スクレイピング


スクレイピングの具体例としては<p>タグの中身を抽出し、SIGNATEサンプルページの文字列を抽出をします。
【ウェブスクレイピングのライブラリ】
①reqests
→ウェブページを取得する際に使う。
②BeautifulSoup
→取得したウェブページを解析し、タグの検索、データの形成をする。
【スクレイピングの手順】
①.get( )を用い、取得したいウェブページのURLを指定。
# ライブラリのインポート
import requests
url = 'https://www.keishicho.metro.tokyo.jp/smph/menkyo/torishimari/tetsuzuki/hansoku.html'
r = requests.get(url)②BeautifulSoupを用いて、データの整形。
BeautifulSoup(第1引数,第2引数)
・第1引数:整形したいデータ
・第2引数:データ整形の仕方
※HTMLのデータ整形を行いたい場合、'html.parser'と指定。
In [1]: # ライブラリのインポート
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.content, 'html.parser')
soup
Out[1]: <!DOCTYPE HTML>
<html lang="ja">
<head>
<meta charset="utf-8"/>
・・・
</div><!-- divend contents -->
</div><!-- divend wrap -->
</body>
</html>〇取得したHTML構造の確認
先程、データを整形した[『soup』うちにはHTML構造が入っており、タグを指定することで、指定したタグを取得することが可能。
【指定したタグの取り出し方法】
※titleタグを取り出す場合
In [2]: soup.title
Out[2]: <title>反則行為の種別及び反則金一覧表 警視庁</title>さらに!
【指定したタグの中の文字列の取り出し方】
In [3]: soup.title.text
Out[3]: 反則行為の種別及び反則金一覧表 警視庁※『.text』をつけることで取得可能。
〇タグ情報検索【1件・タグ全検索】
①データを読み込み、BeautifulSoupにデータ整形。
# ライブラリのインポート
from bs4 import BeautifulSoup
f = open('scraping.text')
html = f.read()
f.close()
# データの整形
soup = BeautifulSoup(html, 'html.parser')②タグの検索

<soup.find()を用いる場合>
In [1]: soup.find('th')
Out[1]: <th class="center" colspan="2" rowspan="2" scope="col">反則行為の種類<br/>(略号)</th><soup.find_all()を用いる場合>
In [2]: soup.find_all('th')
Out[2]: [<th class="center" colspan="2" rowspan="2" scope="col">反則行為の種類<br/>(略号)</th>,
<th class="center" colspan="5" scope="col">車両等の種類及び反則金額<br/>(単位 千円)</th>,
<th class="center" scope="col">大型車</th>,
<th class="center" scope="col">普通車</th>,
<th class="center" scope="col">二輪車</th>,
<th class="center" scope="col">小型特殊車</th>,
<th class="center" scope="col">原付車</th>]※thタグ=table header:表のヘッダー
〇指定タグのデータ数の数え方
print(len(soup.find_all('td'))) ※soup.find_all('td')は、リストで帰ってくる。
※リストの要素の数を調べるとき、len関数を用いる。
〇タグ情報検索【属性・id・class検索】

soup.find_all("a")だとすべてのデータを抽出することになってしまった。特定のタグを探すには指定する必要がある。
その時に「タグ情報検索」が必要になる。
# 属性検索
print(soup.find_all('a',href="https://signate.jp/"))
# id検索
print(soup.find_all('a',id="link1"))
# class検索
print(soup.find_all('a',class_="test2"))〇タグ情報検索【正規表現】
正規表現を使用したタグ情報検索は、『re』ライブラリを使用。
・単一の検索 : soup.find(re.compile(正規表現))
・複数の検索 : soup.find_all(re.compile(正規表現))
※正規表現を使用することでより幅広く、タグ情報の検索結果を出力することが可能となる。
①まず、データを読み込み、BeautifulSoup4にデータ整形
# ライブラリのインポート
from bs4 import BeautifulSoup
f = open('scraping.text')
html = f.read()
f.close()
# データの整形
soup = BeautifulSoup(html, 'html.parser')②正規表現を使って、タグにtがついている情報を検索してみる。
In [1]: import re
soup.find_all(re.compile("^t"))
Out[1]: [<title>反則行為の種別及び反則金一覧表 警視庁</title>, <table class="table01">
<tr>
<th class="center" colspan="2" rowspan="2" scope="col">反則行為の種類<br/>(略号)</th>
<th class="center" colspan="5" scope="col">車両等の種類及び反則金額<br/>(単位 千円)</th>
・・・
<td class="left"><strong class="text-color-red"><span class="text-color-red">6</span></strong></td>
<td class="left">6</td>
<td class="left">5</td>
<td class="left">*</td> <td class="left">3</td>, <td class="left">3</td>, <td class="left">3</td>]※titleタグ、trタグ、tdタグなど情報を一括にリスト形式で取得できていることが確認できます。
※『^t』はヘッドがtのタグを表す。
〇ヘッダーデータのスクレイピング
抽出したいヘッダーの情報は以下の画像の赤枠で囲われている範囲となります。
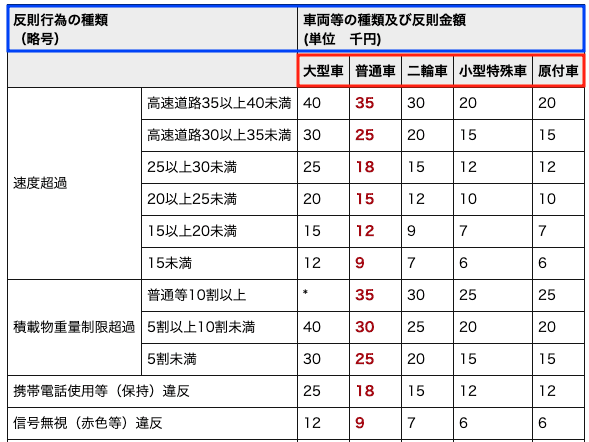
①BeautifulSoupにデータ整形をさせた状態にする。
②タグ検索
→まず画像の位置からヘッダー情報はtableタグの中に存在することが予想できるため、まずfind()を使ってtableタグを検索しましょう。
In [1]: import re
soup.find('table')
Out[1]: <table class="table01">
<tr>
<th class="center" colspan="2" rowspan="2" scope="col">反則行為の種類<br/>(略号)</th>
<th class="center" colspan="5" scope="col">車両等の種類及び反則金額<br/>(単位 千円)</th>
</tr>
<tr>
<th class="center" scope="col">大型車</th>
<th class="center" scope="col">普通車</th>
<th class="center" scope="col">二輪車</th>
<th class="center" scope="col">小型特殊車</th>
<th class="center" scope="col">原付車</th>
</tr>
<tr>
<td class="left" rowspan="6">速度超過</td>
<td class="left">20</td>
・・・③さらに細分化してタグ検索
→データが多すぎるので細分化のために、さらにfind_all()を使っ てtrタグを検索しましょう。
→タグ情報の検索は末尾に重ねて検索することも可能となる
In [2]: soup.find('table').find_all('tr')
Out[2]: [<tr>
<th class="center" colspan="2" rowspan="2" scope="col">反則行為の種類<br/>(略号)</th>
<th class="center" colspan="5" scope="col">車両等の種類及び反則金額<br/>(単位 千円)</th>
</tr>, <tr>
<th class="center" scope="col">大型車</th>
<th class="center" scope="col">普通車</th>
<th class="center" scope="col">二輪車</th>
<th class="center" scope="col">小型特殊車</th>
<th class="center" scope="col">原付車</th>
</tr>, <tr>
<td class="left" rowspan="6">速度超過</td>
<td class="left">高速道路35以上40未満</td>
<td class="left">40</td>
・・・]➃さらに必要な情報のみを取り出す。
※ヘッダーの情報のみ(「tr」タグのみ)
In [3]: soup.find('table').find_all('tr')[1]
Out[3]: <tr>
<th class="center" scope="col">大型車</th>
<th class="center" scope="col">普通車</th>
<th class="center" scope="col">二輪車</th>
<th class="center" scope="col">小型特殊車</th>
<th class="center" scope="col">原付車</th>
</tr>⑤さらに必要なタグの情報を抜き出す。
※今回は「th」タグをすべて抜き出す。
In [4]: soup.find('table').find_all('tr')[1].find_all('th')
Out[4]:[<th class="center" scope="col">大型車</th>,
<th class="center" scope="col">普通車</th>,
<th class="center" scope="col">二輪車</th>,
<th class="center" scope="col">小型特殊車</th>,
<th class="center" scope="col">原付車</th>]⑥for分を用いて各々の要素から.textを使って文字列を取得。
In [5]: # 情報格納の受け皿を用意
head_cols =[]
# 要素から`.text`を用いて文字列を取得し、受け皿に格納
for tag in (soup.find('table').find_all('tr')[1].find_all('th')):
head_cols.append(tag.text)
# 受け皿を表示
print(head_cols)
Out[5]:['大型車', '普通車', '二輪車', '小型特殊車', '原付車']①データを持つ場所をHTMLから確認。
②タグ情報検索を利用してデータを抽出。
この流れが、スクレイピングの定番!
〇表データのスクレイピング
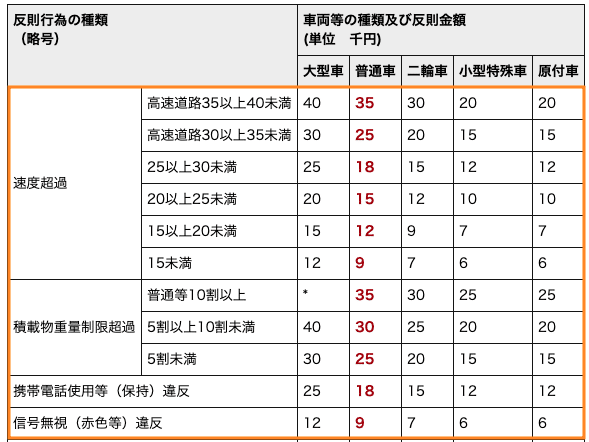
①tableタグの中のtrタグの中を3行目以降を抽出。
In [1]: soup.find('table').find_all('tr')[2:]
Out[1]: [<tr>
<td class="left" rowspan="6">速度超過</td>
<td class="left">高速道路35以上40未満</td>
<td class="left">40</td>
<td class="left"><strong class="text-color-red"><span class="text-color-red">35</span></strong></td>
<td class="left">30</td>
<td class="left">20</td>
<td class="left">20</td>
</tr>, <tr>
<td class="left">高速道路30以上35未満</td>
<td class="left">30</td>
<td class="left"><strong class="text-color-red"><span class="text-color-red">25</span></strong></td>
<td class="left">20</td>
<td class="left">15</td>
<td class="left">15</td>
</tr>, <tr>
・・・※インデックスの2~を抽出。
②
速度超過のように縦に結合されている表のHTMLタグではrowspan="6"という属性を指定。
(6行分を結合して、中身はすべて超過速度にするというプログラム)
下のようにこのまま要素を抜き出すとずれが生じてしまう。
0 1 2 3 4 5 6
0 速度超過 高速道路35以上40未満 40 35 30 20 20
1 高速道路30以上35未満 30 25 20 15 15 None
2 25以上30未満 25 18 15 12 12 None
3 20以上25未満 20 15 12 10 10 None
4 15以上20未満 15 12 9 7 7 None ※超過速度が1行1列目に入ってデータがずれている。
これを修正するために、逆順に抽出していく!
リストの末尾に [::-1] とすれば、逆順に抽出が可能!
In [2]: # ライブラリのインポート
import pandas as pd
# 全データを保持する用の受け皿を用意
list1 = []
for record in (soup.find('table').find_all('tr')[2:]):
# 各レコードごとのデータを保持する用の受け皿を用意
list2 = []
for yoso in (record.find_all('td')[::-1]):
# 各セルの文字列を格納
list2.append(yoso.text)
# 各レコードごとのリストを格納
list1.append(list2)
# DataFrame形式に変更
df_data = pd.DataFrame(list1)
print(df_data)
Out[2]: 0 1 2 3 4 5 6
0 20 20 30 35 40 高速道路35以上40未満 速度超過
1 15 15 20 25 30 高速道路30以上35未満 None
2 12 12 15 18 25 25以上30未満 None
3 10 10 12 15 20 20以上25未満 None
4 7 7 9 12 15 15以上20未満 None
5 6 6 7 9 12 15未満 None〇1つ目のif文 → オレンジに囲まれたtrタグをリスト形式で抽出
〇2つ目のif文 → 各trタグの中のtdタグの要素を抽出。(逆順)
〇最後にpandasでリスト形式からDataFrameに形式変換。
〇スクレイピングしたデータの整形
①データ読み込み
In [1]: import pandas as pd
df_data = pd.read_csv('df_body.csv')
df_data.head()
Out[1]: 0 1 2 3 4 5 6
0 20 20 30 35 40 高速道路35以上40未満 速度超過
1 15 15 20 25 30 高速道路30以上35未満 NaN
2 12 12 15 18 25 25以上30未満 NaN
3 10 10 12 15 20 20以上25未満 NaN
4 7 7 9 12 15 15以上20未満 NaN※columnが逆になっているので元に戻す。[ : : -1]
In [2]: df_data = df_data[df_data.columns[::-1]]
df_data.head()
Out[2]: 6 5 4 3 2 1 0
0 速度超過 高速道路35以上40未満 40 35 30 20 20
1 NaN 高速道路30以上35未満 30 25 20 15 15
2 NaN 25以上30未満 25 18 15 12 12
3 NaN 20以上25未満 20 15 12 10 10
4 NaN 15以上20未満 15 12 9 7 7※column”6”がNaNとなっているので、
・0~5:速度超過
・5~8:積載物重量制限超過
の文字列を代入する。
In [3]: df_data.loc[(df_data.index>=0) & (df_data.index<=5),'6'] = '速度超過'
df_data.loc[(df_data.index>=6) & (df_data.index<=8),'6'] = '積載物重量制限超過'
df_data.head()
Out[3]: 6 5 4 3 2 1 0
0 速度超過 高速道路35以上40未満 40 35 30 20 20
1 速度超過 高速道路30以上35未満 30 25 20 15 15
2 速度超過 25以上30未満 25 18 15 12 12
3 速度超過 20以上25未満 20 15 12 10 10
4 速度超過 15以上20未満 15 12 9 7 7【レコードの指定】
loc[行、列] : 行と列を指定する。
→指定した後に代入することで解決!
column”5”とcolumn”6”を一つのセルにする。
【文字列結合】 .str.cat( )
・引数 na_rep
→結合元のセルにNaNが含んでいた場合、設定値に置き換え結合できる。
In [3]: df_data['5'] = df_data['6'].str.cat(df_data['5'], na_rep='')
df_data.head()
Out[3]: 6 5 4 3 2 1 0
0 速度超過 速度超過高速道路35以上40未満 40 35 30 20 20
1 速度超過 速度超過高速道路30以上35未満 30 25 20 15 15
2 速度超過 速度超過25以上30未満 25 18 15 12 12
3 速度超過 速度超過20以上25未満 20 15 12 10 10
4 速度超過 速度超過15以上20未満 15 12 9 7 7※column6は意味をなさなくなったので削除。
(drop( )と列方向なのでaxis=1)
In [4]: df_data = df_data.drop('6',axis=1)
df_data.columns = ['反則行為の種類(略号)', '大型車', '普通車', '二輪車', '小型特殊車', '原付車']
df_data.head()
Out[4]: 反則行為の種類(略号) 大型車 普通車 二輪車 小型特殊車 原付車
0 速度超過高速道路35以上40未満 40 35 30 20 20
1 速度超過高速道路30以上35未満 30 25 20 15 15
2 速度超過25以上30未満 25 18 15 12 12
3 速度超過20以上25未満 20 15 12 10 10
4 速度超過15以上20未満 15 12 9 7 7