
Preppin Data Practice #05 (24年8月 2024: Week 31 - Olympics Special -)

Tableau Prepユーザー会のNakajima2です。
Japan Preppin Data Fam 第5回目のPreppin Data勉強会、24年8月のYouTube動画公開は、24年7月にPreppin Dataで出題された全5題(W 27 〜31)から2024W31 の課題にチャレンジです。
7月のPreppin’ Dataは、スポーツ月間として F1レース、ウインブルドンテニスなど、パリ オリンピック開催にちなんだテーマを取り上げたシリーズ企画が行われました。
競技に対する基礎知識の確認も必要となり、処理レベル的にも難しい、実務に近い課題も多くありました。
今回の課題は、データソースとするExcelファイルが、セル結合が多くされた実務でもあるあるの形式になっているデータです。
セル結合された値をどう処理していくかが、データ前処理としての作業のポイントになっています。
以下、課題の内容、対応のポイント、参加者の解答例をご紹介します。
Preppin Data勉強会の配信動画(YouTube)も、以下リンク先からご覧ください。
公開した動画はこちらです。
1)課題の内容
7月に提示された課題は、次の5つです。

スポーツ月間と銘打たれ、ツールドフランス(自転車レース)、F1(自動車レース)、ウインブルドン(テニス)、国際5大サッカー大会、女子7種競技がテーマに取り上げられました。
スポーツ好きにはたまらないテーマですが、データフローの処理にはそれぞれの競技に対する知見が必要でした。ドメイン知識と言われる専門的な知見が、フロー処理に重要になる事例です。
Prepの処理フローを行う技術レベルも中級以上のものが求められており、より実務的な課題であったと思います。
今回取り上げたW31のPreppin Data 課題は、下記を参照ください。
https://preppindata.blogspot.com/2024/07/2024-week-31-olympics-special.html
・出題の背景、対応項目
今回取り上げたWeek 31のチャレンジでは、2023年8月の世界陸上競技選手権の女子七種競技のデータを使用します。
七種競技で勝利を得るために、選手は特定の競技に特化するか、全体でのバランスを重視すすかのどちらが有利かを分析し、選手の特徴にあった競技対応を行います。今回テーマとなった特に、2023年8月の世界陸上競技選手権の女子七種競技では、アメリカのAnna Hall選手が7種目中5種目でトップ3に入ったにもかかわらず、金メダルを獲得できなかったことに着目しています。
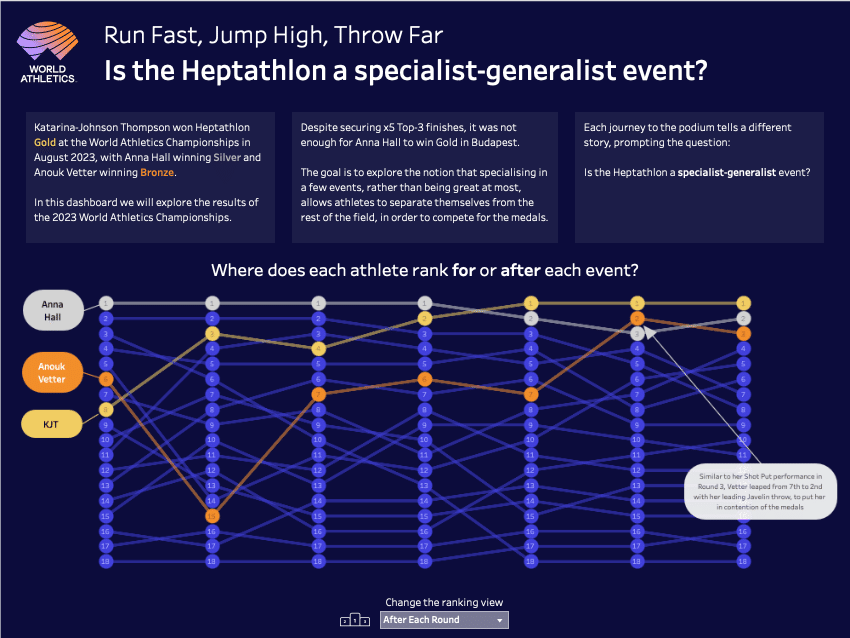
Preppin’ Dataの課題としては、具体的に選手の順位やポイントに基づいて分析を行い、複数の競技で特化することと全体でバランスよく競技することのどちらが有利かを検討します。作成したフローの出力データは、画面に映しているTableau DesktopのVizとして表現するための接続データとして利用することを想定しています。
・データソース、Outputデータ
データソース
Excelファイルで提供されたワークシート2種からのデータソースになります。
アウトプット
13フィールド、126列になる次のようなデータです。
13 fields
Position
Athlete
Nationality
Total Points
Event Name
Event Type
Event No.
Event Time/Distance
Event Points
Event Position
Rolling Total Points
Position After Event
126 rows (127 including headers)
2)対応のポイント(Requirementsのポイント)
要求項目から、処理として対応すべき概要は次の通りです(要約した内容です)。
データの入力とフィールド名の変更
重複フィールドの削除
NULL値の補完(Fill Down)
総ポイントフィールドから文字を削除
データをピボットし、競技ごとのデータに変換
イベント参照テーブルとの結合
括弧内の順位情報を分割
順位とイベント番号順にソート
出力データの確認と保存
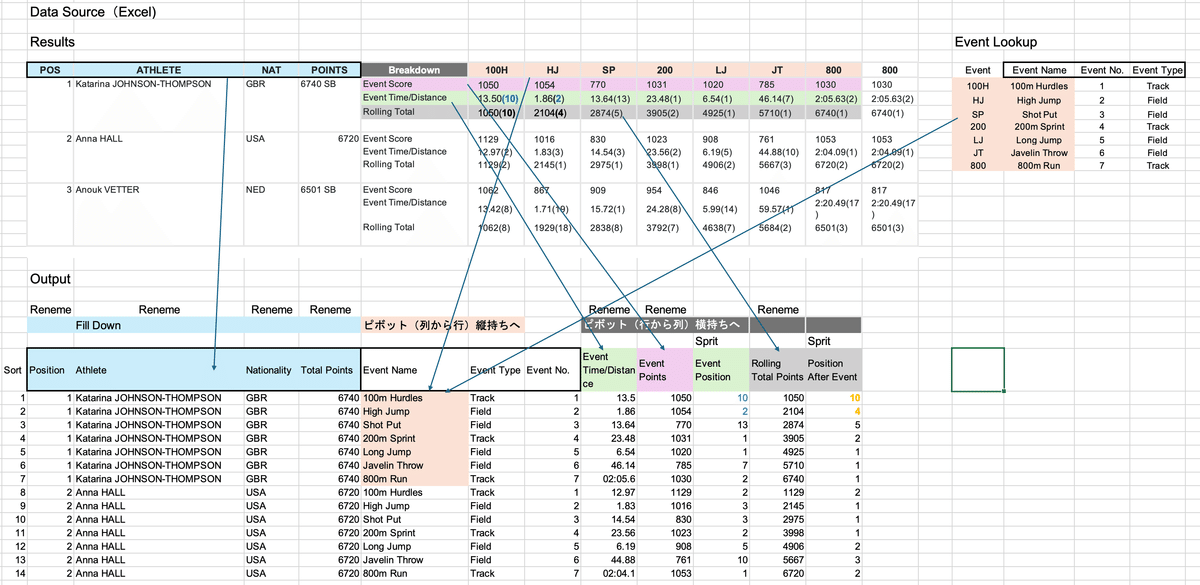
データソースのExcelファイル(ワークシートは2つ)と、アウトプットの関係を示します。
今回の課題では、Fill Down、ピボット(2種)、結合、値の分割(抽出)を利用して、データを整理することになります。下の図で、網掛け色付けしたセルを矢印の関連で整理を行う処理を実施します。
3)参加者の解答例、Tipsなど
対応のポイントに沿って、参加者の回答方法を説明します。
セル結合されたExcelデータの前処理
Prepでデータ接続をする際にデータインタプリタを利用するかどうかでデータ接続後のデータ状況が異なっていました。
元となるExcelデータの形式は、次のようなものでした。[POS]、[ATHLETE]、[NAT]、[POINTS] の列は、4行づつセル結合された形になっています。

(A)データインタプリタを利用しない場合
データ接続時にデータインタプリタを利用しない場合は、セル結合されたデータは3行となっています。4つのフィールドでは2行に値がない(NULL)状態となっていました。
これらフィールドに対して、NULLを埋めるFIll Downの処理が必要です。

・4つのフィールドをそれぞれ Fill Down
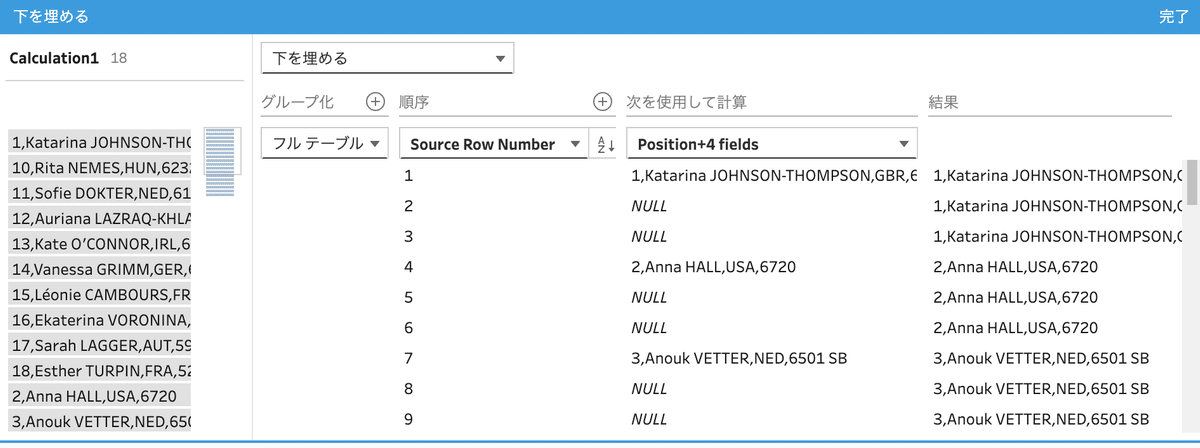
RiekoさんからTipsです。
Prepのデフォルト機能を利用し、UIで設定するFill Downの実施例です。簡単な操作でNULLにデータが埋められます。

ひとつ問題があります。デフォルト機能を利用した下を埋める処理において、rkフィールド名は元の名称をそのまま利用する(上書き計算させる)ことはできない仕様になっています。
このため、下を埋めた後の残った元フィールドは削除をしています。必要に応じ、新しく作ったフィールドの名称を変更する処理も追加することになります。

これに対する対処方法は、Mr.もりたが提示。
デフォルト機能で一度Fill Down処理を行い、作成された計算式を別途作成する計算式に同様に記載(可能であればデフォルトの式をコピペ)することで、計算式にフィールド名が記載できるメリットが出ます。
[Position]
{ORDERBY [Source Row Number]ASC:LAST_VALUE([Position],TRUE)}
フィールド名が1回で指定出来る
・フィールドをまとめて1回だけ Fill Down : Aiさん
FIll Downの操作を4回行う手間を省くため、Aiさんは 4つのフィールドを繋げる計算式を別フィールドを作り、その別なフィールドに対して1回のFill Down処理で作業工数削減を行なっています。
処理個数は前述のFill Downを4回行なった事例と同じ程度になりますが、値の分割が1回の操作で出来ることから、作業の手間は短い上手い方法ですね。
[Position+4 fields]
STR([Position])+","+[Athlete]+","+[Nationality]+","+[Total Points]

(B)データインタプリタを利用した場合 : たっくんさん
データ接続時にデータインタプリタを利用しない場合は、セル結合されたデータは3行となっていましたが、データインタプリタを利用すると、Excelでセル結合されている部分のデータが、自動的にFill Downされた状況でデータ接続されています。データの行数は4行となり。最後の1行はNULLとして表示されています。
データインタプリタを利用することで、FIll Downを行わなくてもデータが埋まっている状況で、処理手順を減らすことが出来る事例です。最後の1行で出ている「NULL」についてのみ、削除の作業が必要です。


4行でFill Downされてデータが全て入っている状況です。
2種類のピボット処理(列から行へ、行から列へ)
(C)7種の競技名に関するデータを横持ちから縦持ちに、(D)[Breakdown] のデータを縦持ちから横持ちに変換する処理をそれぞれ実施します。

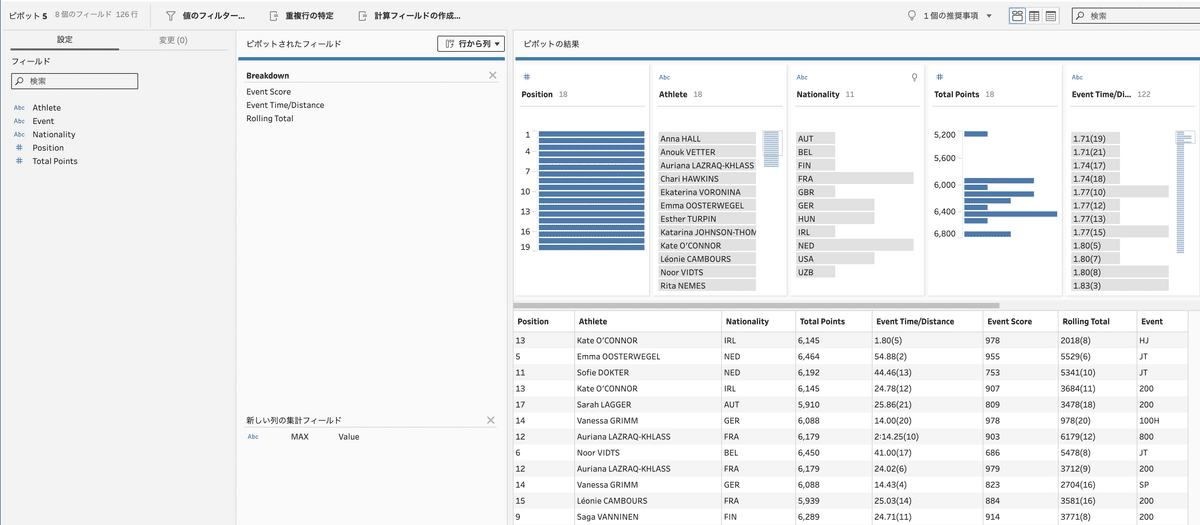
C)7種の競技名に関するデータを横持ちから縦持ちに
データソースにおいては、7種の競技に関するデータが横持ちなっています。列から行へのピボットを使い、データを横持ちから縦持ちに変換します。
ピボットの後に実施するデータソースの「Event Lookup」ワークシートのデータと結合処理をするための前処理を行う意味合いも兼ねた処理になります。

(D)[Breakdown] のデータを縦持ちから横持ち
[Breakdown] のデータを横持ちに変換します。
各競技の結果と競技終了時の順位を求めるための前処理として、列から行へのピボットでデータを横持ちに直します。
(D番外)[Breakdown] のデータを縦持ちから横持ちを使わない Aiさん
ピボットをせずにFIXED関数を利用し、データを横持ちと同じにしてから、フィルタ処理で余分な行を削除することで、ピボットと同じ結果得ています。
こちらもナイスアイディアです。


各競技の結果と競技終了時の順位を求める (値の分割、文字列の抽出)
処理の方法として、値の分割を利用する方法と、文字列のデータ抽出、修正を行う方法が使われていました。
(E)値の分割
デフォルト機能で値の分割を利用してデータ抽出を行います。
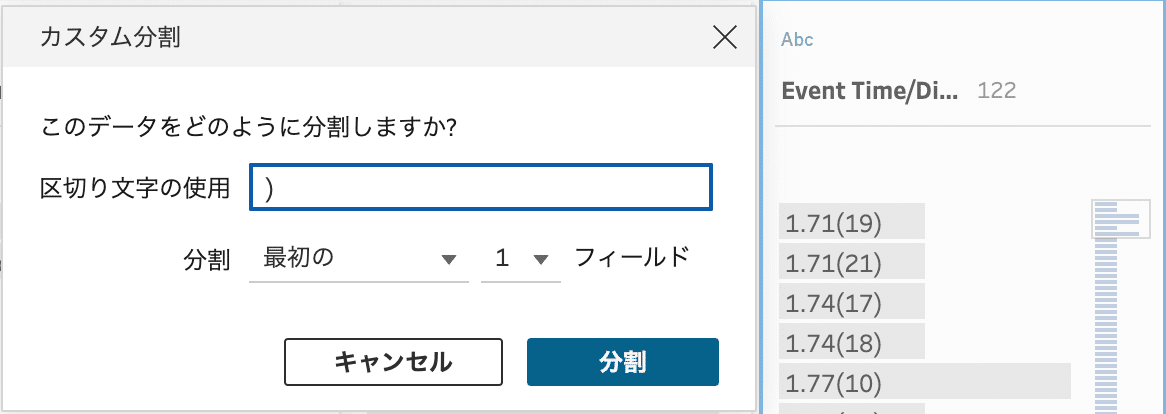
また、デフォルト機能で記載された計算式をコピペして複数の関数を併用して使うことで、ステップ数を減らした上手な処理をされている参加者もいました。

(F)文字列のデータ抽出
データの抽出方法は、参加者様々な方法で対応をしています。
たっくんさんは、値の分割とREPLACE関数の利用によるデータの抽出、修正が一般的ですが、正規表現を利用した文字列処理を上手く利用してデータ処理を行なっています。
[Rolling Total]
INT(split([Rolling Total],"(",1))
[Position After Event]
INT(REGEXP_REPLACE(split([Rolling Total],"(",2),'[^0-9]',""))
4)その他
Mr.もりた からのTipsです
FIll Downを行うために、データソース接続時に [Source Row Number] を利用していますが、そのまま [Source Row Number] を保持した状態でピボット処理を行うと、2回目のピボット処理時に行数が増える結果となってしまいます。
Riekoさんがこの状態になり、後半の作業で行数を減らす処理などを行なっています。
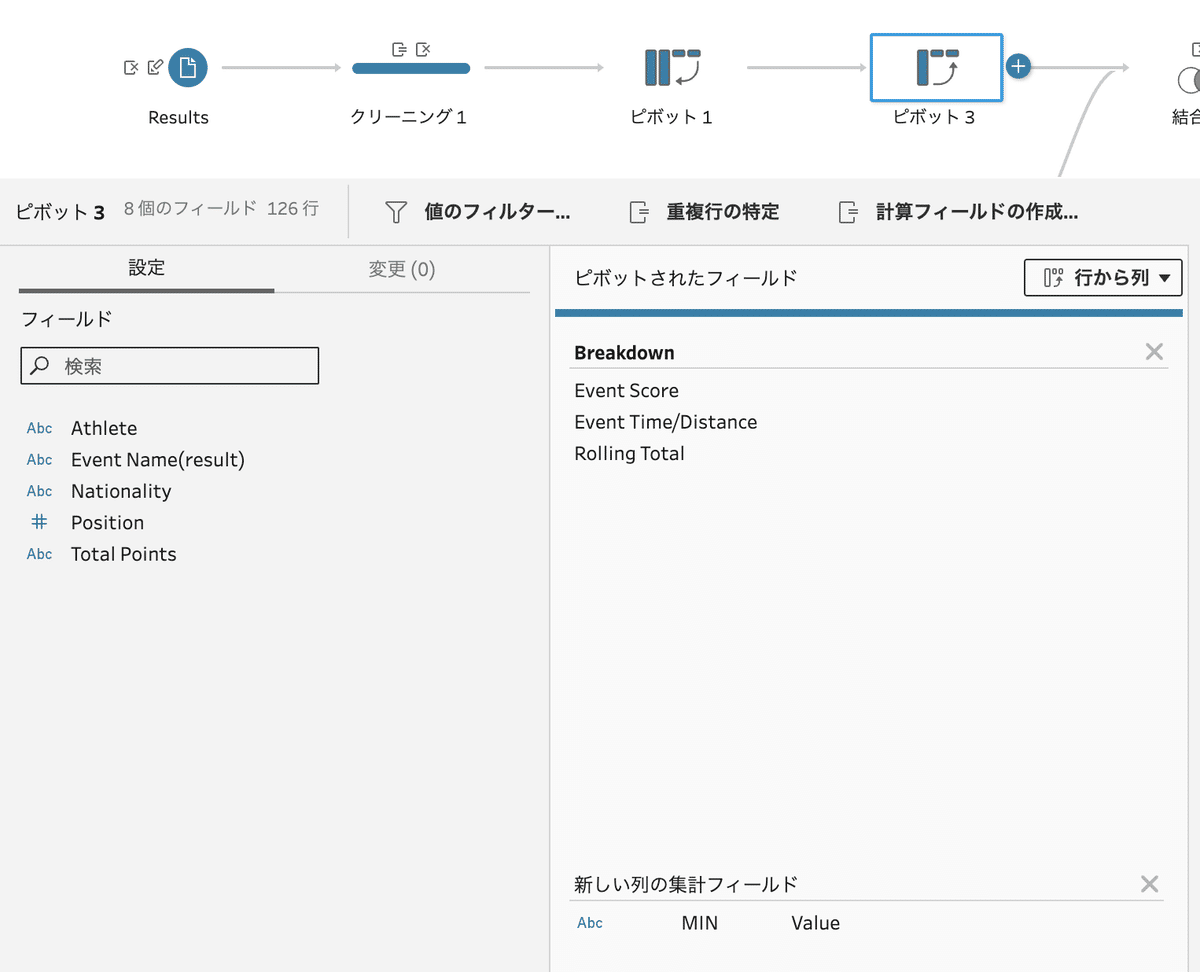
行数は126行で正しい状態です

行数は378行で、横持ちにする [Breakdown] の3フィールド部 行数が増えてしまう(NULLが残る)
結合処理をする前に、キーフィールドとして利用するフィールド名をわざと違う名前にしておくTipsも紹介されました。
結合後に削除するフィールドのフィールド名を変えておくことで、結合後に保持すべきキーフィールドのフィールド名を変更することなく処理ステップを減らせるメリットがあります。

5)参加者が回答したPrep フローファイル
今回からの新たな試みとして、勉強会に参加したメンバーが作成したPrepフローのファイルを公開致します。
このブログ、動画アーカイブをご覧頂いたみなさまで、ご自分で手を動かしフロー作成をされた方の少しでもご参考になればと思っています。
下記のリンク先にフローファイルを保存しています。みなさまのお役に立てれば幸いです。
https://drive.google.com/drive/folders/1cUqz3PGZGSrReH66synHhjvbCVtUg9AH?usp=share_link
6)おわりに
今回で5回目の勉強会 公開配信(ビデオ解説)になります。
毎回感じることですが、他のメンバーから聞く発表で新たな発見があり、知識の習得、定着が深く図れていると感じています。
今回は、専門的なドメイン知識が必要となり、フロー作成自体が分かりづらい、そんな実務で良く出くわすケースも多く見受けられ、実践的な課題であったと感じています。
そんな中でも、参加者からの自分とは違う見方、処理方法を見させてもらい、学ばせて頂いた思える会でした。
みなさんからの学び、ほんとに 関連知識が増えます。
よければ、是非ご一緒に学び合いの場にご参加頂ければと思っています。
Preppin Data勉強会(Japan Preppin Data Fam)では、新規参加者を募集しています。
初心者の方も大歓迎。Tableau Prepが使い慣れた中級以上の方も、目から鱗いっぱいありますので、よろしければご参加ください。
参加希望の方は、下記までメールご連絡をお願いします。
Tableau Prepユーザー会 : tableauprep.usergroup@gmail.com