプション):
計算を実行するフィールド(行)を指定
複数のフィールド指定も可. (例) {PARTITION [Field1], [Field2]: ・・・・・}
テーブル全体を使用する場合は、PARTITION部分を省略することで Prep が全行をパーティションとみなします。
ORDERBY関数と分析関数(上記例はRANK関数)はセットで利用します。
PARTITION関数でグループ化を指定したデータごとに、後半で利用する分析関数(上記例ではRANK関数)で並び替えなどのデータ整理を行えます。
ORDERBY関数
並べ替えとして利用します。PARTITIONがテーブル全体としている時は、ORDERBYのみを使用するケース記述方法がありえます。
構文例は、次になります(前述と同じ)
{ORDERBY [Field]: RANK() }
OREDRBY (オプション):
分析関数(ここではRANK関数)を使用する 1 つまたは複数のフィールドを指定します。
{ORDERBY [Field1], [Field2]: RANK() }
昇順(ASC)、降順(DESC)が指定出来ます。フィールド名の後に記載します( [Field1]ASC, [Field2]DESC など )。既定では、ランクは降順で並べ替えられるため、降順(DESC)を式で指定する必要はありません。
分析関数 Rank () など 並べ替えの指示を記述します。利用出来る代表的な関数は、次の通りです(24年4月時点、著者が試したことがあるものです)。
RANK ()、RANK_DENSE()、RANK_MODIFIED()、RANK_PERCENTILE()、ROW_NUMBER()、LOOKUP()
利用例 : Preppin Data 2023W35 より
*Preppin Dataの課題は、上のリンク先を参照ください
課題の途中段階で、Prepフロー中のデータ状況が、次の様になっていました。

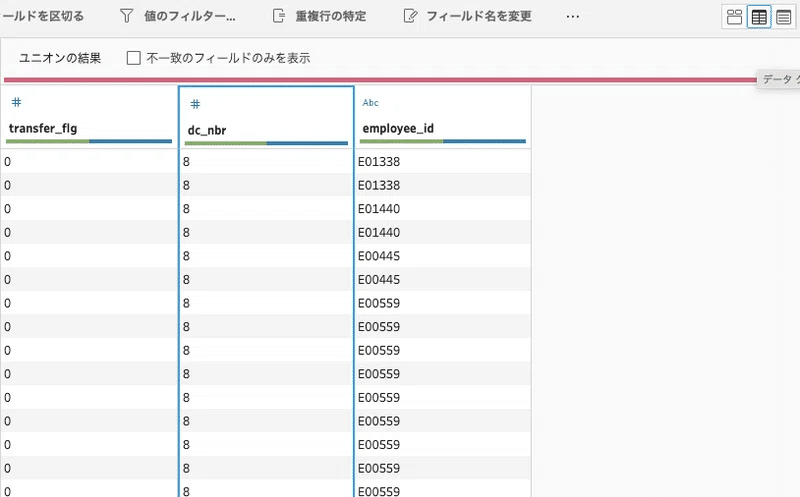
上の状況では、[dc_nbr]のフィールド データの並びが8が上の方に来ています。
これに対し、[dc_nbr]のフィールドをグループとして扱い、[employee_id]フィールドの内容で並べ替える(今回はRANK関数を使ってみます)例を以下に示します。
{ PARTITION [dc_nbr] : { ORDERBY [employee_id]asc : RANK()}}

これで、 [dc_nbr]のフィールド データの並びで1を上へ、[employee_id]フィールドもならえ変えることが出来ました。
まとめ
並べ替え以外にも、LOOKUP関数を使い上下のレコードにあるデータを同一レコード(自分のデータの横)に持ってくる などの処理をする際も、このPARTITION + ORDERBY の組み合わせは有効に利用出来ます。
覚えておくと大変便利で、ちょっとPrep(データベース)のことがわかったかな と思える関数です。
Preppユーザーのレベルアップを実感する上でも、是非 習得してみてみださい。
Prep Tips (10) : フィールド数を増やさず並べ替え LOOKUP([Filed],0)
<中級者〜上級者>
PARTITION と ORDERBY 関数を用いてデータの並べ替えなどが出来るようになりますが、上記のRANK関数を用いた並べ替えをした後に並べ替えで作成したフィールドを削除すると、せっかく並び替えたデータが元のバラバラな順番に戻ってしまうことがよくあります。
Tips(9)の例では、RANK関数利用後に[Rnak]のフィールドを削除すると、「同じデータのデータグリッドでの表示内容」で示したデータ並びに戻ってしまう現象です。
せっかく並び替えて、フローデータの最終出力をする際に、データ並びに戻ってしまっては それまでの努力が水の泡 なんて議論をよくしていました。
この対策として、昨年のPreppin Data勉強会で 2023w35 を課題の会で、Famメンバーの komatsu1 (@antipop1) さんが、目から鱗のTipsを発見しました。
LOOKUP関数
LOOKUP関数は、上下のレコードにあるデータを同一レコード(自分のデータの横)に持ってくる処理をしてくれる便利な関数です。
筆者も同じ課題でフローを作成する途中で、次のような利用をしてデータ処理を行なっていました。
{ PARTITION [employee_id] : { ORDERBY [month_end_date]ASC : LOOKUP([dc_nbr],1)}}
この処理は、
「 [employee_id]をグループ扱いし、 [month_end_date]を昇順に並べ替えて、[dc_nbr]の一つ下にあるフィールドからデータを取ってきて 」
というもの。
ここで計算フィールドで作成した新しいフィールドの値が、同一レコードの横に並んでくれることになります。
Prepにおける、典型的なLOOKUPの利用方法です。
LOOKUP([Filed],0)
上下の値を持ってくるLOOKUP関数のオフセット値に『 0 』を使った手法になります。
0 を使うということは、「自分自身の値を持ってきて」 になります。Prepユーザーとしては、ちょっと違和感がある処理だと最初は思っていました。
具体的利用例 2023W35から
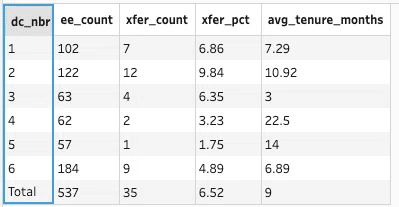
勉強会の参加者は、ほぼ全員 フロー最後の出力結果が下の様になっていました。

課題の段階で、[dc_nbr]フィールドに Total というデータを途中で作り、出力で求められた表では Total を一番最下列に並べる要求。
前述のORDERBY関数にRANK関数を用いて並び替えをしても、RANK関数で作成したフィールドを削除すると出力結果は上の表と同じになります。課題が達成出来ないと諦めて勉強会に臨んでいました。
Total は数字で無いし、手は無し。これはしょうがないと、、、
これに対し、komatsu1 さんの提示した技は、下記の通り。
{ ORDERBY [dc_nbr]ASC : LOOKUP([dc_nbr],0)}
関数処理後の結果が、こちら。
見事に[Rank]などの追加フィールドはなく、思い通りの並び替えが実現されていました。
まとめ
目から鱗のTips!! って、まさにこのこと。
LOOKUP関数で上下でなく自分自身を持ってきて上書きしちゃう発想。あっけに取られ、とても感心したことが忘れられないぐらいの出来事です。
人は大したもので、一度この手を覚えたら、その後はみんな普通に使う様になりました。業務で助かっている方も多い様です(そういう筆者も、その一人です)。
Preppin Dataの課題に対する最終出力の際に、並び替えを整理してデータ処理の間違え確認に利用することが大変 楽になりました。
業務でPrep処理の出力結果をExcelで利用するケースがある方は、Excelでの並び替えの機能はあるものの、Excel利用者がデータを最初に目にした時に内容を理解してもらえる速さが大きく向上するなどの 作業性向上のメリットもある様です。
オフィシャルな説明などで、このTipsは載ってない様です(24年4月中旬時点)。
口コミで、海外のPrepユーザーの間にも利用が広がっているとか。。
是非みなさんもPrep処理で使って頂くと、便利さに感動頂ける技だと思います。