
いわゆる「スパコン」の中ってどんなだった?④ABCIでGPUを利用した事例

こんにちはー。入社6年目のはっしーです。
全4回に渡って紹介するスパコンの事例。
今回は第4回、最後ですね。
今回はGPUを利用する際に起こったあれこれをご紹介したいと思います。
事例紹介というより苦労話なんですけど😂
スパコンにまつわる一般知識
ABCIにまつわる一般知識
ABCIでSingularityを利用した事例
ABCIでGPUを利用した事例 👈ここ!
ちょっとした振り返り
前回、ABCIの導入経緯についてお伝えしました。
ABCI環境でOSS-LLMを利用したい、ということになっていました。
このOSS-LLMは、GPUで動作することになっているので、プログラムがGPUを使用できるようにしなければなりません。
(それまではWeb APIを通してGPTを使っていたので、GPUを気にする必要がなかった)
また、このプログラムはSingularityインスタンス内で実行されます。したがって、SingularityのインスタンスからホストマシンのGPUを使用するような調整も必要です。
ところで、GPUって改めて問われると、何者なのでしょうか。
GPUをSingularityで利用可能にする
GPUって何者?
以下はWikipediaによる説明です。
Graphics Processing Unit(グラフィックス プロセッシング ユニット、略してGPU)は、コンピュータゲームに代表されるリアルタイム画像処理に特化した演算装置あるいはプロセッサである。
…
さらにHPC分野では、CPUよりも並列演算性能にすぐれたGPUのハードウェアを、より一般的な計算に活用する「GPGPU」がさかんに行われるようになっており、そういった分野向けに映像出力端子を持たない専用製品や、深層学習ベースのAI向けに特化した演算器を搭載したハイエンド製品も現れている。
なるほど。
元々は画像処理に特化したプロセッサだったけど、作りの面で並列計算に恩恵があったので、より一般的な分野やAIの分野で用いられるようになった、ということが書いてありますね。
わかりました。
でも、実際にこれをプログラムから利用するにはどうすればいいのでしょうか?
当時の私のレベル感は以下のようなものです。
「GPU? 知ってるよ。ゲーミングPCのグラボに載ってるやつでしょ」
「聞いたことあるけど、実際に使ったことないな。ゲームやらんし」
「そもそもこのパソコンにGPUが入ってるのかどうかも分からん」
まるっきり初学者だったということですね。
これが大変な苦労を招いた。
SingularityでGPUを利用可能にする
これは実のところそう難しいことではありません。
前回述べたように、SingularityはGPUを利用しやすいように設計されています。
以下のような--nvオプションがshell, run, exec, instance startなどの主要なコマンドに用意されています。
singularity run --nv example.sifこれは逆に簡単すぎて「本当にこれでGPU使うようになってるの…?」と思うくらいでした。
しかし、GPUを簡単に使えると言っても、どれくらいのリソースを確保しなければいけないかは、プログラムを実際に動かして確認する必要があります。
何も考えずに使ってみたところ、以下のようなエラーに遭遇しました。
torch.cuda.OutOfMemoryError: CUDA out of memory.
Tried to allocate 166.00 MiB.
GPU 0 has a total capacity of 15.77 GiB of which 43.38 MiB is free.
Including non-PyTorch memory, this process has 15.73 GiB memory in use.
Of the allocated memory 14.34 GiB is allocated by PyTorch, and 490.77 MiB is reserved by PyTorch but unallocated.
If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation.
See documentation for Memory Management
(https://pytorch.org/docs/stable/notes/cuda.html#environment-vriables) GPUを扱った経験のあるエンジニアならこのエラーを見てすぐ「あーはいはい、GPUメモリが足らないのね」と思うかもしれません。
しかし、私は前述のように「これってGPU使えてんのかな…」というレベルからスタートしたので、一体何が起こっているのか理解するのに非常に時間が掛かりました。
難しいポイント: GPUメモリの計算資源の調整
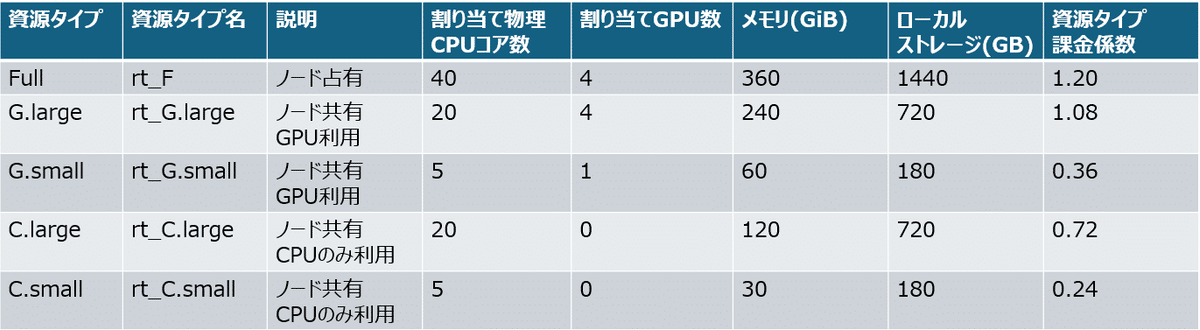
ABCIでは、GPUを含めた計算資源を資源タイプという概念でまとめています。
例えば、ABCI 2.0の計算ノードでは以下のようになっています。(3.0の情報はなんか見当たらない…)
(前掲のABCI 2.0ユーザガイドより作成)

(前掲のABCI 2.0ユーザガイドより作成)
これらの①資源タイプ、②その資源タイプの課金係数、③占有時間の掛け合わせで、使用料金が変わってくるという仕組みです。
課金係数の列に着目すると、多くの計算資源を取る資源タイプほどより大きな係数が設定されていることがお分かりになると思います。
ABCIでGPUを利用する時には、これらの資源タイプから適切なものを選ばなければなりません。これは予算に影響する話でもあるので、お客様との相談をした上で進めないといけないことでもあります。中々センシティブな話ということです。
ちなみに、前述のエラーで何が起こっていたかというと、これはプログラムを動作させた時、並行して複数のLLMのインスタンスを生成していたせいでGPUメモリが一瞬で枯渇する現象が起こっていました。1つのLLMのインスタンスは15GBくらいあります。私はこれを20個近く生成していました。
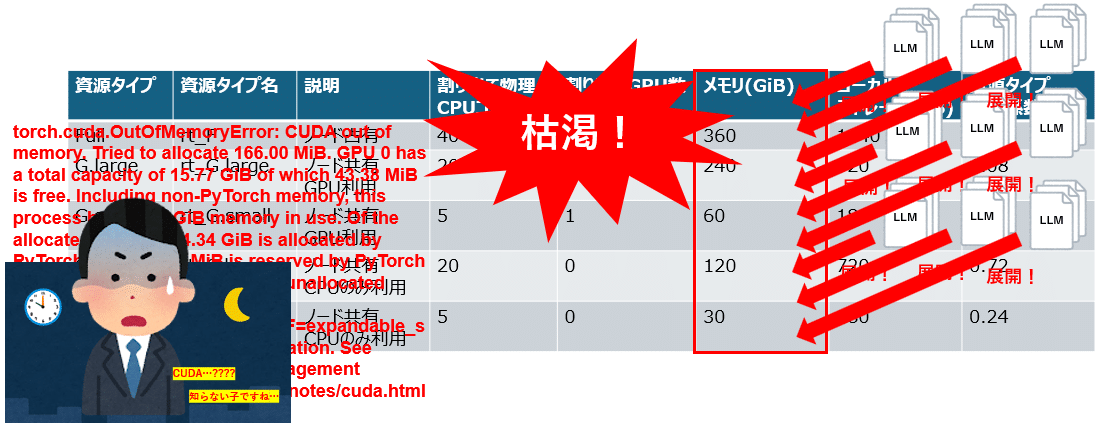
これのやってることのヤバさに気づくのにも時間が掛かりました。
結局は、LLMのインスタンスは1つだけ生成して使いまわすようにプログラムの修正をすることで解決しました。
実際のGPUの使用状況は、nvidia-smiを叩き、プログラムの進行とともにメモリ使用量がモリモリ増えていくところを確認しました。
(こんなコマンドがあること自体、私は知らなかった…)

下のProcessesの表でGPUを2つ利用していることが確認できる。
まとめ ~学んだこと~
全4回だったスパコン事例の紹介もこれで最後になりますので、まとめます。ここまでは以下のような内容をお伝えしました。
スパコンの定義・スペックの見方
ABCIの概要・使い方
Docker環境からSingularity環境への移行事例
GPUの使用事例
「当然知ってる」「当たり前すぎて呆れる」といった方もいれば、「全然見聞きしたこともない」という方もいらっしゃると思います。
私は普段の業務では、C#のクライアントアプリやTypeScript/JavaScriptのWebシステムに携わることが多いです。そのようなWeb寄りのシステムエンジニアが未知のHPC・科学計算の世界に飛び込んでみた、その一つの経験談だと受け取ってもらえたら嬉しいです。
私がこの経験から学んだことの1つは、次のようなものです。
「物理的な制約が抽象度の高い作業に干渉してくるとキツイ」
例えば、マシンのハードウェア構成の都合でコンテナエンジンやプログラムの起動方法を変えなければいけなかったり、メモリ節約のためにプログラム自体を修正しなければいけなかったりする。普段、こういった物理層で起こる問題は、プラットフォームやフレームワークと呼ばれる層が吸収してくれることが多いと思います。ところが、多くの計算資源を必要とする分野では、それらの障害がプログラムの製造などの抽象度の高い作業に影響を与えることがあります。
ただプラットフォームやフレームワーク、あるいはエディターが要求する通りにコーディングするのではなく、それらの裏側にどういった物理的な制約が存在しているのかを想像することが大事、ということですね。
逆に言えば、いつも物理的な層を隠蔽してくる実行環境的存在がいかにありがたいかということ。(いつもありがとう.NET……Node.js……)
こういったことがあるので、新しい物理環境に触れる時には、皆さんも事前の準備とそれ相応の覚悟もしっかりしておきましょう👍
それでは、またどこかの機会でお会いしましょう。
ありがとうございました🙇♂️