RAG(検索拡張生成)を使った特許公報チャットボットの構築

こんにちは、Patentfieldの公式noteです。
Patentfield公式noteでは、PatentfieldAPIを活用した具体的な開発実装事例を紹介しています。
この記事では、PatentfieldのAPIと大規模言語モデル(Google Gemini)を用いて、RAG(Retrieval Augmented Generation:検索拡張生成)を使った特許公報チャットボットを構築する方法について解説します。
1.RAG(Retrieval Augmented Generation:検索拡張生成)とは
RAGとは、Retrieval Augmented Generation(検索拡張生成)の略称で、大規模言語モデル(LLM)によるテキスト生成に外部情報の検索を組み合わせた技術です。
RAGの仕組み
RAGは主に以下の2つのフェーズで構成されています:
1.検索フェーズ(Retrieval Phase)
ユーザーの質問に対して、外部データベースから関連情報を検索・抽出します。
2.生成フェーズ(Generation Phase)
検索結果と質問をLLMに入力し、回答を生成します。
検索には、ベクトル検索や全文検索、またはそれらを組み合わせたハイブリッド検索が用いられます。
RAGのメリット
1.高い信頼性と精度: 最新の外部情報を参照することで、より正確な回答が可能になります。
2.情報の更新が容易: 外部データベースの更新だけで、最新情報を反映できます。
3.コスト効率: モデル全体の再学習が不要なため、費用対効果が高くなります。
4.パーソナライズされた回答: 独自の情報源を使用することで、特定のニーズに合わせた回答が可能になります。
今回は、PatentfieldのAPIと大規模言語モデル(Google Gemini)を用いて、特許公報に対するRAG環境を構築します。検索フェーズについては先月の記事(PatentfieldAPIで特許公報を自動取得して特許文書のベクトル検索を実施する)で紹介しています。今月は、生成フェーズとして、GoogleのGeminiを使って特許公報に対するチャット環境を構築します。

(出典:https://business.ntt-east.co.jp/content/cloudsolution/municipality/column-28.html)
2.事前準備
・PatentfieldのAPIトークン(APIトークンがなくても、実行環境の構築までは可能です)
※PatentfieldのAPIサービスは有料オプションですが、無料トライアルも随時受付しています。ご興味あれば、APIトークンを発行しますので、下記URLからぜひお問合せください。
https://patentfield.com/apply#/
・Google Gemini APIキー
Google AI StudioでGeminiのAPIキーを取得できます。現在(2024年10月)で、制限事項はあるものの、無料でAPIを使用する事ができます。
3.プログラミング言語、開発環境
・プログラム言語:Python
・開発環境:Google Colab
Google Colab(名称:Google Colaboratory)は、ブラウザベースの無料の開発環境で、Googleアカウントがあればインストール不要で、Pythonプログラミングを簡単に始めることができます。
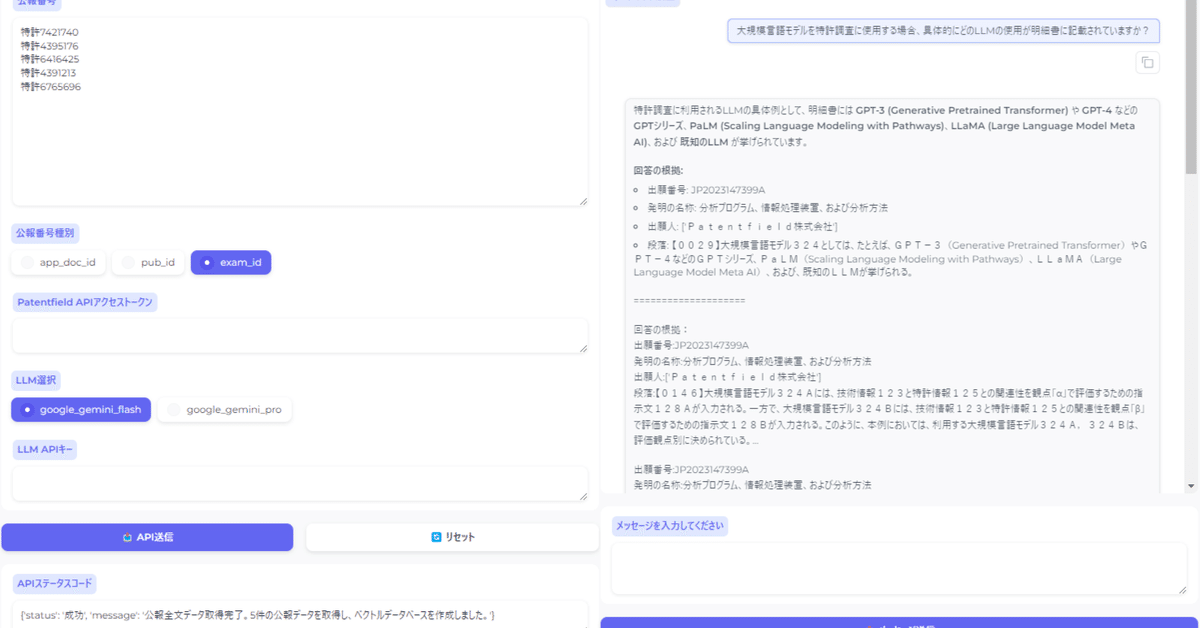
4.作成したもの
今回作成したものを実行すると、以下のような出力が得られます。
Patentfield APIで公報全文のテキストデータを取得し、そのテキストデータをベクトル化して、ベクトルデータベースを構築します。そして、そのベクトルデータベースとGoogle Geminiを使って、RAG(チャット)環境を構築します。

Google Colab環境でPythonを使用して、PatentfieldのAPIにアクセスし、オープンソースの埋め込みモデル(BAAI/bge-m3)と、Meta(Facebook)製の近似最近傍探索ライブラリ(Faiss)を使って、特許文書のベクトルデータベースを構築しています。このベクトルデータベースとGemini APIを組み合わせてRAG環境を構築することにより、特許文書に対するQA(チャット)を実施できるWebアプリケーションです。
Webアプリケーション化にはPythonのライブラリであるGradioを使っています。
5.実装
Google Calabでの実行手順は、次の通りです。
(1)ライブラリのインストール
# ライブラリインストール
!pip install requests
!pip install gradio
!pip install faiss-cpu
!pip install langchain
!pip install langchain-community
!pip install langchain-huggingface
!pip install langchain-google-genai大規模言語モデル(LLM)を使ったアプリケーションの作成を簡素化するように設計されたフレームワークであるLangchainを使用します。
(2)ライブラリインポート
# ライブラリインポート
import os
import re
import json
import pickle
import requests
import torch
from tqdm import tqdm
import gradio as gr
import numpy as np
import pandas as pd
from datetime import datetime, timedelta, timezone
from pydantic import BaseModel, Field
from typing import Optional, List, Any, Dict, Tuple
from langchain.document_loaders import DataFrameLoader
from langchain.text_splitter import TextSplitter
from langchain_community.vectorstores import FAISS
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda(3)Googleドライブマウント
APIから取得したデータをCSVファイル・JSONファイルとして保存するために、Googleドライブをマウントします。
# Googleドライブマウント
from google.colab import drive
drive.mount('/content/drive')(4)CSVファイル保存関数
# CSVファイル保存関数
def save_csv_to_drive(df, prefix):
# タイムゾーンの生成
JST = timezone(timedelta(hours=+9), 'JST')
timestamp = datetime.now(JST).strftime("%Y%m%d%H%M%S")
# CSVファイル名を生成(クエリとタイムスタンプを含む)
csv_filename = f"{prefix}_{timestamp}.csv"
# Googleドライブの保存先パスを設定
drive_path = "/content/drive/My Drive/"
full_path = os.path.join(drive_path, csv_filename)
# DataFrameをCSVファイルとして保存
df.to_csv(full_path, index=False, encoding="cp932", errors="ignore")
return full_path(5)JSONファイル保存関数
# JSONファイル保存関数
def save_json_to_drive(df, prefix):
# タイムゾーンの生成
JST = timezone(timedelta(hours=+9), 'JST')
timestamp = datetime.now(JST).strftime("%Y%m%d%H%M%S")
# JSONファイル名を生成(クエリとタイムスタンプを含む)
json_filename = f"{prefix}_{timestamp}.json"
# Googleドライブの保存先パスを設定
drive_path = "/content/drive/My Drive/"
full_path = os.path.join(drive_path, json_filename)
# DataFrameをJSONファイルとして保存
data = df.to_dict(orient='records')
with open(full_path, 'w', encoding='utf-8') as file:
json.dump(data, file, ensure_ascii=False, indent=2)
return full_path(6)公報全文取得関数
この関数でPatentfieldのAPIを呼び出し、指定した公報に対する公報全文(明細書)データを取得します。
# 公報全文取得
# AcquireFulltextItemsクラス定義
class AcquireFulltextItems(BaseModel):
name: str = Field(..., example="特許7421740")
id_type: str = Field(default="exam_id")
columns: Optional[List[str]] = Field(default=["app_doc_id", "app_id_o", "pub_id", "pub_id_o", "exam_id", "exam_id_o", "app_date", "pub_date", "exam_date", "country", "cross_applicants", "patent_status", "title", "abstract", "ipcs", "fis", "themes", "fterms", "cpcs", "problem", "effect", "technical_field", "background", "solution", "top_claim", "app_claims", "grant_claims", "description", "description_of_embodiment", "abstract_image", "drawings", "table_claims_images", "table_desc_images", "chem_claims_images", "chem_desc_images", "math_claims_images", "math_desc_images"])
# 公報全文取得関数
def acquire_fulltext(item: AcquireFulltextItems, access_token):
# Patentfield APIエンドポイント
req_url = f'https://api.patentfield.com/api/v1/patents/{item.name}'
# Patentfield APIリクエストヘッダー
req_headers = {'Authorization': 'Token ' + access_token, 'Content-Type': 'application/json'}
# APIクエリパラメータ
query_params = {
'id_type': item.id_type
}
if item.columns:
# 各カラムを `columns[]` としてクエリパラメータに追加
query_params.update({'columns[]': item.columns})
# エラー処理
try:
# API呼出
response = requests.get(url=req_url, params=query_params, headers=req_headers)
print(f"Status Code: {response.status_code}")
print(f"API Response: {response.text}")
# APIレスポンス処理
if response.status_code == 200:
try:
data = response.json()
records = data.get('record', {})
# Pandas DataFrameに変換
df = pd.DataFrame([records])
return str(response.status_code), df
except json.JSONDecodeError as e:
print(f"JSON Decode Error: {str(e)}")
print(f"Response content: {response.text}")
return str(response.status_code), pd.DataFrame()
else:
print(f"API Error: {response.status_code}: {response.text}")
print(f"Response content: {response.text}")
return response.status_code, pd.DataFrame()
except requests.RequestException as e:
print(f"Request Error: {str(e)}")
return "Request Error", pd.DataFrame()(7)特許文書用TextSplitterクラス
このクラスでPatenfieldのAPIから取得した特許文書をどのようなサイズに分割してベクトルデータベースを構築するかのテキスト分割に関する定義を行っています。今回は特許文書の段落毎に異なるチャンクに分割するようにクラスの設計を行っています。
# 特許文書用TextSplitterクラス
class PatentTextSplitter(TextSplitter):
def __init__(self, chunk_size: int = 8192, chunk_overlap: int = 0):
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
self.patterns = [
r'(【[^】]+】)', # 【】で囲まれた段落番号
r'(\[\d{4}\])' # [数字4桁]の形式の段落番号
]
self.combined_pattern = '|'.join(self.patterns)
def split_text(self, text: str) -> List[str]:
text = self._ensure_string(text)
parts = re.split(f'({self.combined_pattern})', text)
return self._process_parts(parts)
def split_text_with_metadata(self, text: str, metadata: dict) -> List[dict]:
chunks = self.split_text(text)
result = []
for i, chunk in enumerate(chunks):
chunk_metadata = metadata.copy()
chunk_metadata['chunk_index'] = i
result.append({
'content': chunk,
'metadata': chunk_metadata
})
return result
def _ensure_string(self, text: Any) -> str:
if not isinstance(text, str):
text = str(text)
return text
def _process_parts(self, parts: List[str]) -> List[str]:
processed_paragraphs = []
current_paragraph = ""
current_number = ""
for part in parts:
part = str(part) if part is not None else ""
if re.match(self.combined_pattern, part):
if current_paragraph:
processed_paragraphs.append(f"{current_number}{current_paragraph.strip()}")
current_number = part
current_paragraph = ""
else:
current_paragraph += part
if current_paragraph:
processed_paragraphs.append(f"{current_number}{current_paragraph.strip()}")
return processed_paragraphs(8)FAISSインデックス作成クラス
このクラスでPatenfieldのAPIから取得した特許文書のベクトル化処理を行っています。
# FAISSインデックス作成クラス
class FAISSIndexCreator:
def __init__(self, model_name: str, chunk_size: int = 8192, chunk_overlap: int = 0, batch_size: int = 16):
self.model_name = model_name
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
self.batch_size = batch_size
self.text_splitter = PatentTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.embeddings = HuggingFaceEmbeddings(model_name=model_name, model_kwargs={"device": self.device})
self.faiss_index = None
self.total_docs = 0
self.total_chunks = 0
def create_index(self, df: pd.DataFrame, column_name: str) -> FAISS:
all_chunks = []
all_metadatas = []
# データフレームの各行を処理
for index, row in tqdm(df.iterrows(), total=len(df), desc="テキスト分割中"):
text = row[column_name]
# テキストが有効かチェック
if not self.is_valid_text(text):
print(f"警告: 行 {index + 1} のテキストが空または無効です。スキップします。")
continue
text = str(text)
try:
# 全てのカラムをメタデータとして使用
metadata = {col: str(row[col]) for col in df.columns} # すべての値を文字列に変換
# テキストを分割し、メタデータを付与
chunks_with_metadata = self.text_splitter.split_text_with_metadata(text, metadata)
if not chunks_with_metadata:
print(f"警告: 行 {index + 1} のチャンクが空です。スキップします。")
continue
# 処理統計を更新
self.total_docs += 1
self.total_chunks += len(chunks_with_metadata)
# チャンクとメタデータを分離
chunks = [item['content'] for item in chunks_with_metadata]
metadatas = [item['metadata'] for item in chunks_with_metadata]
# チャンクとメタデータを分離
chunks = [item['content'] for item in chunks_with_metadata if item['content'].strip()]
metadatas = [item['metadata'] for item in chunks_with_metadata if item['content'].strip()]
all_chunks.extend(chunks)
all_metadatas.extend(metadatas)
except Exception as e:
print(f"エラー: 行 {index + 1} の処理中にエラーが発生しました: {str(e)}")
# チャンクをバッチでEmbedding
print("チャンクをバッチでEmbeddingしています...")
self.faiss_index = self.batch_create_index(all_chunks, all_metadatas)
print(f"{column_name} データ数 (テキスト分割前): {self.total_docs}")
print(f"{column_name} データ数 (テキスト分割後): {self.total_chunks}")
return self.faiss_index
def batch_create_index(self, chunks: List[str], metadatas: List[dict]) -> FAISS:
batch_size = self.batch_size
for i in tqdm(range(0, len(chunks), batch_size), desc="バッチ処理中"):
batch_chunks = chunks[i:i+batch_size]
batch_metadatas = metadatas[i:i+batch_size]
batch_vectors = self.embeddings.embed_documents(batch_chunks)
if self.faiss_index is None:
self.faiss_index = FAISS.from_embeddings(
list(zip(batch_chunks, batch_vectors)),
self.embeddings,
metadatas=batch_metadatas
)
else:
self.faiss_index.add_embeddings(
list(zip(batch_chunks, batch_vectors)),
metadatas=batch_metadatas
)
# GPUメモリをクリア
if self.device == "cuda":
torch.cuda.empty_cache()
return self.faiss_index
def is_valid_text(self, text: Any) -> bool:
if pd.isna(text):
return False
try:
return bool(str(text).strip())
except:
return False(9)RAGチャット処理関数
この関数で、LLMモデル選択(gemini-flash or gemini-pro)、プロンプト生成、Retriever設定、LangchainのLCEL設定を行い、ユーザーからのクエリに対して、類似文書の検索とそれを用いたチャットの設定を実施しています。
# RAGチャット処理関数
def process_rag_chat(user_input, chat_history, faiss_index, model_type, api_key):
# LLMモデル選択
if model_type == 'google_gemini_flash':
google_api_key = api_key
llm = ChatGoogleGenerativeAI(model='gemini-1.5-flash-latest', google_api_key=google_api_key, temperature=0.0)
elif model_type == 'google_gemini_pro':
google_api_key = api_key
llm = ChatGoogleGenerativeAI(model='gemini-1.5-pro-latest', google_api_key=google_api_key, temperature=0.0)
else:
return chat_history, "エラー: 無効なLLMタイプです"
# 会話履歴メモリ初期化
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
# チャット履歴をメモリに追加
for human, ai in chat_history:
memory.chat_memory.add_user_message(human)
memory.chat_memory.add_ai_message(ai)
# Retriever設定
if faiss_index is None:
# FAISSインデックスがNoneの場合、ファイルから読み込む
index_path = "faiss_index.pkl"
if os.path.exists(index_path):
with open(index_path, "rb") as f:
faiss_index = pickle.load(f)
print(f"FAISSインデックスを読み込みました: {index_path}")
else:
return chat_history, "エラー: FAISSインデックスが見つかりません"
retriever = faiss_index.as_retriever(search_kwargs={"k": 3})
# プロンプトテンプレート定義
template = """以下の会話と文脈を使用して、人間の質問に答えてください。
文脈: {context}
会話履歴: {chat_history}
人間: {question}
AI: 質問に対する回答を提供します。回答の際は回答の根拠を必ず記載してください。また、回答の根拠には出願番号と該当の記載がある段落番号を記載してください。
例:特許情報の分析に大規模言語モデルを利用し、新たな価値を提供することが望まれている。 (出願番号:JP2023147399A、【0005】)
回答の根拠:
{sources}
"""
prompt = ChatPromptTemplate.from_template(template)
# Retriever&フォーマット関数
def retrieve_and_format(input_dict):
question = input_dict["question"]
docs = retriever.get_relevant_documents(question)
context = "\n".join([doc.page_content for doc in docs])
sources = "\n\n".join([
f"出願番号: {doc.metadata.get('app_doc_id', '-')}\n"
f"発明の名称: {doc.metadata.get('title', '-')}\n"
f"出願人: {doc.metadata.get('cross_applicants', '-')}\n"
f"段落: {doc.page_content[:200]}..."
for doc in docs
])
chat_history = memory.load_memory_variables({})["chat_history"]
return {
"context": context,
"chat_history": chat_history,
"question": question,
"sources": sources
}
# 回答の根拠フォーマット関数
def format_sources(sources):
return sources.replace(" ", "")
# チェイン設定
chain = (
RunnablePassthrough()
| RunnableLambda(retrieve_and_format)
| {"response": prompt | llm, "sources": lambda x: format_sources(x["sources"])}
)
# デバッグ用のプリント文
print("User input:", user_input)
print("Chat history:", chat_history)
# LCELチェイン実行
try:
result = chain.invoke({"question": user_input})
answer = result["response"].content if hasattr(result["response"], 'content') else str(result["response"])
sources = result["sources"]
memory.save_context({"input": user_input}, {"output": answer}) # チャット履歴をメモリに追加
formatted_response = f"{answer}\n\n{'=' * 20}\n\n回答の根拠:\n{sources}" # AIのanswerとsourcesを接続する
message = (user_input, formatted_response)
chat_history.append(message)
return chat_history, ""
except Exception as e:
print(f"エラーが発生しました: {e}")
return chat_history, f"エラーが発生しました: {str(e)}"(10)Webアプリ(Gradio)バックエンド実装
ここでWebアプリ(Gradio)から呼び出される際に実行されるバックエンド機能を関数として実装しています。
# 単一公報データ取得関数
def process_single_name(name: str, id_type: str, access_token: str) -> Optional[pd.DataFrame]:
item = AcquireFulltextItems(name=name.strip(), id_type=id_type)
status_code, df = acquire_fulltext(item, access_token)
return df if not df.empty else None
# 公報全文取得Wrapper関数
def acquire_fulltext_wrapper(names: str, id_type: str, access_token: str) -> Tuple[int, pd.DataFrame, Optional[str], Optional[str]]:
all_records = [df for name in names.split("\n") if name.strip() and (df := process_single_name(name, id_type, access_token.strip())) is not None]
if not all_records:
return 400, pd.DataFrame(), None, None
df_final = pd.concat(all_records, ignore_index=True)
prefix = "FullTextsLLM"
csv_filename = save_csv_to_drive(df_final, prefix)
json_filename = save_json_to_drive(df_final, prefix)
return 200, df_final, csv_filename, json_filename
# 公報全文取得+FAISSインデックス作成
def api_submit_and_create_index(names: str, id_type: str, access_token: str) -> Tuple[Dict[str, str], Any]:
# 公報全文取得
status_code, df, csv_filename, json_filename = acquire_fulltext_wrapper(names, id_type, access_token)
faiss_index = None
if not df.empty:
# FAISSインデックス作成
index_creator = FAISSIndexCreator(model_name="BAAI/bge-m3", chunk_size=8192, chunk_overlap=0, batch_size=16)
faiss_index = index_creator.create_index(df=df, column_name="description")
print("FAISSインデックスが正常に作成されました")
# FAISSインデックスをファイルに保存
index_path = "faiss_index.pkl"
with open(index_path, "wb") as f:
pickle.dump(faiss_index, f)
print(f"FAISSインデックスを保存しました: {index_path}")
else:
print("データフレームが空のため、FAISSインデックスは作成されませんでした")
status = {
"status": "成功" if status_code == 200 else "エラー",
"message": f"公報全文データ取得完了。{len(df)}件の公報データを取得し、ベクトルデータベースを作成しました。" if not df.empty else "公報全文データの取得に失敗しました。",
}
return status, faiss_index
# チャット履歴処理関数
def gradio_process_rag_chat(user_input, chat_history, faiss_index, model_type, api_key):
updated_history, error_message = process_rag_chat(user_input, chat_history, faiss_index, model_type, api_key)
if error_message:
updated_history.append((user_input, error_message))
return "", updated_history(11)Webアプリ(Gradio)フロントエンド実装
ここでWebアプリ(Gradio)のフロントエンド機能を実装しています。
# GradioカスタムCSS
custom_css = """
.gradio-container, .gradio-container *, .gradio-container .label { font-size: 12px !important; }
.container { max-width: 1200px; margin: auto; padding: 2px; }
.content { display: flex; gap: 2px; }
.sidebar { flex: 1; }
.main-content { flex: 2; }
.gradio-button { transition: all 0.3s ease; }
.gradio-button:hover { transform: translateY(-2px); box-shadow: 0 4px 6px rgba(0,0,0,0.1); }
.navigation-buttons { display: flex; justify-content: space-between; width: 100%; }
.navigation-buttons .gradio-button { flex: 1; margin: 0 5px; }
"""
# Webアプリ(Gradio)フロントエンド実装
with gr.Blocks(css=custom_css, theme='gradio/soft') as app:
faiss_index_state = gr.State(None)
results_state = gr.State([])
chat_history_state = gr.State([])
with gr.Row(elem_classes="content"):
with gr.Column(elem_classes="sidebar"):
names_input = gr.Textbox(label="公報番号", lines=10, placeholder="特許番号を入力してください(1行に1つ)")
id_type_input = gr.Radio(label="公報番号種別", choices=["app_doc_id", "pub_id", "exam_id"], value="exam_id")
access_token_input = gr.Textbox(label="Patentfield APIアクセストークン")
model_type = gr.Radio(label="LLM選択", choices=["google_gemini_flash", "google_gemini_pro"], value="google_gemini_flash")
api_key = gr.Textbox(label="LLM APIキー",lines=1, placeholder="LLMのAPIキーを入力してください")
with gr.Row():
submit_button = gr.Button("📤 API送信", variant="primary")
reset_button = gr.Button("🔄 リセット", variant="secondary")
status_code_output = gr.Textbox(label="APIステータスコード", lines=1, interactive=False)
with gr.Column(elem_classes="main-content"):
chatbot = gr.Chatbot(
label="チャット履歴",
height=630,
show_copy_button=True,
line_breaks=True, # 改行を<br>タグに変換
)
user_input = gr.Textbox(label="メッセージを入力してください", lines=2)
send_button = gr.Button("📤 メッセージ送信", variant="primary")
# APIリクエスト送信ボタン
submit_button.click(
fn = api_submit_and_create_index,
inputs = [names_input, id_type_input, access_token_input],
outputs = [status_code_output, faiss_index_state]
)
# リセットボタン
reset_button.click(
fn = lambda: ["", "", None, None],
inputs = [],
outputs=[names_input, status_code_output, faiss_index_state, chat_history_state]
)
# チャット送信ボタン
send_button.click(
fn = gradio_process_rag_chat,
inputs = [user_input, chatbot, faiss_index_state, model_type, api_key],
outputs = [user_input, chatbot]
)(12)Webアプリ(Gradio)を起動
ここでWebアプリ(Gradio)を起動します。
# Webアプリ(Gradio)起動
app.launch(debug=True)Gradioが起動したら、以下の手順で特許文書に対するRAG(チャット)を実施する事ができます。
1.特許情報を取得したい公報番号をまとめてリストで入力
2.Patentfield APIアクセストークンを入力
3.LLMを選択(google_gemini_flash or google_gemini_pro)
4.LLM APIキーを入力
5.「API通信」ボタンを押すと、Patentfield APIから公報全文のテキストデータを取得し、オープンソースの埋め込みモデル(BAAI/bge-m3)を使ってベクトルデータベースを構築します。ベクトルデータベースの作成が完了したら、ステータス欄に、「{'status': '成功', 'message': '公報全文データ取得完了。○件の公報データを取得し、ベクトルデータベースを作成しました。'}」と表示されます。
6.チャットメッセージ入力欄に、問い合わせたい内容を入力して、「メッセージ送信」ボタンを押すと、取得した特許公報に対して、LLMとチャットをする事ができます。

6.おわりに
Patentfieldでは、2024年7月より、「Patentfield AIR」というPatentfieldのインターフェースに生成AI機能を組み込むことで、PatentfieldのAI検索機能をはじめ各種検索機能を利用して最大1万件の国内外の検索母集団に対して、一括で生成AIの出力結果を得ることができるオプション機能をリリースしました。

https://patentfield.com/news/256#/
Patentfieldとは
Patentfieldは、4つの機能(プロフェッショナル検索・データ可視化・AI類似検索・AI分類予測)を組み合わせて、ワンストップで総合的な検索・分析ができる『AI特許総合検索・分析プラットフォーム』です。
無料で検索もできるので、ご興味あればぜひアクセスください。
PatentfieldのAPIについて
PatentfieldのAPI連携サービスは、情報参照だけではなく、特許検索機能をはじめPatentfieldの各機能をAPI経由で連携することで、社内で運用しているグループウェアへの組み込みや、特許検索・分析の独自アプリケーションの開発が可能になります。
AIセマンティック検索やAI分類予測などのAI機能や、PFスコアや類似キーワードの取得などPatentfieldの多彩な機能を利用して、特許に関わる社内のニーズに合わせて最適なワークフローやアプリケーションを構築できます。
次回以降も、特許検索や分析実務で役立つ開発実装例を紹介していきます。
実践的なケーススタディを通じて、みなさまの知財業務変革のヒントになればと思います。
#Python
#Google Colab
#Gradio
#AI
#生成AI
#LLM
#Gemini
#ベクトル検索
#RAG
#Langchain
#Patentfield
#特許
#知財
#知的財産