
Windowsでの謎の圧縮エラーはUnicodeが悪さしてた!

Unicodeが悪さした、というより、仕様なんでしょうが、なかなか気が付かなくて苦労した話。
先週知人がファイルを一括圧縮してメールで送ってくれたのですが、目的のファイルが一つ少ないzipファイルとなっていました。すぐに「〇〇が無いよ〜」と連絡したのですが、不思議な回答が。
「何度圧縮してもダメ、ファイルを2フォルダに分けても、そのファイルだけ入らない、Lhaplusや他の圧縮ソフト使ってもダメ」ということでした。
ファイル名はどう見ても大丈夫そうだし、Googleドライブ上にある共有ファイルをまとめてダウンロードすれば、問題無く勝手にzip圧縮されてダウンロードできた。
普段はChromebookのみで作業をしており、Windowsは使っていないため、Windows環境がある会社のPCで試してみた。Windows標準のzip圧縮に送ったところ、どうやらファイル名がダメ、というエラー。
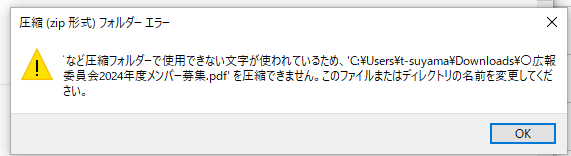
そうか、ファイル名か、ということで見たところ、やはりおかしそうなところは無い。ファイル名は「◯◯メンバー募集.pdf」のようなファイル名です。実は、新規で同じようなファイル名をつけると、何故かちゃんと圧縮できました。おかしそうな文字は無いのですが、少し調べてみました。
圧縮できたファイル名と、圧縮できなかったファイル名(見た目は全く一緒)をコピペして、プログラムで調べました。
圧縮できたファイル名と圧縮できなかったファイル名の文字数(str.length)は、圧縮できなかったほうが1多い事がわかりました。ならどんな文字になっているかということで、escape(str)してみたところ、方やu30D0、方やu30CF u3099、となっており、これは一文字のバと、二文字のハ゛になってました。表示上、見た目が全く一緒なら分かりようがありません。
少し調べてみると、こんな記載もあるので、これは本当に注意しなければならない話でした。
しかし、普通にファイル名としては分解されたカタカナと濁音が一文字として表示されるのに、圧縮するときだけエラーとか、間抜けな仕様です。恐らく、元々WindowsがShift-JISだったことが影響していると推察されます。ちなみに、Chromebookで圧縮しようとしても問題なく圧縮されます。ひょっとして、システムフォントをUTFに変更すると、問題は解決されるかもしれませんが、まだやってません(ちょっと影響が怖い)。
この記事が気に入ったらサポートをしてみませんか?