
【CPU性能も重要?】Llama2をローカル環境で動かしてみる

生成AIに触れてみる
WONDEMENTでも使ってます
2022年あたりから急速な盛り上がりを見せている生成AIですが、
その中でも画像生成AIは既にWONDEMENTの中でも使い始めています。
例えばWONDEMENTのメンバーが持っている名刺の裏には、そのメンバーの部屋のイメージして生成した画像が使われているのですが、これは画像生成AIのStable Diffusion XLとAdobeのFireflyを使用して生成した画像になっています。

それ以外にも色々とアイデアを巡らせて作品制作にも使えないのか試している日々です。
君はLlama2を知っているか
chatGPTはGPT3.5またはGPT4といった大規模言語モデル(LLM)と元に動いています。
そしてこのchatGPTやその根幹をなすGPT3.5,GPT4はOpenAIというアメリカの会社が開発、運用しています。
ただこのchatGPT以外にも生成AIは存在しているわけで、今回はその中でもfacebookやInstagramの運営元として有名なMeta社が開発した大規模言語モデルである「Llama2」を使ってみます。
Llama2は「Large Language Model Meta AI 2」の略で、昨年2月に発表されたLlamaの後継版として昨年7月に発表されています。
Llama2をローカルで動かせるか
ローカルで動かすとはどういうことか
さてここから本題に入っていきます。
chatGPTを例にして話をしますが、chatGPTではwebサイト上からアクセスし、web上で入力したテキスト(指示)をOpenAI側のサーバーで処理してその回答が表示される仕組みになっています。
つまり自分のPCでAIが動いているわけではなく、AIの処理は基本サービス運営元で行われています。
そのため誰でも簡単に使える反面、トークンと呼ばれるクレジットのようなものを消費する形で生成出来る回数が限られていたりすることがあります。
それに対して自分のPCの中で処理をしてAIを動かすことをローカル処理と言います。
先程のStable Diffusion XLも自分でモデルをダウンロードしたりしてローカルで動かせるようにして使っています。

Stable Diffusion web UIというAIを使うためのアプリを入れて使っています
ローカルの最大のメリットは「制約がない」ことです。
ルールに則って使っていれば何回でも生成することが出来ます。
ただAIの難しい処理を自分のPCのみで行うため、高スペックのPCが求められるというハードルの高さがあります。
これを参考にさせていただきました。
画像生成AIのローカル導入は「Stable Diffusion XL」やその前のバージョンである「Stable Diffusion 1.5」で経験済みです。
↓こちらのnoteで触れているのでぜひ読んでみてください
しかしそうでない生成AIの導入は初なので、今回これらの記事を参考にしながら進めてみました。
こちらのサイトでは「Text generation web UI」というものを使って動かす方法が紹介されています。
このText generation web UIは画像生成AIでいう「Stable DiffusionStable Diffusion web UI」と同じwebアプリようなものだと思います。
いざ実践
Text generation web UIを試す
公式ページの「Installation」というセクションからOS事にダウンロードが出来ると書かれているのですが、この記事が書かれてから少し時間がかかっているからかそういった記載が見当たりません。
ページを見ていくと「How to Install」というインストール手順が書かれたセクションがあったので、そこにある「Download」を押してみます。

すると「text-generation-webui-main」という圧縮ファイルをダウンロード出来ます。
ページには「OS に応じてstart_linux.sh、start_windows.bat、start_macos.sh、いずれかのスクリプトを実行します」と書いてあるので「start_windows.bat」を押します。
するとコマンドプロンプトが出てきて色々を処理が進み、しばらくするとどのGPUを使っているかを尋ねられます。
自分はNvidiaのRTX3080Tiを使っているので「A」を押して進みます。

色々な必要と思われるものが自動でダウンロードされていき、完了するとこの表示が出てきます。

英語なのでよく分かりませんが、
・まだモデルが入ってないので入れる必要がある
・モデルはweb UIの「model」タブから入れる
ということが書かれています。
その下にweb UIにアクセスするためのURLが書かれているので、それをコピーしてブラウザに貼り付けてアクセスします。
アクセスするとchatGPTのような画面が出てきます。
後はサイトの解説と同じく、上のタブ一覧から「model」タブを開き「Download custom model or LoRA」欄に
TheBloke/Llama-2-7b-Chat-GPTQ
と記入してダウンロードを押すとダウンロードが始まります。
完了するとダウンロードボタンの下に「Done!」と表示が出て完了です。
モデルを入れ終わったらそのモデルを選択します。
「model」タブのモデル選択メニューの右にあるリロードボタンを押してモデル選択を行います。

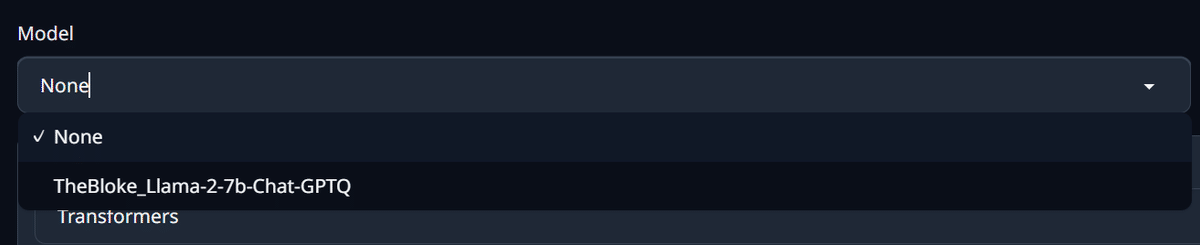
あとはChatタブで好きにチャットをするだけです。
CPUにも負荷がかかる
実際に使ってみて感じたのですが、画像生成AIはGPUばかりに負荷がかかるのに対して、こういったチャット系のAIだとCPUにも負荷がかかっているように見えます。
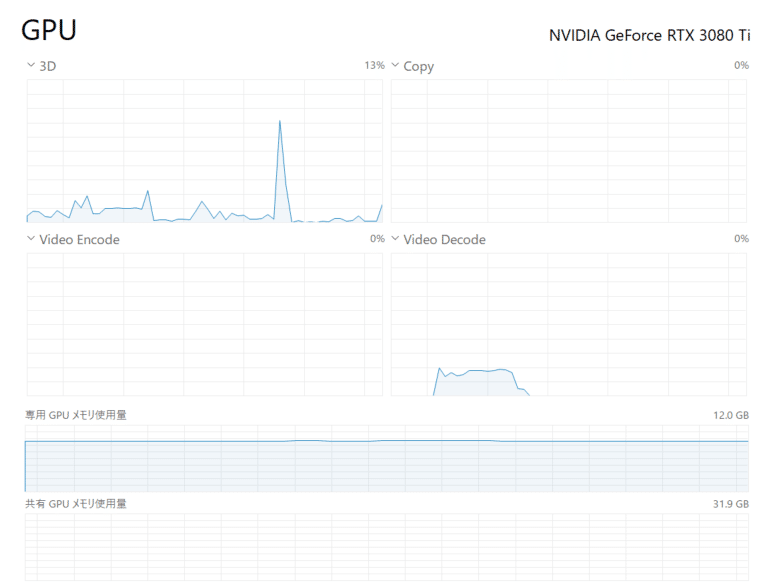

画像生成と違ってずっと処理がかかっている訳ではないからか負荷がかかるのは一瞬ですが、GPT、CPUどちらにも処理が入っている感じがあり、これは画像生成AIとは違った挙動のように見えます。
高速に動かすためにはGPUだけではなく一定のCPU性能も求められるのかもしれません。
最後に
今回はMeta社が開発した「Llama2」をローカルで動かしてみました。
Llama2はText generation web UIの使い心地も関係しますが、chatGPTと比べて微妙だと感じる点もあります。
しかもローカルで動かすためには単にモデルをダウンロードするだけでは動かず、動作させるためのweb UIなど一緒に導入する必要のあるものが多くてハードルが高いです。
ただ一度成功すればLlama2であれば無料で商用利用も可能なので、自分であれば作品制作など色々なことに使えるかもしれません。
そういった様々な活用方法を研究出来るのがローカルで導入することのメリットだと思います。
それではまた!