
Tableau Prep Tips集23 ーデータ接続ー

Japan Preppin Data FamメンバーのPrep Tips集をご紹介します。
今回は、データ接続です。
Prepにファイルなどを読み込む際まずは最初に利用しているデータ接続ですが、
・フィールドの調整(型変更、削除など)
・ヘッダ位置の調整
・データインタプリタ(不要なヘッダなどの自動調整)
・テキストファイルの区切り記号の指定
・ワイルドカードユニオン
など、気が利く機能が付いているのご存知でしょうか?

今回は、Prep の操作画面の中で、「データ接続ペイン」と「インプットペイン」でお目にかかる、良く使いそうな操作、機能に関して。
知っているとちょっと便利な、データ接続にまつわる機能をご紹介します。
Prep Tips (43) : データ接続
1)データ接続ペイン
データの接続は、クラウド上の各種データベースからのデータ接続や、ExcelやCSVなどのテキストファイルに接続して利用するケースが多いのではないでしょうか。
Prep画面左側にある青色のペイン。ここで + を押すと、接続するデータの種類、データの保管場所を指定することが出来ます。
ExcelやCSVなどのファイルは、Finderなどのファイル系アプリからのドラッグアンドドロップでPrepに接続させることも出来ます。

(A) データインタプリタ
データ接続するExcelファイルでセル結合でヘッダ情報が数段にまたがって記載されている場合、Prepでヘッダ情報を自動的に補正する機能です。
完全な補正がされないケースもありますが、手作業で修正する手間がある程度省ける機能になります。
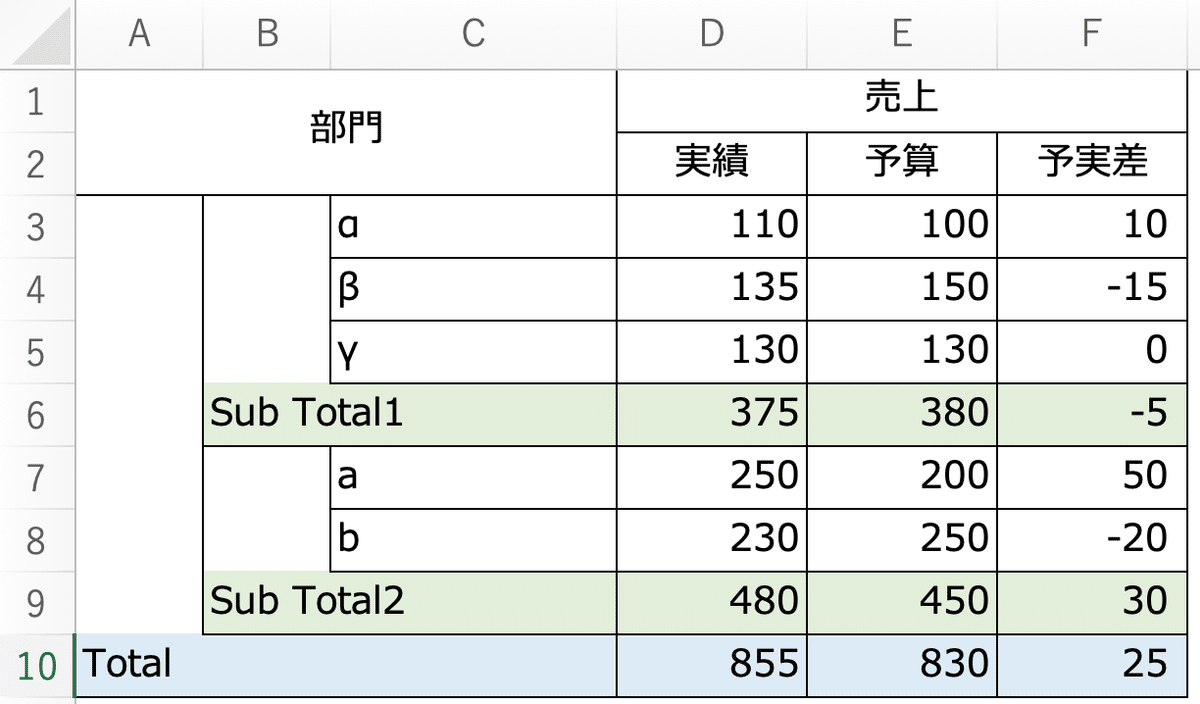
上のようなExcelファイルで、データ接続ペインに表示される「データインタプリタの使用」のチェックをすることで、ヘッダ情報を自動で修正してくれます。

「データインタプリタの使用」せずにデータ接続を行うと、フィールド名にF2、F3などが表示されて、フィールド名として利用したい「実績」、「予算」などがデータとして扱われています。
これに対し、データ接続ペインに表示されている「データインタプリタの使用」にチェックを入れることで、ヘッダ部分が良い感じでフィールド名に読み込まれます。
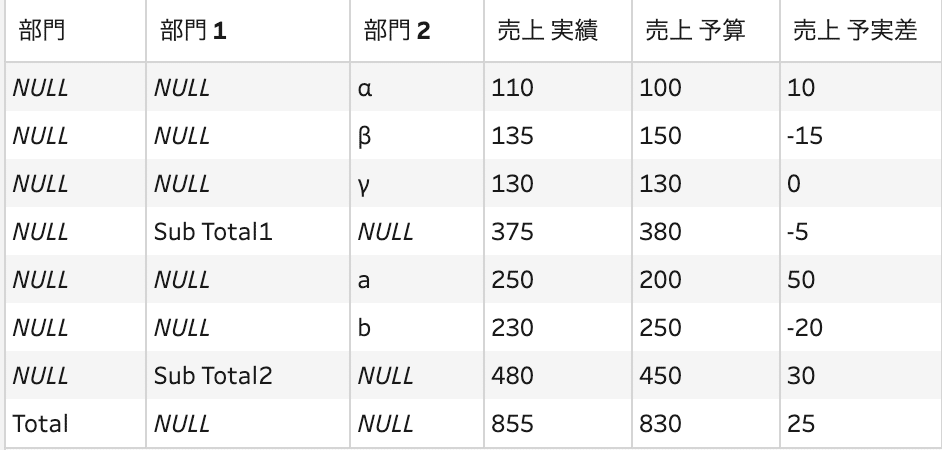
この例では、「売上 実績」などに「売上」と「実績」が合わさったフィールド名になっていますが、フィールド名の変更のみで対処出来、データ整列の作業手間が大幅に削減出来ます。
2)インプットペイン
インプットペイン画面では、4つのタブが設置されています。
今回は、「設定」と「テーブル」タブで利用機会の多い機能を取り上げます。
「設定」タブ
(B) <お勧め> フィールドリストでのフィールド削除、型変換
データの前処理加工作業において、不要となるデータは出来るだけ早い段階で削除するなどデータ量を減らしておくことが重要です。
100万行以上のレコードや、多数のフィールド(列)が含まれているようなデータ量の多い場合にはデータ量の削減は特に有効です。前処理加工で利用しないフィールドがある時は、データ接続の時点で不要なフィールドを削除しておくことが出来ます。
データ量の削除は、Prepの後で行う各種作業の処理速度向上が期待出来ます。
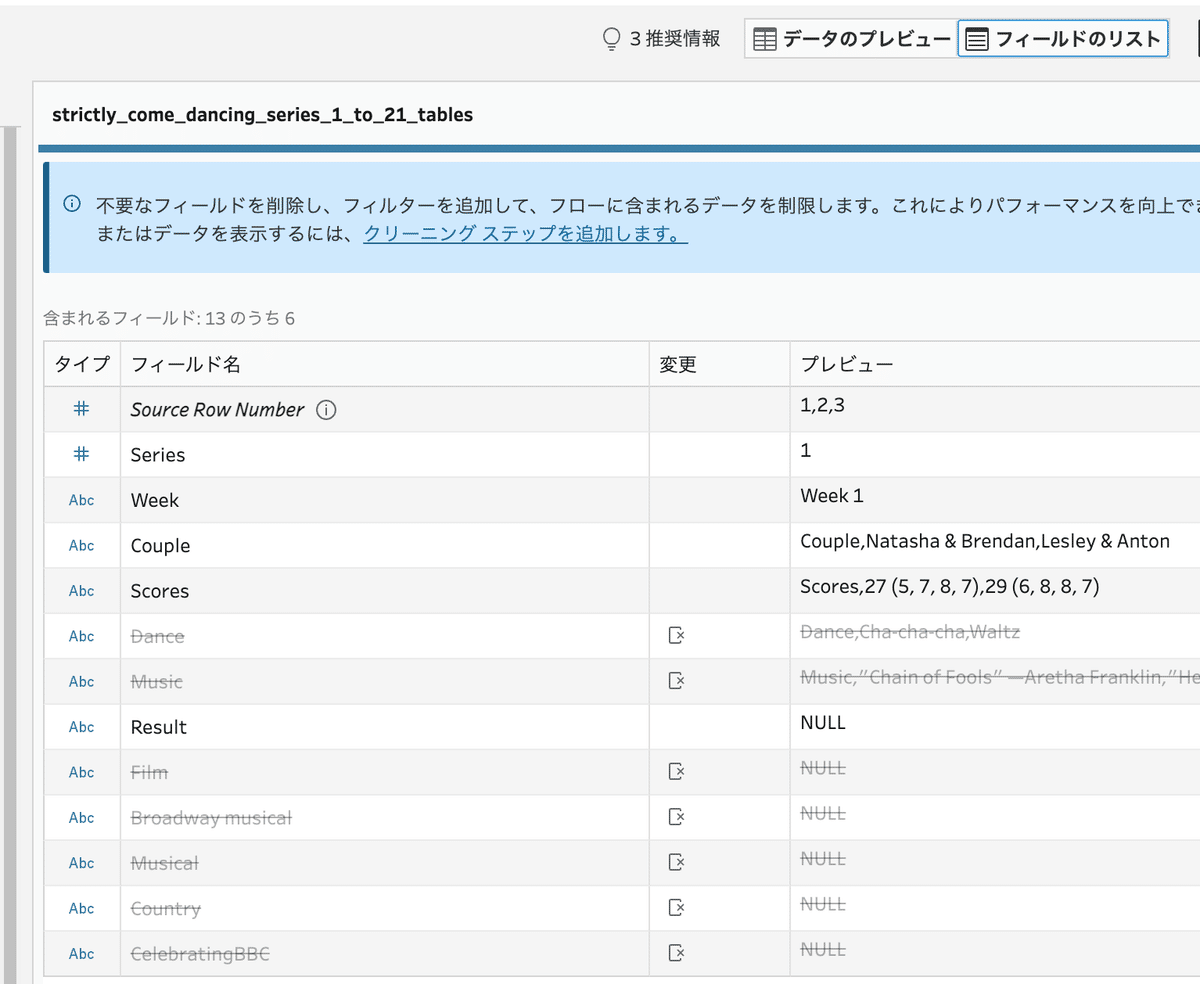
取り消し線がついている7つのフィールドをデータ接続時点で削除している
「フィールドリスト」で削除したいフィールドをを選択し、 X をクリックすると削除が出来ます。上の様に、削除されたフィールドは取り消し線が表示されます。
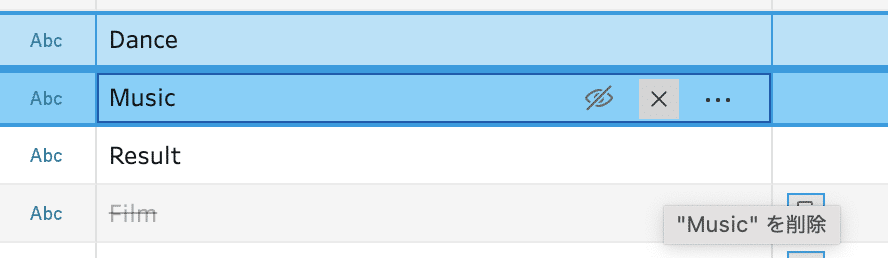
間違えて削除してしまったフィールドは、フィールドを選択し右クリックで「フィールドを含める」を利用することで元に戻すことが出来ます。

「フィールドのリスト」の表示で一番左に表示されている「タイプ」は、各フィールドのデータ型を表示しています。
ここをクリックして、文字列、数値、日付などのデータ型をデータ接続時に変更することが出来ます。
数字で示される4桁のID番号は、処理加工時は文字列として扱いたいケースが多いもの。整数型だと頭の 00 が消えて2桁の数字になっていることもしばしば。このようなケースでは、データ接続時にデータ型を文字列にしておくことで、後の作業で 00 の消滅などは解消されます。
(C) ヘッダ位置の調整
前述のデータインタプリタに近い作業で、データとして利用する行の位置を指定することが出来ます。
CSVなどのテキストファイルや、データインタプリタを行っていないExcelファイルでフィールド名やデータに利用する最初の行を削除、調整が出来ます。
(再掲、標準状態で作業した結果)

初期状態はヘッダー行 1、データ開始行 2 となっている

データに含まれていた「売上」などの表示が消えている

ヘッダー行 2、データ開始行 3 とした場合、フィールド名で「部門」が亡くなっているため、F1、F2、F3の表示に対し手作業でフィールド名の修正をする必要があります。
Excelファイルの場合は、データインタプリタの利用とどちらが有効かを判断して利用を考えましょう。
CSVなどのテキストファイルの場合は、Excelで利用出来るデータインタプリタが無いため、このヘッダ位置の調整がとても有用です。
データの状況によっては、完全なフィールド名の利用は難しいケースもありますが、データの内容を吟味し修正作業を減らす上手い利用を考えましょう。
(D) テキストファイルの区切り記号の指定
区切り記号付きテキストデータ(カンマ(,)やタブ、セミコロン(;)などの特定の記号でフィールドが分けられた形式のデータ)で、Prepで読み込む際に区切り記号を正確に認識する設定が出来ます。
この作業を上手く利用することで、データ接続後の文字列などの分割作業を簡素化することも可能です。
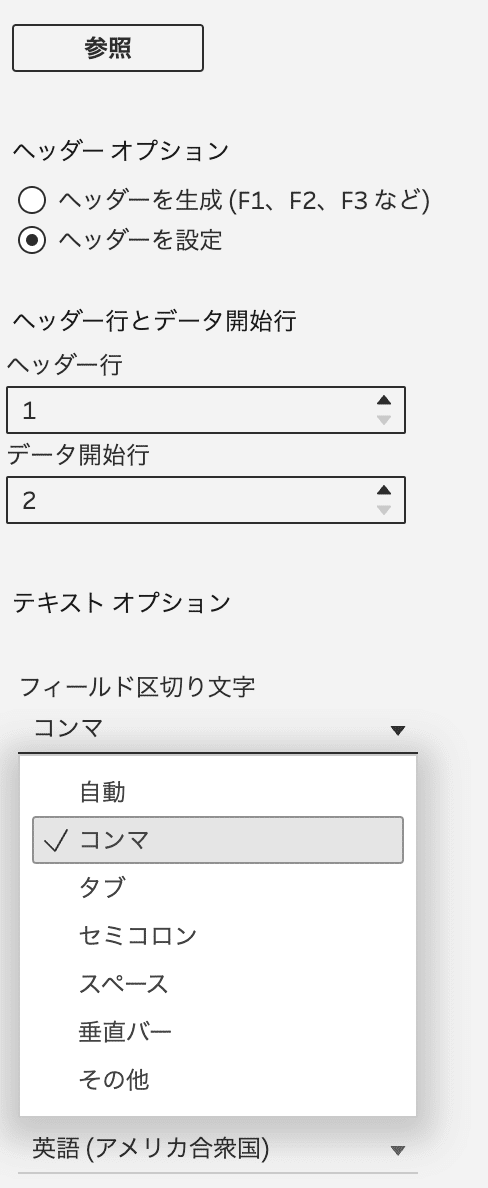

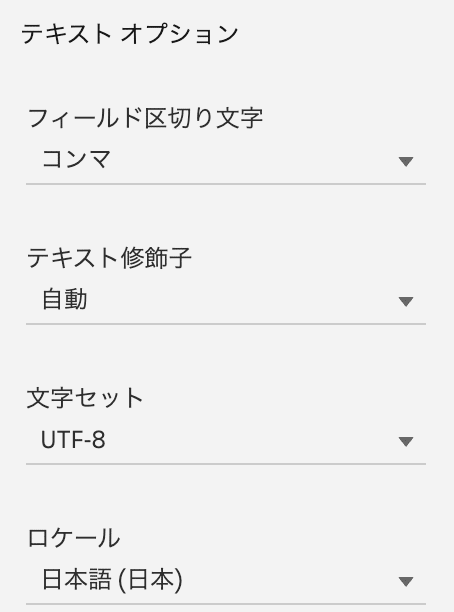
「テキスト修飾子」の設定も出来る
mitamuuさんの活用事例です。
Preppin' Data 2024W40でのInputデータは、カンマ(,)で365個の文字列が1つのフィールドに入っているデータでした。

このデータを、データ接続時に「フィールド区切り文字」を「コンマ」とし、「テキスト修飾子」を「なし」に設定しています。


(E) ロケールの設定
日付に関するデータを利用する際に、データ処理を行う国(地域)を指定出来ます。日付は、国際的に地域により年月日の並び順が異なります。
欧米などの地域で作成されたデータでは、そのままデータ接続をすると年月日の並び順が月日年のなど順で読み込まれる場合があります。順番が異なっていると、Prep上で修正作業が発生します。この問題を防いでくれる機能です。
*この機能は、完璧ではありません。状況を確認しながら利用してください。

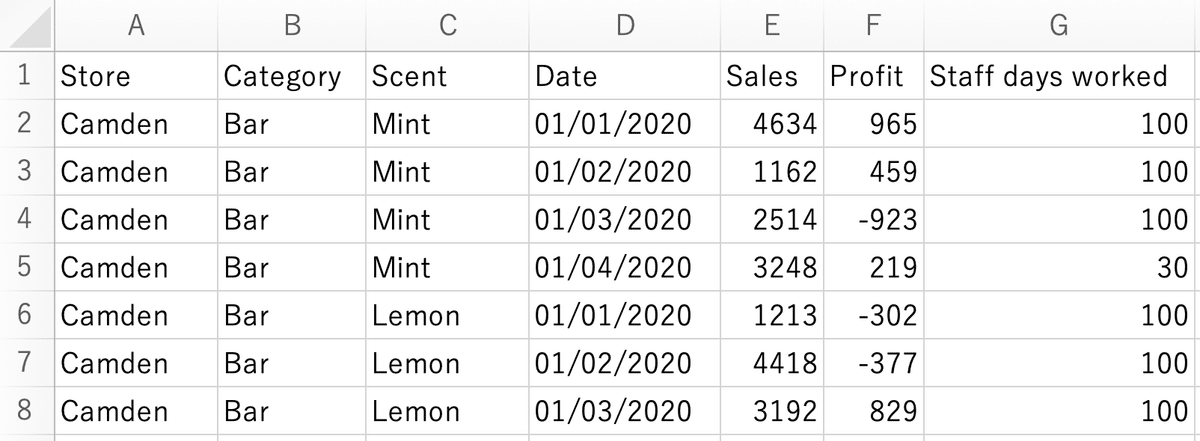
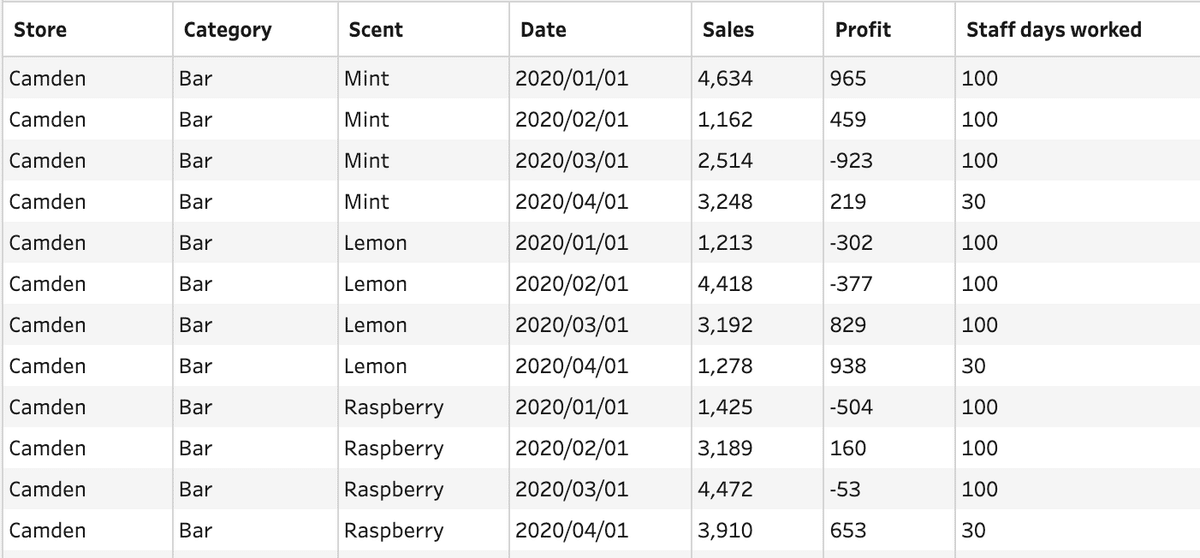
Preppin' Data 2020W16でのOutputデータを例に説明します。
このCSVデータをExcelで読み込むと、下記のように日月年の順に [Data] フィールドの値が表示されます。
このファイルを、Prepで「ロケール」を「英語(アメリカ合衆国)」の標準状態で読み込むと、[Data] フィールドの値は年日月の順に表示されます。

次に、Prepで「ロケール」を「日本語(日本)」で読み込むと、[Data] フィールドの値は年月日の順に表示されます。おそらく、この表示が正しいと思われます。
(F) 増分更新
大規模なデータセットや頻繁に更新されるデータを扱う場合、毎回フルデータを再読み込みすると処理時間やリソースが大きく消費されます。そこで役立つのが、「増分更新の有効化」機能です。
新しく追加されたレコードや更新されたレコードのみを読み込み、効率的にフローを実行できるようになります。

Server、クラウドなどでデータソースが自動的にデータ追加の更新がなされる場合などで、Prep操作時に毎回全てのデータ取り込みが発生せず、作業時間の節約が期待されます。
初めて実行するとき(または設定時点)にフルデータを読み込み、その後の実行では差分だけを更新する、という流れになります。
定期運用に入ると、毎回の実行が高速化・省リソース化されます。
「テーブル」タブ
(G) ワイルドカードユニオン
データ接続の時点で、複数のファイル、もしくはExcel内の複数ワークシートをユニオンで縦に繋げる作業が出来ます。
同一書式データの読み込みや、毎月更新されるデータの追加読み込みなどを自動的に処理出来るメリットがあります。
下記は、Preppin'Data 2020W16のExcelファイル内の2つのワークシートをワイルドカードでユニオンする事例です。
インプットペイン内のテーブルタブにある「ソース」、「複数テーブルを結合」を選択します。
インプットペインの下にある、「ワークシートフィルター」で「ワークシートフィルターを追加」をクリックし、「ワークシート名」の欄に一致させる名称と方法を決定してPCのエンターキーを押します。
「含まれるテーブル」に対象となるワークシートが表示されますので、問題なければペイン下の「適応」ボタンを押しユニオンを実行します。


テキストファイルのユニオンについても、Excelと同類の操作で実施可能です。
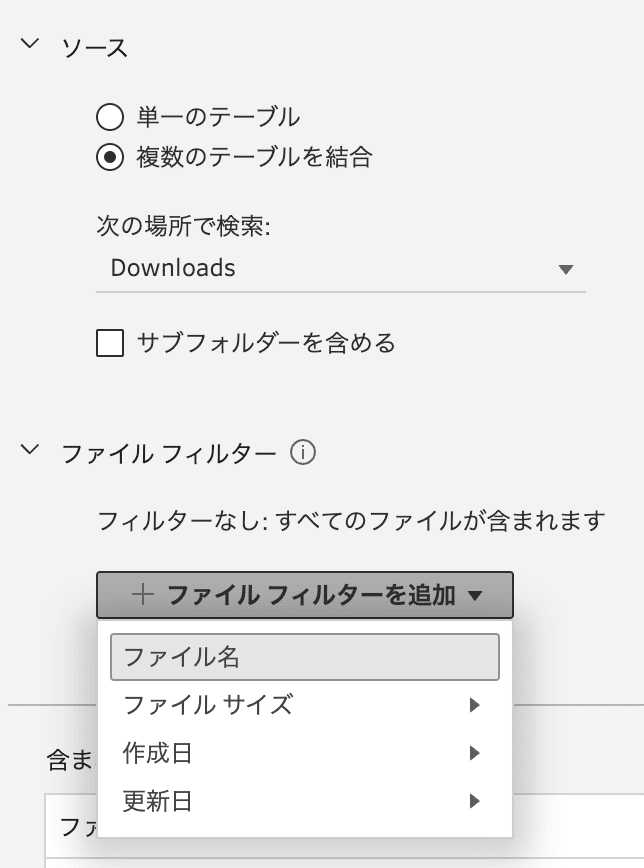
インプットペイン内のテーブルタブにある「ソース」、「複数テーブルを結合」を選択します。
インプットペインの下にある、「ファイルフィルター」で「ファイルフィルターを追加」をクリックして表示されるメニューから、「ファイル名」など抵抗する項目を選択し、Excelワークシート同様に必要な内容を記入して「適応」ボタンで実行します。
まとめ
Prepで一番最初に実施するデータの接続作業ですが、特にファイル読み込む時に利用出来る調整、ユニオン作業が作業効率を上げる有効な手段になります。
地味なポイントになりますが、みなさんの作業時に一度 試して頂いてその有効性を体感して頂ければと思います。