
Preppin Data Practice #10 (25年1月 2024: Week 50 - Life Expectancy )

Japan Preppin' Data Fam 第10回目のPreppin' Data勉強会、25年1月のYouTube動画公開は、24年12月にPreppin' Dataで出題された全4題(W 49〜52)から2024W50 の課題にチャレンジです。
12月の課題、概要は次の通りです。

フローの集計の仕方を含め、参加者がどのような処理で対応したか。よくみて頂ければと思います。
ぜひ、アーカイブ配信動画と合わせてご覧ください。
Preppin' Data勉強会の配信動画(YouTube)はこちらです
https://youtu.be/m1IJPrSiW8A?si=q6zlK4GV_s8gOJa0
1)課題の内容
今回取り上げたW50のPreppin' Data 課題は、下記を参照ください。
出題の背景、対応項目
2021年、世界の平均寿命は70年を超えました。
これは、わずか200年前には40年未満だったことを考えると、驚くべき進歩です。1800年には、平均寿命が40年以上の地域は存在しませんでした。
平均寿命の伸びは、栄養、衛生状態、きれいな水、新生児ケア、抗生物質、ワクチンといった医療の進歩、さらに生活水準の向上、経済成長、貧困削減などの成果を反映しています。
どの国が大陸の平均寿命を上回っているのか、また寿命が最も劇的に改善した国を見ていうPrepフローの作成が、今回の課題となりました。
入力データ
このデータは Our World in Data から取得されたものです。以下の2つのテーブルがあります。
• 平均寿命(Life Expectancy)

• 国と大陸のリスト(List of Countries - Continents)

課題の要件
データを入力する。
各年ごとの国別平均寿命と大陸別平均寿命のフィールドを作成するためにデータを整形する。
1950年から2020年の年だけを含むデータをフィルタリングする。
1950年から2020年の期間で、各国の寿命が大陸平均を上回った年の割合を算出する。
各国の1950年から2020年までの寿命の変化率を計算する。
大陸ごとに寿命の変化率が最も高い上位3カ国を表示する。
結果を小数点第1位まで四捨五入する。
データを出力する。
出力
フィールドは以下の5つ:
1. 大陸(Continent)
2. 順位(Rank)
3. 国(Country)
4. 大陸平均を上回った年の割合(% Years Above Continent)
5. 寿命の変化率(% Change)
• 合計18行(ヘッダーを含む19行)
2)オープン(統計)データなどでの平均値の扱い
今回は、オープンデータ、統計データを利用した前処理の実例になる課題です。データの扱いにおいてデータソースに最初から入っている集計値、今回のデータでは「平均値」の扱いが注意すべき点です。
参加者の説明で、Riekoさん、たっくんさんもこの「平均値」に関する点触れていますので、アーカイブと合わせて確認してください。
国や地域を扱った統計データの場合、データに最初から記載されている「平均値」をどの様に扱うかによって、計算結果が異なってくることがあります。
今回課題のデータでは、各国の平均年齢と、大陸の平均年齢(こちらが最初から記載されている「平均値」になります)の内容を見極める必要があります。
この平均値をデータに最初から記載されている値を利用するか、フロー上で各国のデータから集計作業を行い平均値として利用するか、ここをよく考慮して作業を進めるかが、要件に書かれてない重要事項になっています。
今回は、参加者の発表内容を見ていく前に、この「平均値の扱い」について最初に見ていくことにします。
早速、Prepを利用して、2つのデータソース内容を確認してみましょう。
最初は、「平均寿命(Life Expectancy)」のデータです。データ接続後のインプットペインの内容になります。
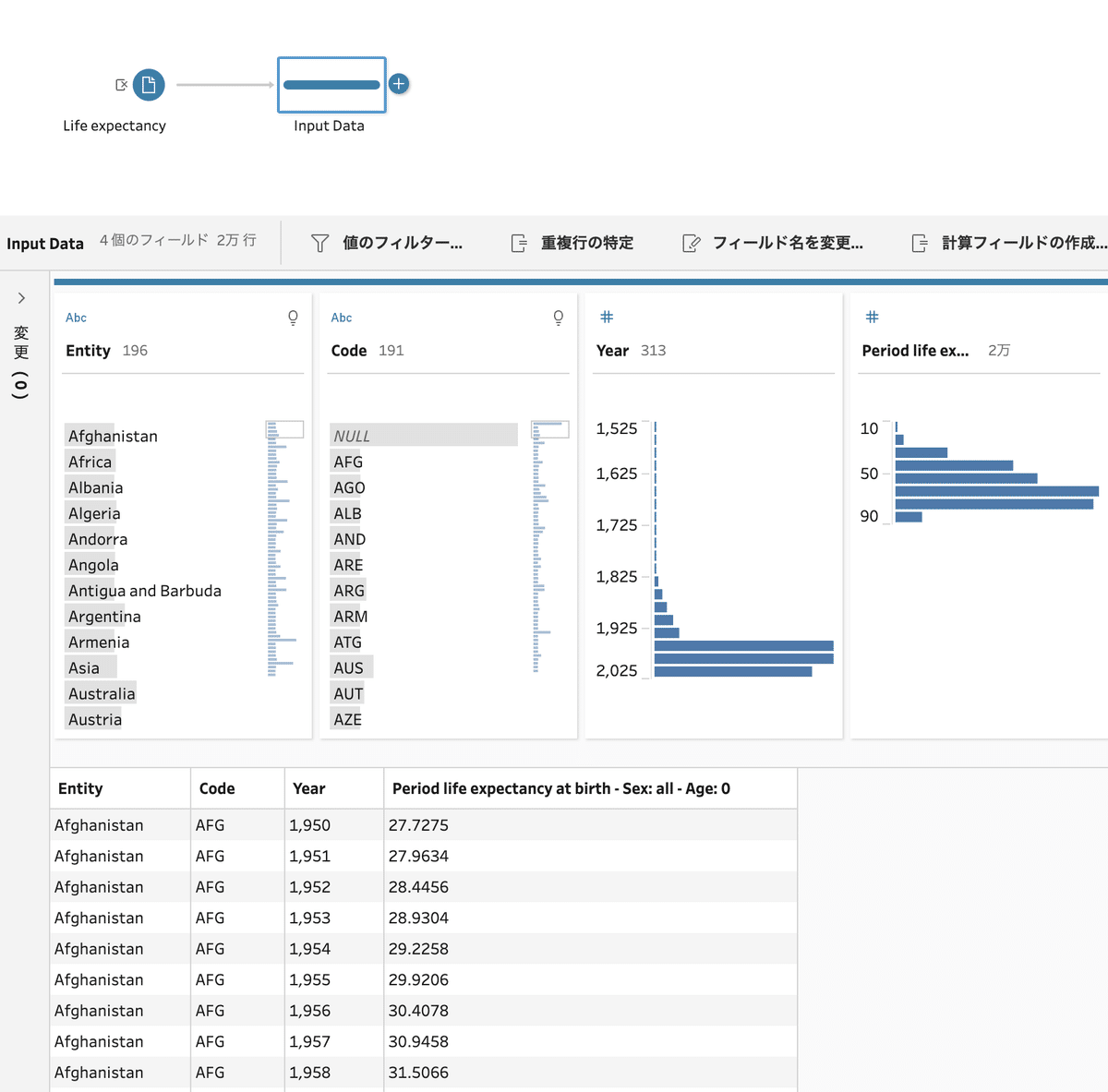
[Entry] フィールドは国の名前を、 [Code] フィールドは国コードを表していると思われます。よく見ると、[Code] フィールドに「NULL」の値が多くあることが分かります。
以下で、「NULL」の値の中身を確認してみましょう。
[Code] フィールドの「NULL」を保持して、詳細確認してみます。[Entry] フィールドに大陸名を示すと思われるデータが6つあるのが分かります。
この6つのデータには、 [Year] と [Period Life Expectancy…] の両フィールドにデータが存在しています。

次に、「国と大陸のリスト(List of Countries - Continents)」のデータを確認しましょう。同様に、データ接続後のインプットペインの内容になります。
[Continent] フィールドに、上記 [Code] フィールドで「NULL」となっている[Entry] フィールドに大陸名と同じ6つのデータがあることが分かります。

このことから、大陸名を示す6つのデータには、「平均寿命(Life Expectancy)」のデータソースに既に各年の平均寿命の値が入っていることが分かります。
今回のような統計データの場合、(1)平均値が既にデータ内で示されている場合はその数値を用いてデータ処理を行う必要があります。
(2) 各国のデータを大陸ごとに個別集計した平均値は、(1) で示される値と一致しないケースが良く見られます。ここは、重要な注意事項です。
(2)のケース、例えば、データ内に 国にA、B、Cの3カ国があり、それぞれのデータが10、20、30とします。この3つのデータの平均値は「20」になりますが、統計データには国の平均的値として「25」のデータが元々入っているケースがあります。
「20」と「25」の差、「5」は「その他の国」に相当する値を考慮した統計値になります。データソースに「その他の国」分がデータとして存在してないのに、統計データとしての平均的値が「25」としてデータが存在しています。
このような場合、平均値としてはデータソースに最初から存在するデータを「平均値」を利用する必要があります。
今回の課題では、元々データソースにあるこの「平均値」を利用しないと、Outputの回答データと合わない結果になります。注意が必要です。
勉強会の参加者発表では、既に (2) のトラブルをフロー作成時に体験済みで、発表の際は (1) に辿り着いた結果を説明してくれています。
このことを念頭に置いて、参加者の以下 説明内容やTipsをみていってください。
3)参加者の解答例、Tipsなど
大陸データの分離(NULLの利用)
各国のデータと、大陸のデータ(「平均値」)を仕分けて利用する方法です。「国と大陸のリスト(List of Countries - Continents)」のデータで、[Entry] フィールドに各国名と大陸名が一緒に存在しています。この各国名と大陸名を仕分けして、各国と大陸ごとの平均寿命を分ける必要があります。
前述の通り、 [Code] フィールドに「NULL」がある点をうまく利用する方法が最初の方法です。
山ちゃんさんは、[Entry] フィールドで大陸名が入っているレコードで、 [Code] フィールドで「NULL」となっている点に注目しています。データをクリーニングステップ2つに分けて、それぞれで ISNULL関数 を利用して国と大陸を抽出する操作をします。



[Code] フィールドの「NULL」利用せず、 平均寿命(Life Expectancy)と 国と大陸のリスト(List of Countries - Continents)のデータを別々に結合することで、[Country[ と [Continet] を作る方法も紹介されました。


大陸の平均を超えた各国の年数をカウントする
いろいろな処理方法があります。ここではフラグを数値で作る方法を紹介します。
山ちゃんさんは、IIF関数を利用した方法で、スッキリ分かりやすい条件式を用いています。各国の平均年齢が大陸の平均年齢より大きい時は1を入れるフィールドを作っています。この数値を後ほど集計で合計する操作をしています。
IIF([Country Avg] > [Continent Avg], 1, 0)
Riekoさんは、通常のIF関数で同じ計算をしています。
IF [Country Avg] > [Continent Avg] THEN 1 ELSE 0. END
1950年より前のデータをフィルターする
今回のデータソースでは、1543年からの統計データが含まれています。
要件では、1950年以降のデータにフィルターをかける指定があります。Prepフローの処理でデータ量を減らし処理速度を向上うせる観点から、出来るだけ早い段階でデータ量を少なくする操作が重要になります。
1950年以降のデータにフィルターをかける処理は、一般的にクリーニングステップで操作する場合が多いのではないでしょうか。
Mr. もりたは、データソース接続の段階でこのフィルター処理を実施しています。早い段階でデータ量を減らす観点では、大変重要な操作になります。

1950年と2020年のデータをフィルタする(データ量の調整)
今回の課題においては、長い期日の寿命に関するデータが含まれているものの、実際に集計で利用するデータは、1950年と2020年の2つの年のみで、両者のデータを比較することを求められています。
データの前処理は、出来るだけ早い段階でデータ量を少なくする(不要なフィールドやレコードを削除する)ことが処理速度向上の観点からも重要です。
よって、今回は1950年と2020年のデータのみにフィルタをかけてデータを絞る方法が有効です。
たっくんさんは、フィルターで1950年と2020年のデータのみを抽出した後、各国の1950年から2020年までの寿命の変化率を計算を、デフォルト機能の「次との差の割合」を利用して計算しています。効率の良い方法です。


LOOKUP関数を利用した関数式になっています
mitamuuさんは、1950年と2020年のデータ絞り込みにパラメーターを利用する方法を紹介しています。
フローの中で、2つの年のみにデータを絞り込んでおくことで、たっくんさんと同じく「次との差の割合」を利用してレコード数を少なくして処理を進める方法を使っています。

数値の丸め(ROUND関数)
小数点以下1桁で数値を丸める必要がありますが、山ちゃんさんは他の計算式と併せた数値丸めの処理を1回で行っています。処理ステップ数を減らす、良い操作方法です。
ROUND(
FLOAT([Years Above Continent Avg] / [Year]) * 100
,1
)
ROUND(
FLOAT(
([2020 Country Avg] - [1950 Country Avg])
/
[1950 Country Avg]
) * 100
,1
)
3)その他
LOD(FIXED)関数の利用
四則演算の計算を行わせるために、1950年と2020年の平均年齢データを新しいフィールドとして横に並べ、計算式のフィールドに供する方法が説明されました。
Riekoさんは、次のFIXED関数を持ちて1950年と2020年の平均年齢データのフィールドを作成しています。
{ FIXED [Country] : SUM( IF [Year] = 1950 THEN [Country's Avg ) END)}
{ FIXED [Country] : SUM( IF [Year] = 2020 THEN [Country's Avg ) END)}
Nakajima2 は、1950年から2020年の年数をカウントする方法をFIXED関数で集計しています。
{ FIXED [Country] : COUNT([Year])}
SQL、Pythonでやってみたら!
RiekoさんがSQLとPythonの取り組みなのですが、week50もGitHubにアップされました。
SQLでどうやるのかな?と思ったの人の参考になればとの、Riekoさんご意向です。下記をご参照ください。
4)参加者が回答したPrep フローファイル
勉強会に参加したメンバーが作成したPrepフローのファイルを公開致します。
このブログ、動画アーカイブをご覧頂いたみなさまで、ご自分で手を動かしフロー作成をされた方の少しでもご参考になればと思っています。
下記のリンク先にフローファイルを保存しています。みなさまのお役に立てれば幸いです。
https://drive.google.com/drive/folders/1CLn_VVicMGEftDQPTtnc-pqvvm1v5da-?usp=sharing
5)おわりに
今回で10回目の勉強会 公開配信(ビデオ解説)になります。
それぞれが他の参加者から得た気づきを持ち帰り、実務で応用する機会が得れたと感じています。
世界各国の平均寿命を元にしたデータの課題で、課題では2つの年に絞った要件となっていました。
データは1543年から毎年のデータが蓄積されているものであり、データを可視化してみると歴史的な意味が汲み取れる内容となっていました。Preppin' Dataの課題から考えさせられるところがありました。
この観点、Mr. もりたがXツイートにコメントを入れられています。
リンク先にVizもあるので、ご覧頂ければ。
さらには英国は平均寿命のデータが、1543年からある(毎年ではないが)という衝撃 https://t.co/qYnKgjTeTY pic.twitter.com/m38smb52q9
— もりたひろあき | Hiroaki Morita (@hiroakimo_tw) January 19, 2025
Preppin' Data勉強会では、新規参加者を募集しています。
・Prep使ってみたい
・仕事で使っているけど ちょっととっつきにくい
・Preppn' Dataの初心者向け課題を始めました
という方々、一歩踏み出してスタートすると想像以上に力がつきます。実務でも役立つTipsが 目から鱗いっぱいありますので、是非ご参加ください。
参加希望の方は、下記までメールご連絡をお願いします。
Tableau Prepユーザー会 : tableauprep.usergroup@gmail.com