表形式のデータに対する前処理

①対象データの確認と整備
最終的にどのようなデータにするべきなのかを明確に決めておく!
【データ要件】
・csv形式
・ヘッダーの項目は1行のみ
・pandasで取り込んだ後に可視化を行うことが出来る。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
②データの読み込みと内容確認
②-1.データの読み込み
・Excelファイルの場合、pandasのread_excel関数を利用します。
・引数として、
ー io :読み込みたいデータのパス
ー sheet_name:単一のシート名またはシート名のリストを指定し、特定のシートを読み込む。
# ライブラリのインポート
import pandas as pd
# データの読み込み
df_data = pd.read_excel(io='pop202003.xls',sheet_name='市町村別人口')②-2.データの表示
・『読み込んだデータ.head()』:とすることでデータの先頭5行を表示。
In [1]: import pandas as pd
df_data = pd.read_excel(io='pop202003.xls',sheet_name='市町村別人口')
df_data.head()
Out[1]: 市町村別人口 ( 対 前月,対 前年 比較 ) Unnamed: 1 \
0 Population by Cities, Towns and Villages NaN
1 NaN NaN
2 NaN 43891
3 NaN 2020-03-01 00:00:00
4 NaN 2020-03-01 00:00:00
Unnamed: 2 Unnamed: 3 Unnamed: 4 \
0 NaN NaN NaN
1 対前月 Change over previous month NaN NaN
2 43862 増 減 数 増 減 率
3 2020-02-01 00:00:00 NaN NaN
4 2020-02-01 00:00:00 number rate
Unnamed: 5 Unnamed: 6 Unnamed: 7
0 NaN NaN NaN
1 対前年 Change over previous year NaN NaN
2 43525 増 減 数 増 減 率
3 2019-03-01 00:00:00 NaN NaN
4 2019-03-01 00:00:00 number rate ・『DataFrameが代入された変数.shape』:出力結果は、(行数, 列数)にタプル型。
In [2]: import pandas as pd
df_data = pd.read_excel(io='pop202003.xls',sheet_name='市町村別人口')
print(df_data.shape)
Out[2]: (67, 8)・列だけ抽出するとき:.shape[1]
・行だけ抽出するとき:.shape[0]
②-3.変数データ型の確認
変数のデータ型に応じて、適用できる関数や行うことのできる処理が異なる為、データ型を把握することは非常に重要。
【代表的なデータ型】
ー数値
・int型:整数
・float型:浮動小数点数
・bool型:真偽値(1 or 0であるが、PythonではTrue or Falseとも表現される)
ー文字列
・str型:文字列(但し、pandasを利用した場合、このデータ型はobjectと表示されます)
・DataFrameが代入された変数.info()
→DataFrameの各カラムのデータ型を確認するには、info関数を利用。
In[1]: import pandas as pd
df_data = pd.read_excel(io='pop202003.xls',sheet_name='市町村別人口')
print(df_data.info())
Out[1]: <class 'pandas.core.frame.DataFrame'>
RangeIndex: 67 entries, 0 to 66
Data columns (total 8 columns):
市町村別人口 ( 対 前月,対 前年 比較 ) 53 non-null object
Unnamed: 1 52 non-null object
Unnamed: 2 53 non-null object
Unnamed: 3 51 non-null object
Unnamed: 4 51 non-null object
Unnamed: 5 53 non-null object
Unnamed: 6 51 non-null object
Unnamed: 7 51 non-null object
dtypes: object(8)
memory usage: 4.3+ KB
Nonedtypes: object(8)とあるため、全てのデータのデータ型が現状はobjectと判断されています。
今後前処理を行なっていき、数値としてのデータを持つカラムのデータ型はobjectから数値型への変更を行う。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
③表形式のデータに対しての前処理
③-1.ヘッダーの変更
【前処理前のヘッダー】

・pandasでデータ分析を行う際にはヘッダーの要素は1行で判定するため、上記の複数の要素を1つにまとめる必要がある。
・データのヘッダーは.columnsで得ることができます。
# ヘッダーの変更
df_data.columns = ['市町村名', '2020-03-01_人口', '2020-02-01_人口', '2020-02-01_増減数','2020-02-01-増減率', '2019-02-01_人口', '2019-02-01_増減数', '2019-02-01_増減率']③-2.不要な表の削除1
・行削除を行う場合、『.drop( )』を用い、引数として削除したい行のインデックスをリスト形式で指定する。
df_data = df_data.drop([0,1,2,3,4])
df_data.head()・次のタスクでも引き継ぐためのデータをCSV形式で保存。
『to_csv( )』
・引数①『path_or_buf 』:保存したいデータ。
・引数②『index』:インデックスを加味するか?(True or False)
df_data.to_csv(path_or_buf='pop202003_version1.csv',index=False)③-3.欠損値の削除
『.isnull( )』
→欠損であるか否かの真理値を表ごとに返してくれる。
・欠損がある:True
・欠損がない:False
In [2]: df_data['2020-03-01_人口'].isnull()
Out[2]: 0 False
1 True
2 False
3 True
4 False
...
57 True
58 False
59 True
60 False
61 False
Name: 2020-03-01_人口, Length: 62, dtype: boolこれを使って、
欠損値が含むデータを抽出する場合。
In [3]: df_data[df_data['2020-03-01_人口'].isnull()]
Out[3]: 市町村名 2020-03-01_人口 2020-02-01_人口 2020-02-01_増減数 \
1 (Cities) NaN NaN NaN
3 NaN NaN NaN NaN
15 (Towns & Villages) NaN NaN NaN
・・・
57 NaN NaN NaN NaN
59 NaN NaN NaN NaN
2020-02-01-増減率 2019-02-01_人口 2019-02-01_増減数 2019-02-01_増減率
1 NaN NaN NaN NaN
3 NaN NaN NaN NaN
15 NaN NaN NaN NaN
・・・
57 NaN NaN NaN NaN
59 NaN NaN NaN NaN 欠損値を含まないデータのみを抽出。
In [4]: df_data[~df_data['2020-03-01_人口'].isnull()]
Out[4]: 市町村名 2020-03-01_人口 2020-02-01_人口 2020-02-01_増減数 \
0 県 計 Okinawa-ken 1457451.0 1457163.0 288.0
2 市 部 計 All shi 1127260.0 1126982.0 278.0
・・・
60 竹 富 町 Taketomi-cho 4108.0 4093.0 15.0
61 与那国町 Yonaguni-cho 2078.0 2079.0 -1.0
2020-02-01-増減率 2019-02-01_人口 2019-02-01_増減数 2019-02-01_増減率
0 0.019764 1451392.0 6059.0 0.417461
2 0.024668 1122351.0 4909.0 0.437385
4 -0.012893 318482.0 -531.0 -0.166728
・・・
60 0.366479 4075.0 33.0 0.809816 ※裏を取るときは条件に対して、『~』否定演算子を用います。
また、現状でのデータを次のタスクでも引き継ぐため、データをcsv形式で保存しておきましょう。
df_data = df_data[~df_data['2020-03-01_人口'].isnull()]
df_data.to_csv(path_or_buf='pop202003_version2.csv',index=False)③-4.半角空白の削除
『.replace( )』
・第1引数:置換したい元の文字列
・第2引数:置換した後の文字列
In [2]: test_string = '県 計 Okinawa-ken'
def remove_hankaku(x):
return str(x).replace(' ', '')
print(remove_hankaku(test_string))
Out [2]:県計Okinawa-ken 上記のように引数に空白置換した文字列を指定することで、空白を削除してくれます。
またpandasの各々のレコードに定義した関数の処理を行うためには、.map()を用います。
mapを用いることで各々のレコードに対して、個別に処理を行うことなく前処理を行うことが可能となります。
In [3]: df_data['市町村名'].map(remove_hankaku)
Out [3]:0 県計Okinawa-ken
2 市部計Allshi
・・・
60 竹富町Taketomi-cho
61 与那国町Yonaguni-cho
Name: 市町村名, dtype: object③-5.日本語と英字の分割
『.isupper( )』
→文字が大文字かどうか判定できる。(True or False)
In [1]: import pandas as pd
df_data = pd.read_csv('pop202003_version3.csv')
df_data['市町村名']
Out [1]:0 県計Okinawa-ken
1 市部計Allshi
...
47 竹富町Taketomi-cho
48 与那国町Yonaguni-cho
Name: 市町村名, dtype: object In [2]: test_string = '竹富町Taketomi-cho'
for index,string in enumerate(test_string):
print(string.isupper())
Out [2]: False
False
False
True
・・・
False
False
False for文を用いて文字列の一文字目から最後までの文字1つ1つに対して、『.isupper( )』を用いる。
『enumerate』
→要素のインデックスと要素を同時に取り出すことが可能。
境界の判断が出来たので、2分割すればうまく分けることが可能。
(アルファベットの大文字が境目となっている。)
# ライブラリのインポート
import pandas as pd
# データの読み込み
df_data = pd.read_csv('pop202003_version3.csv')
#関数設定
def get_ja_name(x):
ja_name = ''
for num,i in enumerate(x):
if(i.____()):
ja_name = x[____]
break;
return ja_name
def get_en_name(x):
en_name = ''
for num,i in enumerate(x):
if(i.____()):
en_name = x[____]
break;
return en_name
# 日本語の取得
ja_name_list = df_data[____].map(____)
# 英字の取得
en_name_list = df_data[____].map(____)
# pandasに代入
df_data['市町村名'] = ____
df_data['市町村名_読み'] = ____
# 現状のデータをcsv形式にて保存
df_data.to_csv(path_or_buf='pop202003_version4.csv',index=False)【関数設定の解説】
#関数設定
def get_ja_name(x):
#ja_nameの箱を作成。
ja_name = ''
#xのnum(インデックス)とi(要素)を抜き出す。
for num,i in enumerate(x):
#i(要素)が大文字(=True)であれば、
if(i.isupper()):
#xのインデックス0~numまでをja_nameとする。
ja_name = x[0:num]
#if文終了(Trueが来た)
break;
#「get_ja_name(x)」という関数にja_nameという値を返す。
return ja_name(補足)
リスト[0:num]のとき、0は含まない。
また、[num:]のとき、numは含まない。
③-6.新規columnの作成
カテゴリ―分類して、新規columnを作成する。
# ライブラリのインポート
import pandas as pd
# データの読み込み
df_data = pd.read_csv('pop202003_version4.csv')
#関数設定
def chk_city_category(x):
category = ''
if('市' in x):
category = '市'
elif('町' in x):
category = '町'
elif('村' in x):
category = '村'
elif('郡' in x):
category = '郡'
return category
# 新規カテゴリ列の作成
df_data['市町村カテゴリ'] = df_data["市町村名"].map(chk_city_category)
# 不要な行の削除
df_data = df_data.drop([0,1,13])
# 現状のデータをcsv形式にて保存
df_data.to_csv(path_or_buf='pop202003_version5.csv',index=False)下の仕組みとif文を利用して、関数を作成。
In [2]: test_string = '那覇市'
# 市が含まれているか判断
print('市' in test_string)
# 市が含まれているか判断
print('県' in test_string)
Out [2]: True
False 関数を作るとき以下のような簡単な場合でシミュレーションを行って、正しく機能しているのを確認し、使用する。
In [3]: test_string = '那覇市'
# 分岐処理関数設定
def chk_city_category(x):
category = ''
if('市' in x):
category = '市'
elif('町' in x):
category = '町'
elif('村' in x):
category = '村'
elif('郡' in x):
category = '郡'
return category
# 市町村カテゴリ判断
print(chk_city_category(test_string))
Out [3]: 市 drop関数
〇列の削除
・列名で削除 →drop(”列名”, axis=0)、drop([”列名1”,”列名2”], axis=1)
・列番号で削除→drop([num], axis=1)、drop([num1,num2],axis=1)
〇行の削除
・列名で削除 →drop(”行名”, axis=0)、drop([”行名1”,”行名2”], axis=0)
・列番号で削除→drop([num], axis=0)、drop([num1,num2],axis=0)
※デフォルトがaxis=0なので、なくてもOK。
③-7.データ型の変更と列の並び替え
〇データ型の変更
astype("変更したいカラム名":変更後のデータ型)
〇カラム一覧を取得する
df.columns
〇カラムの変更
df = df[[ ]]の中身を入れ替えればOK!
③-8.前処理後のデータを使った可視化
# ライブラリのインポート
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
# グラフ作画のスタイル変更
plt.style.use('ggplot')
# 前処理後のデータ読み込み
df_data = pd.read_csv('pop202003_version6.csv')①ライブラリをインポート
②グラフのスタイル変更(グラフが見やすくなるおまじないと認識でOK)
③データ読み込み
〇データ件数をプロット!
sns.countplot(y=df_data['市町村カテゴリ'])
plt.show()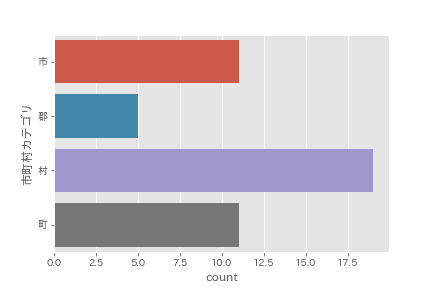
件数の可視化を行うことで、どの数が多く、少ないのかが簡単にわかる。
〇データ分布のプロット
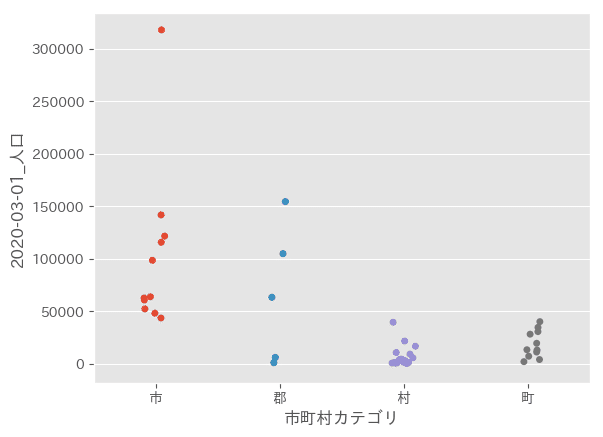
sns.stripplot(x="市町村カテゴリ", y="2020-03-01_人口", data=df_data)
plt.show()