Google ColabでPatentfieldAPIを使用したAIセマンティック検索

こんにちは、Patentfieldの公式noteです。
この記事では、PatentfieldのAIセマンティック検索をAPIで利用する方法について、解説します。
1.AIセマンティック検索とは
AIセマンティック検索は、複雑な検索式を作成しなくても、探したい技術のキーワードや文章、特許番号を入力するだけで、簡単に類似の特許を検索できます。
AIセマンティック検索の特徴は、Patentfieldに収録されている膨大な特許公報のタイトル/請求の範囲/明細書/出願人/発明者等の情報がAIによって事前に学習されています。それにより、特許公報内に出現するキーワードの意味を学習しています。

2.事前準備
・PatentfieldのAPIトークン(APIトークンがなくても、実行環境の構築までは可能です)
※PatentfieldのAPIサービスは有料オプションですが、無料トライアルも随時受付しています。ご興味あれば、APIトークンを発行しますので、下記URLからぜひお問合せください。
https://patentfield.com/apply#/
3.プログラミング言語、開発環境
・プログラム言語:Python
・開発環境:Google Colab
Google Colab(名称:Google Colaboratory)は、ブラウザベースの無料の開発環境で、Googleアカウントがあればインストール不要で、Pythonプログラミングを簡単に始めることができます。
4.作成したもの
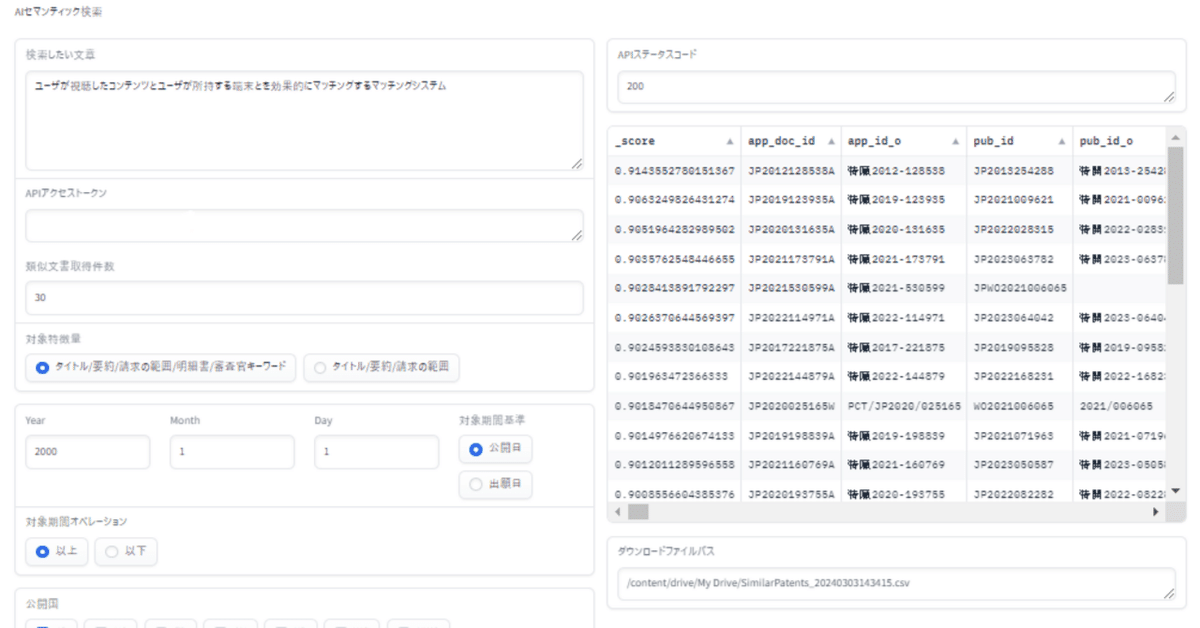
今回作成したものを実行すると、以下のような出力が得られます。
検索したい文章を入力すると、AIによってセマンティック検索(類似文献検索)が実行され、右側に検索結果の特許リスト類似度スコアと共に表示される簡単なWEBアプリケーションです。

このWEBアプリケーションでは、様々な検索条件(対象特徴量、検索対象期間、検索国、公報種別、リーガルステータス等)を自由に設定できますので、先行例調査や無効化資料調査等、様々な用途の調査に利用する事ができます。
Google Colab環境でPythonを使用して、PatentfieldのAPIにアクセスし、Gradioを使ってWebアプリ化しています。
Gradioは、機械学習モデルのデモを行うWebアプリケーションを簡単に作ることができるPythonのライブラリです。
5.実装
Google Calabでの実行手順は、次の通りです。
(1)ライブラリのインストール
# ライブラリインストール
!pip install requests
!pip install gradio(2)ライブラリインポート
# ライブラリインポート
import os
import requests
import gradio as gr
import pandas as pd
from datetime import datetime, timedelta, timezone(3)Googleドライブマウント
APIから取得したデータをCSVファイルとして取得するために、Googleドライブをマウントします。
# Googleドライブマウント
from google.colab import drive
drive.mount('/content/drive')(4)CSVファイル保存関数
# CSVファイル保存関数
def save_csv_to_drive(df, prefix):
# タイムゾーンの生成
JST = timezone(timedelta(hours=+9), 'JST')
timestamp = datetime.now(JST).strftime("%Y%m%d%H%M%S")
# CSVファイル名を生成(クエリとタイムスタンプを含む)
csv_filename = f"{prefix}_{timestamp}.csv"
# Googleドライブの保存先パスを設定
drive_path = "/content/drive/My Drive/"
full_path = os.path.join(drive_path, csv_filename)
# DataFrameをCSVファイルとして保存
df.to_csv(full_path, index=False, encoding="cp932", errors="ignore")
return full_path(5)AIセマンティック検索
ここでAPIに対してリクエストを送り、APIからのレスポンスデータを処理しています。
# AIセマンティック検索
def search_similar_patents(query, access_token, limit, feature, period_type, period_op, period_year, period_month, period_day, countries, statuses, kind_groups):
# Patentfield APIエンドポイント
req_url = 'https://api.patentfield.com/api/v1/patents/search'
# Patentfield APIリクエストヘッダー
req_headers = {'Authorization': 'Token ' + access_token, 'Content-Type': 'application/json'}
# リクエストパラメータマッピング
feature_mapping = {
"タイトル/要約/請求の範囲/明細書/審査官キーワード": "word_weights",
"タイトル/要約/請求の範囲": "claims_weights"
}
period_type_mapping = {
"公開日": "pub_date",
"出願日": "app_date"
}
period_op_mapping = {
"以上": "greater_than_or_equal_to",
"以下": "less_than_or_equal_to"
}
kind_groups_mapping = {
"特許出願公開(JP)A*": "published_patents_jp",
"特許(JP)B*": "patents_jp",
"特許出願公開(US)A1": "published_patents_us",
"特許(US)A,B*,E*": "patents_us"
}
statuses_mapping = {
"権利維持/係属中(JP)": "live_jp",
"権利維持(JP)": "patented_jp",
"係属中(JP)": "pending_jp",
"権利抹消済(JP)": "expired_jp",
"取下・放棄等(JP)": "abandoned_jp",
"権利維持/係属中(INPADOC)": "live_inpadoc",
"権利維持(INPADOC)": "patented_inpadoc",
"EP登録済(INPADOC)": "granted_inpadoc",
"調査/審査(INPADOC)": "examined_inpadoc",
"権利抹消済(INPADOC)": "expired_inpadoc"
}
# マッピングを使用してAPIに送信するフォーマットに変換
feature_api = feature_mapping.get(feature, feature)
period_type_api = period_type_mapping.get(period_type, period_type)
period_op_api = period_op_mapping.get(period_op, period_op)
kind_groups_api = [kind_groups_mapping.get(kind_group, kind_group) for kind_group in kind_groups]
statuses_api = [statuses_mapping.get(status, status) for status in statuses]
# 期間をYYYY-MM-DDフォーマットに整形
period = f"{period_year}-{period_month:02d}-{period_day:02d}"
# APIパラメータ
req_params = {
'q': query,
'search_type': 'semantic',
'limit': limit,
'feature': feature_api,
'period_type': period_type_api,
'period_op': period_op_api,
'period': period,
'countries': countries,
'statuses': statuses_api,
'kind_groups': kind_groups_api,
'columns': ["_score", "app_doc_id", "app_id_o", "pub_id", "pub_id_o", "exam_id", "exam_id_o", "app_date", "pub_date", "exam_date", "country", "apm_applicants", "patent_status", "title", "abstract", "ipcs", "fis", "themes", "fterms", "cpcs", "claims"]
}
print(f"req_params : {req_params}")
# API呼出
response = requests.post(url=req_url, headers=req_headers, json=req_params)
# APIレスポンス処理
if response.status_code == 200:
data = response.json()
records = data.get('records', [])
# Pandas DataFrameに変換
df = pd.DataFrame(records)
# CSVファイル保存
prefix = "SimilarPatents"
csv_filename = save_csv_to_drive(df, prefix)
return str(response.status_code), df, csv_filename
else:
return str(response.status_code), pd.DataFrame(), None(6)Webアプリ(Gradio)の定義
# Webアプリ(Gradio)定義
with gr.Blocks() as app:
gr.Markdown("AIセマンティック検索")
with gr.Row():
with gr.Column():
query = gr.Textbox(label="検索したい文章", lines=5, placeholder="検索したい文章を入力してください (例:ユーザが視聴したコンテンツとユーザが所持する端末とを効果的にマッチングするマッチングシステム")
access_token = gr.Textbox(label="APIアクセストークン", lines=1, placeholder="APIのアクセストークンを入力してください")
limit = gr.Number(label="類似文書取得件数", value=30)
feature = gr.Radio(label="対象特徴量", choices=["タイトル/要約/請求の範囲/明細書/審査官キーワード", "タイトル/要約/請求の範囲"], value="タイトル/要約/請求の範囲/明細書/審査官キーワード")
with gr.Row():
period_year = gr.Number(label="Year", minimum=1950, maximum=2100, step=1, value=2000)
period_month = gr.Number(label="Month", minimum=1, maximum=12, step=1, value=1)
period_day = gr.Number(label="Day", minimum=1, maximum=31, step=1, value=1)
period_type = gr.Radio(label="対象期間基準", choices=["公開日", "出願日"], value="公開日")
period_op = gr.Radio(label="対象期間オペレーション", choices=["以上", "以下"], value="以上")
countries = gr.CheckboxGroup(label="公開国", choices=["JP", "US", "EP", "CN", "KR", "WO", "NWO"], value="JP")
kind_groups = gr.CheckboxGroup(label="公報種別", choices=["特許出願公開(JP)A*", "特許(JP)B*", "特許出願公開(US)A1", "特許(US)A,B*,E*"], value="特許出願公開(JP)A*")
statuses = gr.CheckboxGroup(label="リーガルステータス", choices=["権利維持/係属中(JP)", "権利維持(JP)", "係属中(JP)", "権利抹消済(JP)", "取下・放棄等(JP)", "権利維持/係属中(INPADOC)", "権利維持(INPADOC)", "EP登録済(INPADOC)", "調査/審査(INPADOC)", "権利抹消済(INPADOC)"], value="権利維持/係属中(JP)")
submit = gr.Button("APIリクエスト送信", variant="primary")
reset = gr.Button("リセット")
with gr.Column():
status_code_output = gr.Textbox(label="APIステータスコード", lines=1, interactive=False)
response_output = gr.Dataframe()
download_fpath = gr.Text(label="ダウンロードファイルパス")
submit.click(
fn=search_similar_patents,
inputs=[
query, access_token, limit, feature, period_type, period_op,
period_year, period_month, period_day, countries, statuses, kind_groups
],
outputs=[status_code_output, response_output, download_fpath]
)
reset.click(
fn=lambda: ["", pd.DataFrame(), ""],
inputs=[],
outputs=[query, response_output, download_fpath]
)(7)Webアプリ(Gradio)を起動
ここでWebアプリ(Gradio)を起動します。
# Webアプリ(Gradio)起動
app.launch(debug=True, height=1000)Gradioが起動したら、検索したい文章とAPIアクセストークンを入力して、APIリクエスト送信をクリックしてください。
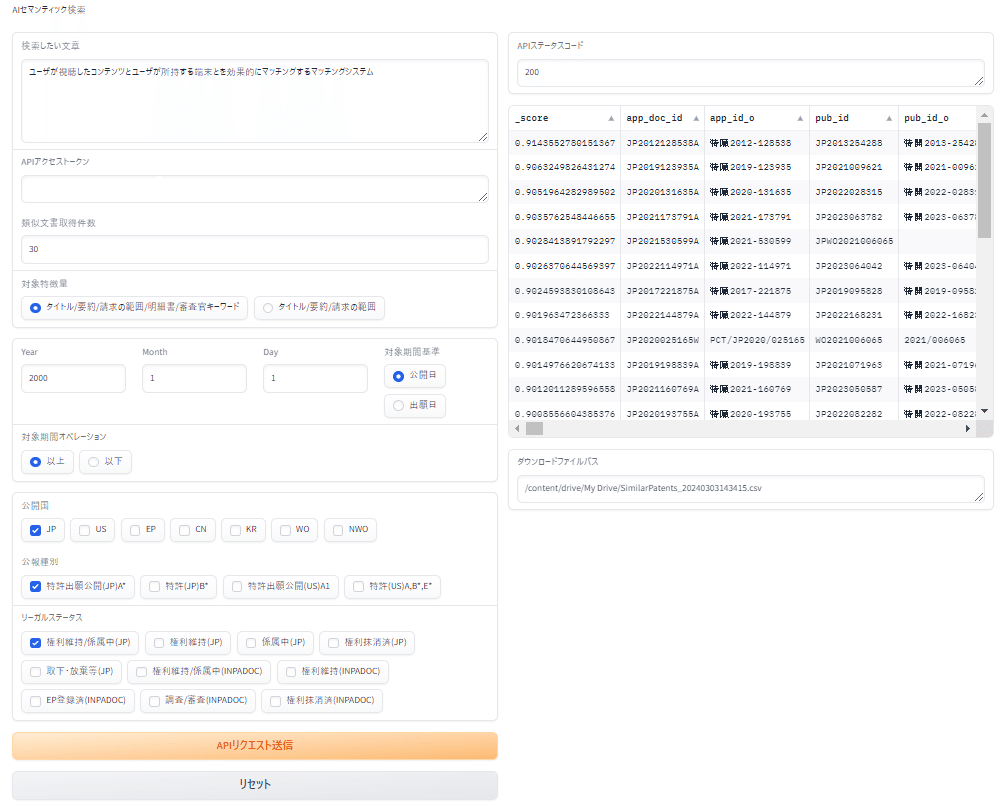
取得した類似文献特許リストはGoogleドライブのMy Driveに「SimilarPatents_{YYYYMMDDhhmmss}.csv」というファイル名で保存されています。
6.おわりに
Patentfieldとは
Patentfieldは、4つの機能(プロフェッショナル検索・データ可視化・AI類似検索・AI分類予測)を組み合わせて、ワンストップで総合的な検索・分析ができる『AI特許総合検索・分析プラットフォーム』です。
無料で検索もできるので、ご興味あればぜひアクセスください。
PatentfieldのAPIについて
PatentfieldのAPI連携サービスは、情報参照だけではなく、特許検索機能をはじめPatentfieldの各機能をAPI経由で連携することで、社内で運用しているグループウェアへの組み込みや、特許検索・分析の独自アプリケーションの開発が可能になります。
AIセマンティック検索やAI分類予測などのAI機能や、PFスコアや類似キーワードの取得などPatentfieldの多彩な機能を利用して、特許に関わる社内のニーズに合わせて最適なワークフローやアプリケーションを構築できます。
次回以降も、特許検索や分析実務で役立つ開発実装例を紹介していきます。
実践的なケーススタディを通じて、みなさまの知財業務変革のヒントになればと思います。