
Preppin Data Practice #08 (24年11月 2024: Week 40 - Vrroom

Tableau Prepユーザー会のNakajima2です。
Japan Preppin Data Fam 第8回目のPreppin Data勉強会、24年11月のYouTube動画公開は、24年10月にPreppin' Dataで出題された全5題(W 40 〜44)から2024W40 の課題にチャレンジです。
今回取り上げたWeek 40のチャレンジでは、
1)カンマ区切りで長い文字列データの取り込みとデータの分割方法
2)縦持ちから横持ちへの変更の方法
がポイントになっています。
Prepのメニューに含まれているデータ接続の方法に対するTipsや、2)に対するピボットの利用だけでなく、縦にデータを並べるための行を作るTipsが紹介されています。
既にMr. もりたが重要どころをXツイートでしていますが、参加者の思案による実務でも利用出来る対処方法があり、見どころ満載の会となりました。
ぜひ、配信動画と合わせてご覧ください。
Preppin’ Data勉強会の配信動画(YouTube)はこちらです
https://youtu.be/Oz6tQeaaSkI?si=XA0F9i0XUmM81eJz
1)課題の内容
今回取り上げたW40のPreppin Data 課題は、下記を参照ください。
https://preppindata.blogspot.com/2024/10/2024-week-40-vrroom.html
・出題の背景、対応項目
今回の課題はとして設定されている内容です。
Vrroomは中古車のオンラインプラットフォームで、個人やディーラーが車両を広告掲載できます。現在、このサイトを利用しているディーラーは5社です。Vrroomの経営チームは、プラットフォームを介して車両を販売するのに最も時間(日数)がかかっているディーラーを特定する必要があります。
入力データ(Input Data)
今週は以下の2つのCSVデータセットが用意されています
(1)広告データセット
(2)ユーザーデータセット
*サイトのユーザーは365人です。各車両の登録番号が異なります。
(2)は、下図のようなカンマで区切られていて、文字数の多い1セルのデータです。

出力 (Output Data)
以下の2つのデータフィールドが含まれます
(1)ディーラーID(Dealership ID)
(2)ディーラーの平均販売日数(Dealership Avg Days to Sell)
行数: 5行(ヘッダーを含めて6行)
対応のポイント(Requirementsのポイント)
要求項目から、処理として対応すべき概要は次の通りです(要約した内容です)。
データセットを接続する
ユーザーデータセットを個別のレコードに分解する(365行になるはずです)
ユーザーデータは以下の形式です:
最初の7文字がユーザーID
最後の1文字は、ユーザーが個人(‘P’)かディーラー(‘D’)かを表す
ユーザーIDの後に続く3文字はディーラーID(ディーラーの場合のみ)
広告データから売れていない車両を削除する
データセットを結合する
広告が最初に投稿された日付を特定する
広告が最初に投稿されたレコードのみを保持する
車両が最初に広告された日から販売された日までの日数を計算する
ディーラーごとに平均販売日数を算出する(最も近い整数に丸める)
データを出力する
2)参加者の解答例、Tipsなど
(1)データの分割
データソースとして利用するユーザーデータは、365名の情報がカンマ区切りでひとつのデータ([users]、1フィールド、1レコード)となっています。
通常の方法は、Sprit関数を利用した分割の操作となります。


ネイティブ機能で利用出来る分割は、1回の操作で150個までのデータを分割することが出来ます。
最初の分割操作で作成された [users - 分割済み 150] を更に分割操作を行い、365個のデータを分割します。
今回の作業では、3回の分割操作を繰り返し、365個のデータ(フィールド)を作成しています。作業は3回で手早く行えますが、作成されるフィールド数が365以上となり、視認性があまり良くないです状態です。

(2)データセットの接続時のTips
mitamuuさんのTIpsです。
前述の分割作業ですが、データ接続時に自動でやってもらうことが出来るようです。
データ接続時に、「設定」のメニューを操作し、「テキスト修飾子」で「なし」にチェックすると、接続作業だけでカンマ毎にデータが分割された状態で読み込んでもらえます。
これは、とても便利!
ExcelでCSVファイルを読み込む際も、フィールドの分割位置を指定する作業がありますが、Prepでもここのメニューで類似の設定が出来ます。


(3)横持ちデータを縦持ちデータに変換
横持ちデータを縦持ちに変更する作業は、365個のフィールドを、365個のレコード(行)にする変換する作業になります。
通常は、大変有効な手法として、ピボットを利用します。
他の手法として、「不等号を用いた結合の利用」、「新しい行とFINDNTHの利用」について説明がありました。
A : ピボット操作
Prepのピボットは、横から縦へ(列から行)と、縦から列へ(行から列)の両方が作業可能です。
今回は、列から行の処理を行い、横持ちから縦持ちへデータを変換します。通常は、フィールドを複数選択し、「ピボットされたフィールド」欄にドラッグ&ドロップしてピボットを行います。

mitamuuさんのTipsです。
ピボットのフィールド選択時に、「ワイルドカードユニオを使用してピボットする」をクリックすると、フィールド名に含まれる共通な文字を利用してピボットするフィールドを選択出来ます。
mitamuuさんは、共通文字として「F」を利用されていました。この説明では、上記 通常ピボット操作の例を用い、「users」の文字を使用した例を示します。



B: 不等号を用いた結合の利用
ピボット操作は、横持ちを縦持ちに変換する際に行を増やす(今回は365行に横縦変換をする)作業になります。
Mr. もりたは、2つのデータソースを最初に結合することで、ピボットを利用せず先に複数の行を作成するTipsを用いています。
データ接続時に作成されるユーザーデータセットの [Source Row Number] のフィールド(1行しかデータがないため「1」のみの1セルです)を残しておき、広告データセットの [record_id] と不等号を用いた結合を行なっています。
この操作により、 [record_id] の全データ(1,000行)に [users] のデータをテーブルとして横に並べる結果になります。
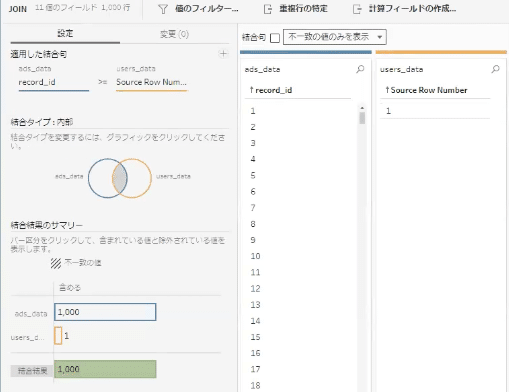
1,000行のレコードは、ユーザーデータが365名の情報(365行のレコード)に対しレコード数が違うことになりますが、今回の課題ではデータをフィルターと集計作業を行うため、途中過程としてレコード数の整合は考えなくて良い点を利用した方法になります。
この方法での更なるTipsは、[users] のコンマ区切りが入っているデータをどのようにして各行に必要なデータのみを取り出すか? への対処方法になります。
Mr. もりたは、次の正規表現を用いて、[users] のデータから [Dealership ID] としてデータを綺麗に取り出しています。
「先頭と最後はカンマじゃなくても取り出し大丈夫」とは、Mr. もりた 談です。
[Dealership ID]
REGEXP_EXTRACT([users], '([^,]*' + STR([user_id]) + '[^,]*)')
この処理後、集計処理を行い出力と同じ結果を得ています。
なお、この正規表現の関数式は、Mr. もりたもAIに問いかけて関数を作ったそうです。
C: 新しい行とFINDNTHの利用
ピボットを利用せず、先にユーザーデータ分の365行を作り、[users] の各行の必要データを取り出す方法です。
Nakajima2からの説明ですが、元のTipsは Rosario Gaunaさんのツイートと、第10回 Prepユーザー会イベントでのわっしーさん説明内容を参考にさせて頂いてます(内容は、ぞれぞれリンク先をご参照ください)。
[users] のデータに含まれているカンマの数をカウントし(今回事例では364個になります)、その数値で日付データを作成します。
今回は開始日([Start] で2023年1月1日)と、終了日([End] で2023年12月31日)を作成しました。

開始日と終了日を利用して、365行の新しい行を作成します。

[users] の各行の必要データを取り出す方法は、ROW_NUMBER(Indexとしての行の通し番号)と、FINDNTH関数を利用しています。
[users] データ内のカンマを半角スペースに変換し、半角スペースが文字列内で出てくる順番を位置として認識させます。
Row_Numberの番号と同じ順番(位置)にある文字列を、別のフィールド [Users] としてFINDNTH関数を利用して取り出しています。
[Row Number]
{ ORDERBY [Rows Ref]ASC : ROW_NUMBER()}
[Users]
TRIM(SPLIT(
TRIM(MID([users],
FINDNTH([users], " ", [Row Number] - 1)))
, " ", 1 ) )

3)その他の計算方法
A: ディーラーのみのデータ抽出
[users] から作成したフィールドで、最右に「D」があるデータのみを抽出します。mitamuuさんは、フィルターの編集でRIGHT関数を利用しています。

B: user_id の作成
[users] から作成したフィールドで、左から7文字を [user_id] のデータとします。mitamuuさんは、フィルターの編集でLEFT関数を利用しています。

C: Dealership ID の作成
[users] から作成したフィールドで、中間位置の3文字を [Dealership ID] のデータとします。mitamuuさんは、フィルターの編集でMID関数を利用しています。

D: 広告が最初に投稿されたレコードのみを保持する
広告データセットでの処理で、操作方法が複数ありました。
mitamuuさんは、公国投稿日をRANK関数で順番に並べ、RANK=1 となる広告が最初に投稿されたレコードのみをフィルターで取り出しています。

Mr. もりたは、FIXED関数を用いて最小の広告投稿日を求め、その日付が広告掲載日([publish_ts])と同じデータのみを抽出しています。

E: ディーラーごとに平均販売日数を算出する(最も近い整数に丸める)
平均日数は、集計操作時に集計関数をAVGを利用して対応している方が大半でした。集計した後の数値処理として、(最も近い整数に丸める)処理をCELLING関数を用いて処理をしています。
INT関数(整数にする)、FLOAT関数(指定した小数桁にする)、ROUND関数(指定した小数桁に丸める)など、数値処理で覚えておくと便利な関数です。
[Dealership Avg Days to Sell]
CEILING([Dealership Avg Days to Sell])
F: そして、1Step!
たっくんさん は、この課題での一連のフローを結合や集計を利用せず、ピボットだけで1Stepフローにしています。
Step中の処理数は32回になっています。結合や集計の処理をFIXED関数やPARTITION関数を利用したグループ単位の並び替え、フィルター操作を駆使しての作業は、処理の流れ、それぞれの関数の仕組みを理解した上でのロジック的思考での作業が必要となります。
作業の詳細は、アーカイブやPrepフローファイルに委ねます。
Prepの処理に慣れてきた方は、一度 1Stepでフローを作成し思考のトレーニングをされるとスキルアップが図れると思います。ご興味ある方は、トライしてみてください。


4)参加者が回答したPrep フローファイル
勉強会に参加したメンバーが作成したPrepフローのファイルを公開致します。
このブログ、動画アーカイブをご覧頂いたみなさまで、ご自分で手を動かしフロー作成をされた方の少しでもご参考になればと思っています。
下記のリンク先にフローファイルを保存しています。みなさまのお役に立てれば幸いです。
https://drive.google.com/drive/folders/1E6RIm6GcSJgm-qmunBXmC9all8_ZO2vC?usp=share_link
5)おわりに
今回で8回目の勉強会 公開配信(ビデオ解説)になります。
毎回感じることですが、他のメンバーから聞く発表で新たな発見があり、知識の習得、定着が深く図れていると感じています。
特に今回は、データの横持ちと縦持ちの変換に対し、参加者のこだわり作法や実務でも役立つ考え方が多く発表され、実務でも応用価値がある話や考え方が多く出ていたと思います.
11月からPreppin' Data勉強会に初心者コースを開催しています。12月までの限定開催です。
・Prep使ってみたい
・仕事で使っているけど ちょっととっつきにくい
・Preppn' Dataの初心者向け課題を始めました
という方々、一歩踏み出してスタートすると想像以上に力がつきますよ。
Tableau Prepが使い慣れた中級以上の方も、Tipsが 目から鱗いっぱいありますので、是非ご参加ください。
参加希望の方は、下記までメールご連絡をお願いします。
Tableau Prepユーザー会 : tableauprep.usergroup@gmail.com