
書記が数学やるだけ#848 スケールフリーネットワークの性質

現実のネットワークに多く見られるスケールフリー性について扱う。
問題

説明
スケールフリーネットワークでは,次数分布がべき分布に従う。これはランダムネットワークと異なり,ネットワークの中心となるハブが存在することを示している。スケールフリーネットワークは,1965年にDerek J. de Solla Priceが論文引用のネットワークを計算することで提示された。

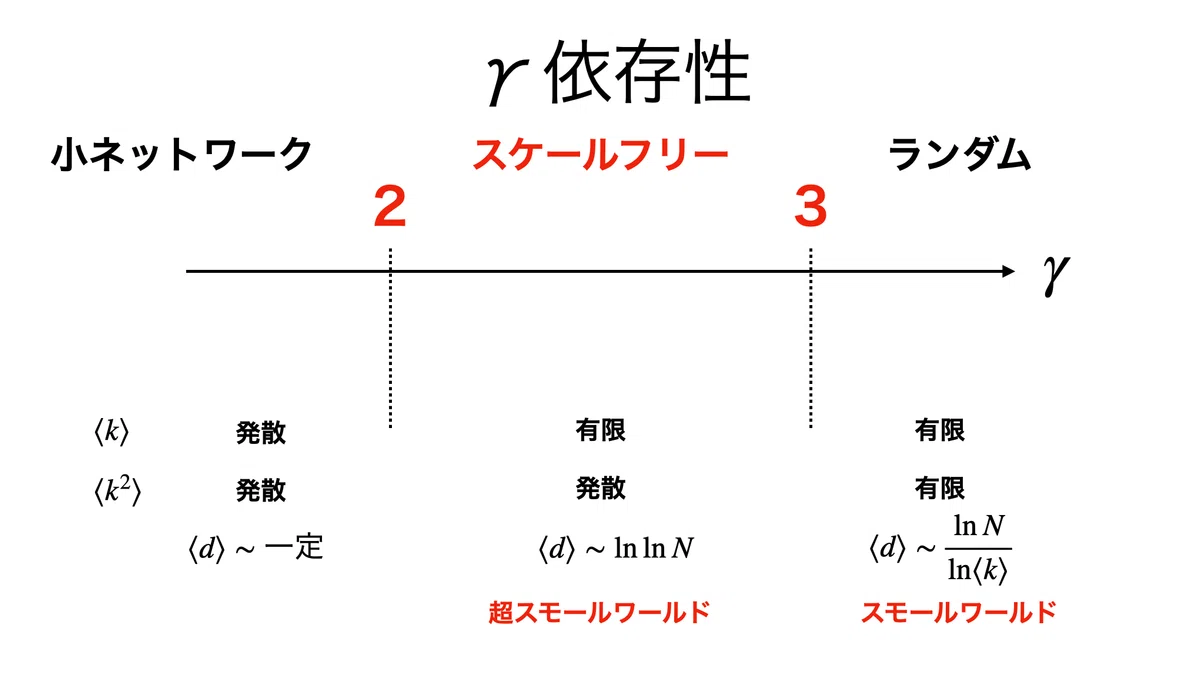
後に示すように,γ=2,3を境にネットワークの性質が変わり,スケールフリーネットワークはγが2~3に収まることが多い。
解答
kの期待値(1次モーメント)について,次元分布の積分を計算することでγ=2以下なら発散,2より大きいなら収束することがわかる。

同様に2次モーメントについて,γ=2以下なら発散,2より大きいなら収束する。多くの場合,パラメータとして使うのは1次・2次モーメントであることから,γの値が2,3を境に性質が変化すると言える。

kmaxをkminで表す式について,kmaxより大きい次数の頂点は高々1個であるという近似から計算する。

ではスケールフリーネットワークを実装する。今回はバラバーシ・アルベルト・モデルから生成する。
import matplotlib.pyplot as plt
import networkx as nx
import numpy as np
n = 100 #ノード数
m = 4 #起点の完全グラフの頂点数
print('NetworkX.barabasi_albert_graph()') #バラバーシ・アルベルト・モデル
G = nx.barabasi_albert_graph(n, m)
print(G)
nx.draw(G)
plt.show()
#NetworkX.barabasi_albert_graph()
#Graph with 100 nodes and 384 edges
いくつかパラメータを計算しておく(出力は一例)。
# 次数の合計
total_degree = sum(dict(G.degree()).values())
# 平均次数
average_degree = total_degree / G.number_of_nodes()
print("平均次数:", average_degree)
#次数の最大値: 38グラフ描画に必要な次数の最大値を求めておく。
# 各ノードの次数を取得
degree_dict = dict(G.degree())
# 次数の最大値を求める
max_degree = max(degree_dict.values())
print("次数の最大値:", max_degree)
#次数の最大値: 38次数分布は以下の通り。
degree_dist = [i/number_of_nodes for i in nx.degree_histogram(G)]
plt.rcParams['font.size'] = 20
plt.bar(range(max_degree+1), height = degree_dist)
plt.xlabel('$k$')
plt.ylabel('$p(k)$')
plt.ylim(0,0.3)
より見やすいように両対数軸に変換する。
# グラフを描画
plt.figure(figsize=(10, 6))
plt.rcParams['font.size'] = 20
plt.loglog(range(len(degree_dist)), degree_dist, marker='o', linestyle='None')
plt.xlabel('$k$')
plt.ylabel('$p(k)$')
plt.ylim(1e-4, 1) # Y軸の範囲を調整
plt.grid(True, which="both", ls="--")
plt.show()
ここで,ランダムネットワークであれば次数分布は平均λのポアソン分布で近似できるはずである。しかし実際にはk=20以上にも分布しており,ランダムネットワークには当てはまらないことが推測できる。
from scipy.stats import poisson
# ポアソン分布のパラメータλを計算
average_degree = sum(dict(G.degree()).values()) / number_of_nodes
# ポアソン分布を計算
k_values = np.arange(len(degree_dist))
poisson_dist = poisson.pmf(k_values, average_degree)
# グラフを描画
plt.figure(figsize=(10, 6))
plt.rcParams['font.size'] = 20
# 次数分布のプロット
plt.loglog(k_values, degree_dist, marker='o', linestyle='None', label='Degree Distribution')
# ポアソン分布のプロット
plt.loglog(k_values, poisson_dist, marker='x', linestyle='-', label='Poisson Distribution')
plt.xlabel('$k$')
plt.ylabel('$p(k)$')
plt.ylim(1e-4, 1) # Y軸の範囲を調整
plt.grid(True, which="both", ls="--")
plt.legend()
plt.show()
ここからスケールフリーネットワークに近似していく。準備として,区間幅が対数間隔のビンに変換していく。こうすることでγを決めるための近似直線の当てはまりが良くなる。
# 次数を取得
degrees = [d for n, d in G.degree()]
# ビンの境界を対数スケールで設定
bins = np.logspace(np.log10(min(degrees)), np.log10(max(degrees)), num=20)
# 各ビンに含まれるノードの数を計算
hist, bin_edges = np.histogram(degrees, bins=bins, density=True)
# ビンの中心を計算
bin_centers = (bin_edges[:-1] + bin_edges[1:]) / 2
# グラフを描画
plt.figure(figsize=(10, 6))
plt.rcParams['font.size'] = 20
# ドットプロットをプロット
plt.plot(bin_centers, hist, 'o')
plt.xscale('log')
plt.yscale('log')
plt.xlabel('$k$')
plt.ylabel('$p(k)$')
plt.ylim(1e-4, 1) # Y軸の範囲を調整
plt.grid(True, which="both", ls="--")
plt.show()
これにフィッテイングを行うことで傾きが求められ,これのマイナスでγを求めることができる。
# 次数を取得
degrees = [d for n, d in G.degree()]
# ビンの境界を対数スケールで設定
bins = np.logspace(np.log10(min(degrees)), np.log10(max(degrees)), num=20)
# 各ビンに含まれるノードの数を計算
hist, bin_edges = np.histogram(degrees, bins=bins, density=True)
# ビンの中心を計算
bin_centers = (bin_edges[:-1] + bin_edges[1:]) / 2
# 対数スケールで線形回帰を行うために、データの対数を取る
log_bin_centers = np.log10(bin_centers)
log_hist = np.log10(hist)
# 有効なデータのみを使う(ゼロでないデータ)
valid_indices = ~np.isinf(log_hist) # 無限大を持たないインデックス
log_bin_centers = log_bin_centers[valid_indices]
log_hist = log_hist[valid_indices]
# 近似直線をフィッティング(1次の多項式)
slope, intercept = np.polyfit(log_bin_centers, log_hist, 1)
# フィッティング結果の表示
print(f"近似直線の傾き: {slope:.4f}")
# グラフを描画
plt.figure(figsize=(10, 6))
plt.rcParams['font.size'] = 20
# ドットプロットをプロット
plt.plot(bin_centers, hist, 'o', label='Data')
# 有効なデータの範囲でのみプロット
plt.plot(bin_centers[valid_indices], 10**(slope * log_bin_centers + intercept), '--', label=f'Fit: slope = {slope:.4f}')
plt.xscale('log')
plt.yscale('log')
plt.xlabel('$k$')
plt.ylabel('$p(k)$')
plt.ylim(1e-4, 1) # Y軸の範囲を調整
plt.grid(True, which="both", ls="--")
plt.legend()
plt.show()
本記事のもくじはこちら:
学習に必要な本を買います。一覧→ https://www.amazon.co.jp/hz/wishlist/ls/1XI8RCAQIKR94?ref_=wl_share