
画像解析を高速化させるためのTipsわかりやすくまとめてみた(1)

こんにちは、こんばんは、はじめまして。株式会社アダコテックの伊部です。弊社では、製造業に向けた異常検知のAIソフトウェアを開発・提供しています。私はそこで、画像処理・機械学習のソフトウェアを開発するエンジニアをしています。
画像解析で検査を自動化する上で、画像認識の処理速度がミリセックオーダーで検査を実行するのが必須で、高速に画像処理・学習・解析をおこなうため、アダコテックでは長年にかけてそこのチューニングをしてきたので、そこらへんのエッセンスをお伝えしようと思います。
想定読者:画像処理を勉強されている方で処理時間にイライラ、高速化させたいと思っている人とか。
整数型での四捨五入について
画像フィルタ処理では、整数型の割り算がでてきます。例えば、単純平滑化(3x3)では、次のようなカーネルを用いて計算します。
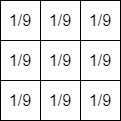
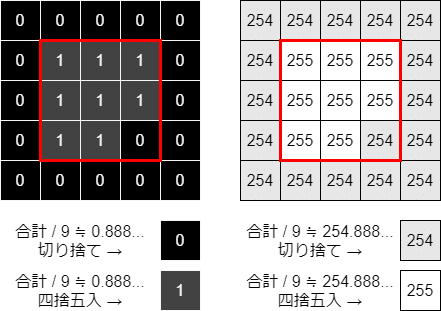
フィルタ適用後の値は、3x3ピクセルの輝度値を合計して9で割った値です。ここで、9で割った値の小数点以下を切り捨ててしまうと、下図のようにちょっと暗めになってしまいます。そのため、小数点以下を切り捨てるのではなく、四捨五入するようにしましょう。
正攻法でやる場合、round関数などを使うでしょう。
int x; // 割られる数
int y; // 割る数
int ans = (int)std::round((double)x / (double)y);しかし、画像フィルタのように何百回も計算する場合、double型にキャストして計算すると、時間がかかってしまいそうです。そこで、int型のみで、割り算の計算結果の四捨五入の値を計算してみます。
int型とint型の演算結果はint型になり、例えば以下のようになります。
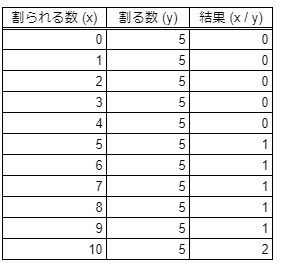
これは、小数点以下を切り捨てた値ですね。int型の割り算の結果は、小数点以下は切り捨てられます。また、double型をint型にキャストした場合も、小数点以下は切り捨てられます。
四捨五入するには、割った値に0.5を足してから切り捨てることで計算できます。いったんdouble型に変換するならば、
int x; // 割られる数
int y; // 割る数
int ans = (int)((double)x / (double)y + 0.5);となりますが、これをint型だけでやるなら、割る前に (int)(0.5 * y) すなわち y / 2 すなわち y >> 1 を足してあげればよいです。
int x; // 割られる数
int y; // 割る数
int ans = (x + (y >> 1)) / y;
ただし、以下のような場合は、この方法は使用できませんので、用法用量を守って正しくお使いください。
・ x + (y >> 1) がオーバーフローする可能性がある場合は使用できません。
・ x < 0 の場合は、round関数とは挙動が異なります。
ベンチマーク
こんなC++のコードで実行時間を計測してみました。cppファイルを分割しているのは、インライン展開の最適化を避けるためです。
//! @file: div_round.cpp
// double型版
int div_round_double(int x, int y)
{
return (int)((double)x / (double)y + 0.5);
}
// int型版
int div_round_int(int x, int y)
{
return (x + (y >> 1)) / y;
}//! @file: benchmark.cpp
#include <iostream>
#include <chrono>
// ベンチマーク
void benchmark(int (*func)(int, int), int n, const int* x, const int* y, int* ans)
{
auto start = std::chrono::system_clock::now();
for (int i = 0; i < n; ++i) {
ans[i] = func(x[i], y[i]);
}
auto end = std::chrono::system_clock::now();
auto elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << elapsed << std::endl;
}
//! @file: main.cpp
#include <random>
#include <algorithm>
int div_round_double(int x, int y);
int div_round_int(int x, int y);
void benchmark(int (*func)(int, int), int n, const int* x, const int* y, int* ans);
int main()
{
static const int N = 10000000;
std::random_device rd;
std::mt19937 mt(rd());
std::uniform_int_distribution<> rand256(1, 255);
std::vector<int> x(N);
std::vector<int> y(N);
std::vector<int> ans(N);
std::generate(x.begin(), x.end(), [&](){ return rand256(mt); });
std::generate(y.begin(), y.end(), [&](){ return rand256(mt); });
benchmark(div_round_double, N, x.data(), y.data(), ans.data());
benchmark(div_round_int, N, x.data(), y.data(), ans.data();
return 0;
}
実行環境:
・CPU: 8th Generation Core i7
・OS: Ubuntu (WSL2)
・Compiler1: gcc version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
・Compiler2: clang version 6.0.0-1ubuntu2
・Compile Options: -O[03] -mno-mmx -mno-sse -mno-sse2 -mno-sse3
※SIMDを使用しないオプションを追加しているのは、double型の演算でSIMD命令を使用する最適化をおこなうようになり、double型の演算のほうが速くなったりする場合もあるためです。(<del>じゃあこの記事意味ないじゃん…?</del>)
ベンチマーク結果(5試行平均):

1.1倍~1.5倍速くなりました。ちょっと微妙ですね。
次回は、これを更に高速化(SIMDで実装)してみたいと思います。
メンバー募集中です
アダコテックは上記のような画像処理技術を使って、大手メーカーの検査ラインを自動化するソフトウェアを開発している会社です。
機械学習や画像処理の内部ロジックに興味がある方、ご連絡下さい!
我々と一緒にモノづくりに革新を起こしましょう!