Google ColabでPatentfieldAPIを使用した公報全文取得

こんにちは、Patentfieldの公式noteです。
Patentfield公式noteでは、PatentfieldAPIを活用した具体的な開発実装事例を紹介しています。
この記事では、PatentfieldのAPIを使って特許公報の全文を取得する方法について解説します。
1.公報全文取得とは
特許公報の全文を取得するためには、通常は検索データベースからダウンロードする手法が一般的かと思います。ブラウザ版のPatentfieldにおいても、検索した後に、エクセルフォーマット or CSVフォーマットで特許公報の書誌情報だけでなく、公報全文(明細書)のテキストデータを取得する事ができます。
知財業務のDXを推進するために、公報全文のテキストデータを使って自然言語処理を実施したり、生成AIを活用するシーンを想定した時に、特許の母集団のテキストデータを検索データベースから手動でダウンロードするのではなく、システム(アプリケーション)から直接、公報全文のテキストデータを取得できれば、業務効率をアップさせることができますし、ユーザニーズに沿った独自のアプリケーションを構築する事ができます。
PatentfieldのAPIには、特許公報の書誌情報だけでなく、公報全文のテキストデータをAPI経由で取得する事ができます。この記事では、まずは公報全文のテキストデータを取得するアプリケーションについて紹介し、次回以降は、取得したテキストデータを活用したアプリケーションについて紹介する予定です。
2.事前準備
・PatentfieldのAPIトークン(APIトークンがなくても、実行環境の構築までは可能です)
※PatentfieldのAPIサービスは有料オプションですが、無料トライアルも随時受付しています。ご興味あれば、APIトークンを発行しますので、下記URLからぜひお問合せください。
https://patentfield.com/apply#/
3.プログラミング言語、開発環境
・プログラム言語:Python
・開発環境:Google Colab
Google Colab(名称:Google Colaboratory)は、ブラウザベースの無料の開発環境で、Googleアカウントがあればインストール不要で、Pythonプログラミングを簡単に始めることができます。
4.作成したもの
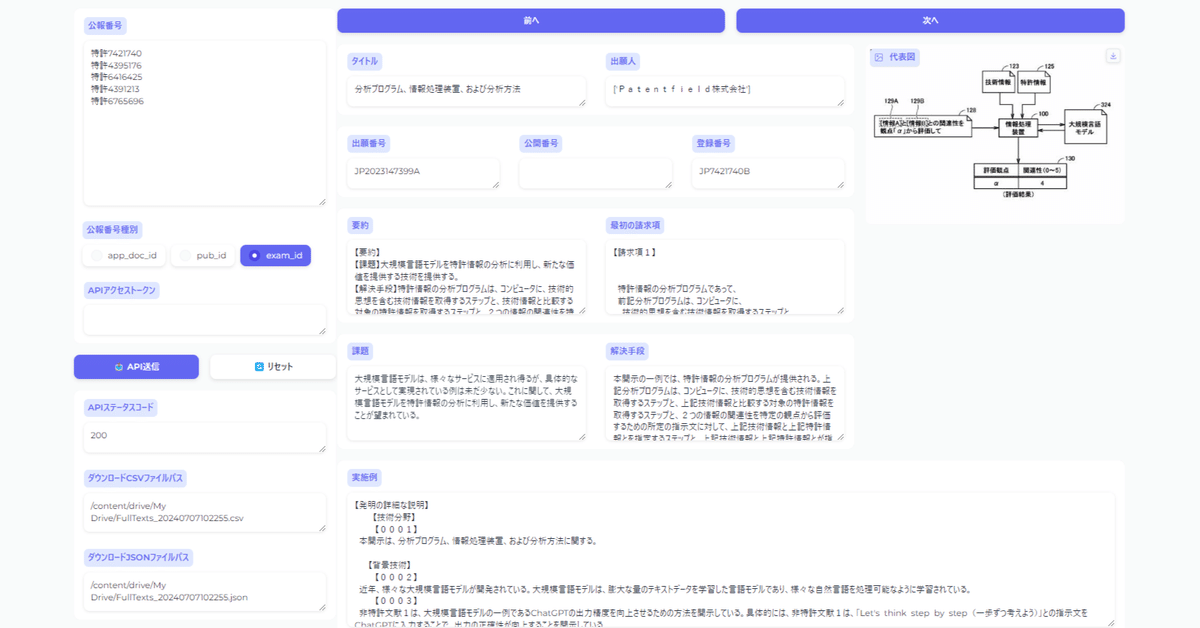
今回作成したものを実行すると、以下のような出力が得られます。
特許公報の書誌情報・公報全文(明細書)・図面情報を取得したい公報番号をまとめてリストで入力し実行すれば、各種情報を確認する事ができるビューワーになります。
アプリケーションに表示させている情報以外にも、取得したい情報はAPIリクエストパラメータに含める事で自由に選択・追加する事ができます。
Google Colab環境でPythonを使用して、PatentfieldのAPIにアクセスし、Gradioを使ってWebアプリ化しています。
Gradioは、機械学習モデルのデモを行うWebアプリケーションを簡単に作ることができるPythonのライブラリです。
5.実装
Google Calabでの実行手順は、次の通りです。
(1)ライブラリのインストール
# ライブラリインストール
!pip install requests
!pip install gradio(2)ライブラリインポート
# ライブラリインポート
import os
import json
import requests
import gradio as gr
import pandas as pd
from datetime import datetime, timedelta, timezone
from pydantic import BaseModel, Field
from typing import Optional, List(3)Googleドライブマウント
APIから取得したデータをCSVファイルとして取得するために、Googleドライブをマウントします。
# Googleドライブマウント
from google.colab import drive
drive.mount('/content/drive')(4)CSVファイル保存関数
# CSVファイル保存関数
def save_csv_to_drive(df, prefix):
# タイムゾーンの生成
JST = timezone(timedelta(hours=+9), 'JST')
timestamp = datetime.now(JST).strftime("%Y%m%d%H%M%S")
# CSVファイル名を生成(クエリとタイムスタンプを含む)
csv_filename = f"{prefix}_{timestamp}.csv"
# Googleドライブの保存先パスを設定
drive_path = "/content/drive/My Drive/"
full_path = os.path.join(drive_path, csv_filename)
# DataFrameをCSVファイルとして保存
df.to_csv(full_path, index=False, encoding="cp932", errors="ignore")
return full_path(5)JSONファイル保存関数
今回からCSVファイルだけでなく、JSONファイルへの保存関数も実装しておきます。
# JSONファイル保存関数
def save_json_to_drive(df, prefix):
# タイムゾーンの生成
JST = timezone(timedelta(hours=+9), 'JST')
timestamp = datetime.now(JST).strftime("%Y%m%d%H%M%S")
# JSONファイル名を生成(クエリとタイムスタンプを含む)
json_filename = f"{prefix}_{timestamp}.json"
# Googleドライブの保存先パスを設定
drive_path = "/content/drive/My Drive/"
full_path = os.path.join(drive_path, json_filename)
# DataFrameをJSONファイルとして保存
data = df.to_dict(orient='records')
with open(full_path, 'w', encoding='utf-8') as file:
json.dump(data, file, ensure_ascii=False, indent=2)
return full_path(6)文献取得関数
ここでPatentfieldのAPIを呼び出し、公報全文(明細書)データを含む、指定した公報データの取得を行います。
# 文献取得
# AcquireFulltextItemsクラス定義
class AcquireFulltextItems(BaseModel):
name: str = Field(..., example="特許7421740")
id_type: str = Field(default="exam_id")
columns: Optional[List[str]] = Field(default=["app_doc_id", "app_id_o", "pub_id", "pub_id_o", "exam_id", "exam_id_o", "app_date", "pub_date", "exam_date", "country", "cross_applicants", "patent_status", "title", "abstract", "ipcs", "fis", "themes", "fterms", "cpcs", "problem", "effect", "technical_field", "background", "solution", "top_claim", "app_claims", "grant_claims", "description", "description_of_embodiment", "abstract_image", "drawings", "table_claims_images", "table_desc_images", "chem_claims_images", "chem_desc_images", "math_claims_images", "math_desc_images"])
# 文献取得関数
def acquire_fulltext(item: AcquireFulltextItems, access_token):
# Patentfield APIエンドポイント
req_url = f'https://api.patentfield.com/api/v1/patents/{item.name}'
# Patentfield APIリクエストヘッダー
req_headers = {'Authorization': 'Token ' + access_token, 'Content-Type': 'application/json'}
# APIクエリパラメータ
query_params = {
'id_type': item.id_type
}
if item.columns:
# 各カラムを `columns[]` としてクエリパラメータに追加
query_params.update({'columns[]': item.columns})
# エラー処理
try:
# API呼出
response = requests.get(url=req_url, params=query_params, headers=req_headers)
print("Status Code:", response.status_code)
print("API Response:", response.text)
# APIレスポンス処理
if response.status_code == 200:
try:
data = response.json()
records = data.get('record', {})
# Pandas DataFrameに変換
df = pd.DataFrame([records])
return str(response.status_code), df
except json.JSONDecodeError as e:
print(f"JSON Decode Error: {str(e)}")
print(f"Response content: {response.text}")
return str(response.status_code), pd.DataFrame()
else:
print("API Error:", response.status_code, response.text)
print(f"Response content: {response.text}")
return str(response.status_code), pd.DataFrame()
except requests.RequestException as e:
print(f"Request Error: {str(e)}")
return "Request Error", pd.DataFrame()(7)Webアプリ(Gradio)の定義
# APIレスポンスを取得し、結果をGradioの状態にマッピングする関数
def acquire_fulltext_wrapper(names, id_type, access_token):
all_records = []
for name in names.split("\n"):
name=name.strip() # 各行の前後の空白を削除
if not name: # 空の文字列や空白のみの行をスキップ
continue
item = AcquireFulltextItems(
name=name,
id_type=id_type,
)
status_code, df = acquire_fulltext(item, access_token)
if not df.empty:
all_records.append(df)
if all_records:
df_final = pd.concat(all_records, ignore_index=True)
prefix = "FullTexts"
csv_filename = save_csv_to_drive(df_final, prefix)
json_filename = save_json_to_drive(df_final, prefix)
# 最初のレコードのデータを抽出
if not df_final.empty:
initial_title = df_final.iloc[0]["title"]
initial_cross_applicants = df_final.iloc[0]["cross_applicants"]
initial_abstract = df_final.iloc[0]["abstract"]
initial_top_claim = df_final.iloc[0]["top_claim"]
initial_problem = df_final.iloc[0]["problem"]
initial_solution = df_final.iloc[0]["solution"]
initial_description = df_final.iloc[0]["description"]
initial_image = df_final.iloc[0]["abstract_image"]
initial_app_id = df_final.iloc[0].get("app_doc_id", "")
initial_pub_id = df_final.iloc[0].get("pub_id", "")
initial_exam_id = df_final.iloc[0].get("exam_id", "")
else:
initial_title, initial_cross_applicants, initial_abstract, initial_image = "", "", "", ""
initial_app_id, initial_pub_id, initial_exam_id = "", "", ""
initial_top_claim, initial_problem, initial_solution, initial_description = "", "", ""
return status_code, df_final, csv_filename, json_filename, initial_title, initial_cross_applicants, initial_abstract, initial_top_claim, initial_problem, initial_solution, initial_description, initial_image, initial_app_id, initial_pub_id, initial_exam_id
else:
return "No data", pd.DataFrame(), None, None, "", "", "", "", "", "", "", "", "", "", ""
# 次のレコードにナビゲートする関数
def navigate_next(df, current_index):
new_index = (current_index + 1) % len(df) # 最後のインデックスから最初にループ
record = df.iloc[new_index]
return new_index, record["title"], record["cross_applicants"], record["abstract"], record["top_claim"], record["problem"], record["solution"], record["description"], record["abstract_image"], record.get("app_doc_id", ""), record.get("pub_id", ""), record.get("exam_id", "")
# 前のレコードにナビゲートする関数
def navigate_prev(df, current_index):
new_index = (current_index - 1) % len(df) # 最初のインデックスから最後にループ
record = df.iloc[new_index]
return new_index, record["title"], record["cross_applicants"], record["abstract"], record["top_claim"], record["problem"], record["solution"], record["description"], record["abstract_image"], record.get("app_doc_id", ""), record.get("pub_id", ""), record.get("exam_id", "")
# リセット関数の定義
# APIステータスコード:空文字列、DataFrame(状態):空のDataFrame、CSVファイルパス:空文字列、JSONファイルパス:空文字列、現在のインデックス:0(初期化)
# タイトル:空文字列、出願人:空文字列、要約:空文字列、 最初の請求項:空文字列、課題:空文字列、解決手段:空文字列、実施例:空文字列
# 代表図:None、出願番号:空文字列、公開番号:空文字列、登録番号:空文字列、公報番号:デフォルトのサンプル公報番号、公報番号種別:exam_id
def reset_all():
return ["", pd.DataFrame(), "", "", 0, "", "", "", "", "", "", "", None, "", "", "", "", "exam_id"]
# GradioカスタムCSS
custom_css = """
.gradio-container, .gradio-container *, .gradio-container .label { font-size: 12px !important; }
.container { max-width: 1200px; margin: auto; padding: 2px; }
.content { display: flex; gap: 2px; }
.sidebar { flex: 1; }
.main-content { flex: 2; }
.gradio-button { transition: all 0.3s ease; }
.gradio-button:hover { transform: translateY(-2px); box-shadow: 0 4px 6px rgba(0,0,0,0.1); }
.navigation-buttons { display: flex; justify-content: space-between; width: 100%; }
.navigation-buttons .gradio-button { flex: 1; margin: 0 5px; }
"""
# Webアプリ(Gradio)定義
with gr.Blocks(css=custom_css, theme='WeixuanYuan/Soft_dark') as app:
with gr.Row(elem_classes="content"):
with gr.Column(elem_classes="sidebar"):
name = gr.Textbox(label="公報番号",lines=10, placeholder="全文を取得したい公報番号を入力してください (例:特許7421740\n特許7421741 各公報番号は改行区切り)")
id_type = gr.Radio(label="公報番号種別", choices=["app_doc_id", "pub_id", "exam_id"], value="exam_id")
access_token = gr.Textbox(label="APIアクセストークン",lines=1, placeholder="APIのアクセストークンを入力してください")
with gr.Row():
submit = gr.Button("📤 API送信", variant="primary")
reset = gr.Button("🔄 リセット", variant="secondary")
status_code_output = gr.Textbox(label="APIステータスコード", lines=1, interactive=False)
download_csvpath = gr.Text(label="ダウンロードCSVファイルパス")
download_jsonpath = gr.Text(label="ダウンロードJSONファイルパス")
with gr.Column(scale=3, elem_classes="main-content"):
with gr.Row(elem_classes="navigation-buttons"):
prev_button = gr.Button("前へ", variant="primary")
next_button = gr.Button("次へ", variant="primary")
with gr.Row():
with gr.Column(scale=2):
with gr.Row():
title_output = gr.Textbox(label="タイトル", lines=1, interactive=False)
cross_applicants_output = gr.Textbox(label="出願人", lines=1, interactive=False)
with gr.Row():
app_id_output = gr.Textbox(label="出願番号", lines=1, interactive=False)
pub_id_output = gr.Textbox(label="公開番号", lines=1, interactive=False)
exam_id_output = gr.Textbox(label="登録番号", lines=1, interactive=False)
with gr.Row():
abstract_output = gr.TextArea(label="要約", lines=5, max_lines=5, interactive=False)
top_claim_output = gr.TextArea(label="最初の請求項", lines=5, max_lines=5, interactive=False)
with gr.Row():
problem_output = gr.TextArea(label="課題", lines=5, max_lines=5, interactive=False)
solution_output = gr.TextArea(label="解決手段", lines=5, max_lines=5, interactive=False)
with gr.Column(scale=1):
image_output = gr.Image(label="代表図")
with gr.Row():
description_output = gr.TextArea(label="実施例", lines=10, max_lines=10, interactive=False)
df_state = gr.State(pd.DataFrame())
current_index_state = gr.State(0)
# APIリクエスト送信ボタン
submit.click(
fn=acquire_fulltext_wrapper,
inputs=[name, id_type, access_token],
outputs=[status_code_output, df_state, download_csvpath, download_jsonpath, title_output, cross_applicants_output, abstract_output, top_claim_output, problem_output, solution_output, description_output, image_output, app_id_output, pub_id_output, exam_id_output]
)
# リセットボタン
reset.click(
fn=reset_all,
inputs=[],
outputs=[status_code_output, df_state, download_csvpath, download_jsonpath, current_index_state, title_output, cross_applicants_output, abstract_output, top_claim_output, problem_output, solution_output, description_output, image_output, app_id_output, pub_id_output, exam_id_output, name, id_type]
)
# 次ボタン
next_button.click(
fn=navigate_next,
inputs=[df_state, current_index_state],
outputs=[current_index_state, title_output, cross_applicants_output, abstract_output, top_claim_output, problem_output, solution_output, description_output, image_output, app_id_output, pub_id_output, exam_id_output]
)
# 戻るボタン
prev_button.click(
fn=navigate_prev,
inputs=[df_state, current_index_state],
outputs=[current_index_state, title_output, cross_applicants_output, abstract_output, top_claim_output, problem_output, solution_output, description_output, image_output, app_id_output, pub_id_output, exam_id_output]
)(8)Webアプリ(Gradio)を起動
ここでWebアプリ(Gradio)を起動します。
# Webアプリ(Gradio)起動
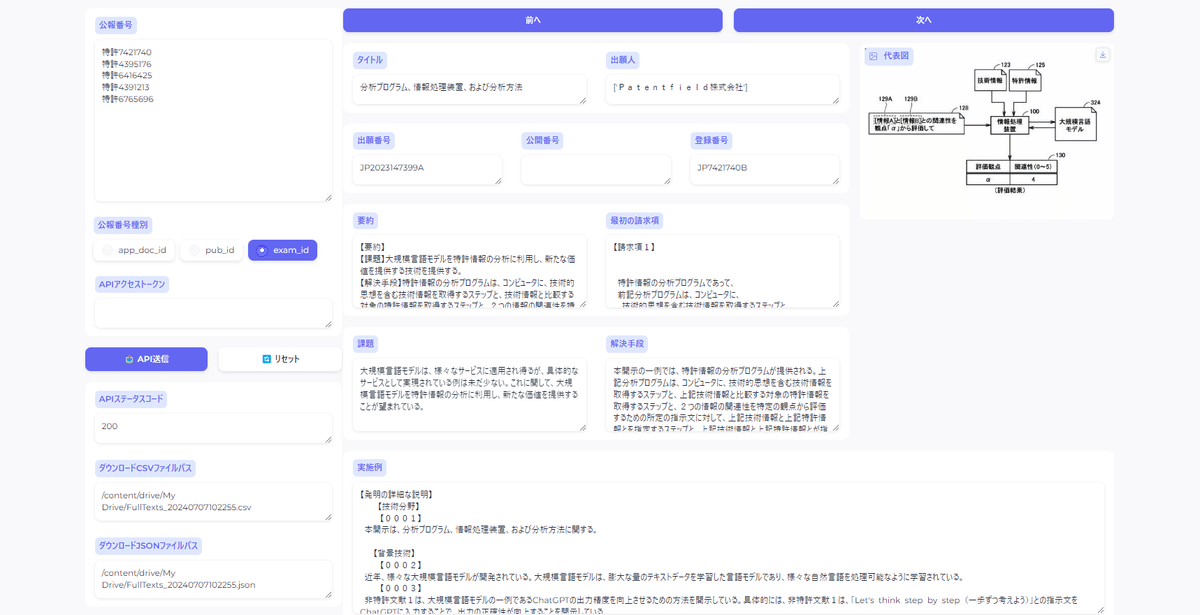
app.launch(debug=True)Gradioが起動したら、特許情報を取得したい公報番号をまとめてリストで入力し、「API送信」ボタンを押すと、1件1件公報全文のテキストデータを含めた特許情報を閲覧する事ができるビューワーが起動します。
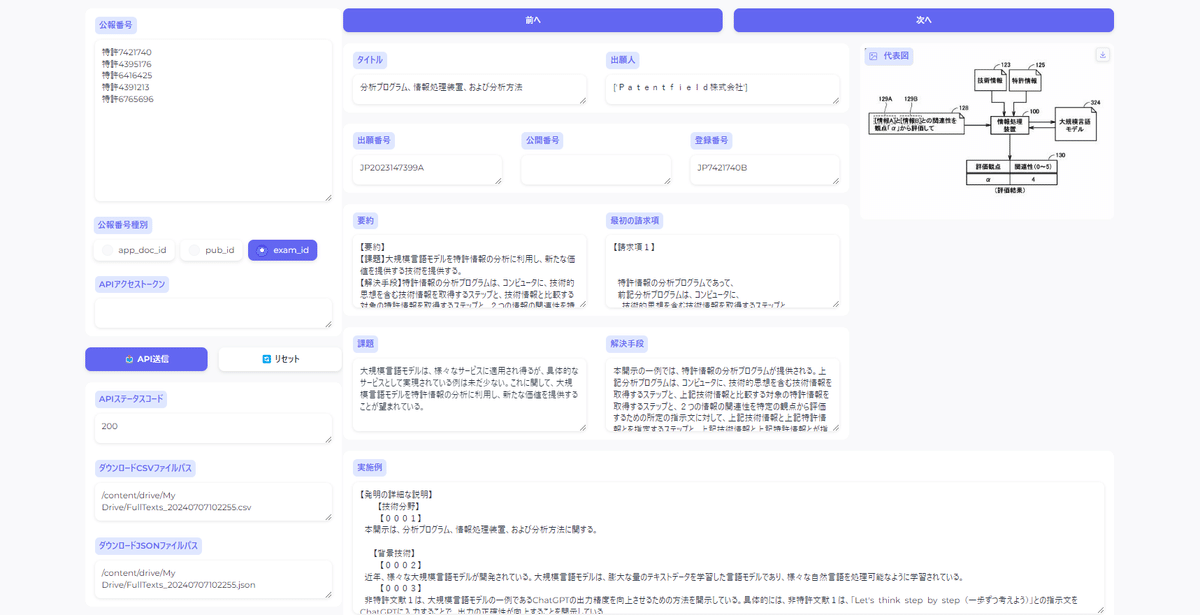
取得した公報リストはGoogleドライブのMy Driveに「FullTexts_{YYYYMMDDhhmmss}.csv」と「FullTexts_{YYYYMMDDhhmmss}.json」というファイル名で保存されています。
6.おわりに
Patentfieldとは
Patentfieldは、4つの機能(プロフェッショナル検索・データ可視化・AI類似検索・AI分類予測)を組み合わせて、ワンストップで総合的な検索・分析ができる『AI特許総合検索・分析プラットフォーム』です。
無料で検索もできるので、ご興味あればぜひアクセスください。
PatentfieldのAPIについて
PatentfieldのAPI連携サービスは、情報参照だけではなく、特許検索機能をはじめPatentfieldの各機能をAPI経由で連携することで、社内で運用しているグループウェアへの組み込みや、特許検索・分析の独自アプリケーションの開発が可能になります。
AIセマンティック検索やAI分類予測などのAI機能や、PFスコアや類似キーワードの取得などPatentfieldの多彩な機能を利用して、特許に関わる社内のニーズに合わせて最適なワークフローやアプリケーションを構築できます。
次回以降も、特許検索や分析実務で役立つ開発実装例を紹介していきます。
実践的なケーススタディを通じて、みなさまの知財業務変革のヒントになればと思います。
#Python
#Google Colab
#Gradio
#AI
#Patentfield
#特許
#知財
#知的財産