
コレポン分析でクロス集計表ではわかりづらい健康データ項目間の傾向を把握すると...

「働くひとの健康を世界中に創る」というパーパスを掲げるiCARE社の2022年の注力ポイントは何かと言うと、健康データの活用がその一つにあげられます。
Carelyファイブリングスというカンパニーケアに対する独自のフレームワークも発表しました。
そこで2022年初回のnote投稿では、厚労省のサイトに公開されている心の健康(悩みやストレスの原因)に関するクロス集計データをもとに、多変量解析手法の一つであるコレスポンデンス(通称コレポン)分析を行い、そこからどんなことがわかるのかを紹介してみたいと思います。
(※本記事は多変量解析を自ら手掛けたことがない方向けの内容です。また、弊社プロダクトのCarelyとは直接的には関係しておりません。)
コレスポンデンス分析でわかること
健康に限らず、客観的なマーケットデータから傾向を導き出す手法として、アンケート調査がありますよね。
アンケート調査の回答結果は通常、選択回答式になっているので、サンプル属性と掛け合わせてクロス集計表ができます。
クロス集計表では表頭、表側それぞれの項目ごとにどこのサンプルサイズが多い又は少ないかはわかりますが、選択肢の数や属性項目数が脳が一度に処理できる数個(いわゆる「マジカルナンバー7±2」)を超えてくると、全体の相対的傾向がつかみづらくなります。
こうした課題に対して、クロス集計表の表頭と表側の項目全体の相関関係を2軸で可視化してくれる分析手法の一つがコレスポンデンス分析になります。
クロス集計表やその棒グラフなどとの違い
今回、サンプルデータとして、政府統計ポータルサイト(e-Stat)に掲載されている「令和元年国民生活基礎調査結果」を活用してみます。
具体的には、年齢階級別の悩みやストレスの原因についての回答結果(複数回答)になります。
【表頭項目の内容】
a 家族との人間関係
b 家族以外との人間関係
c 恋愛・性に関すること
d 結婚
e 離婚
f いじめ、セクシュアル・ハラスメント
g 生きがいに関すること
h 自由にできる時間がない
i 収入・家計・借金等
j 自分の病気や介護
k 家族の病気や介護
l 妊娠・出産
m 育児
n 家事
o 自分の学業・受験・進学
p 子どもの教育
q 自分の仕事
r 家族の仕事
s 住まいや生活環境
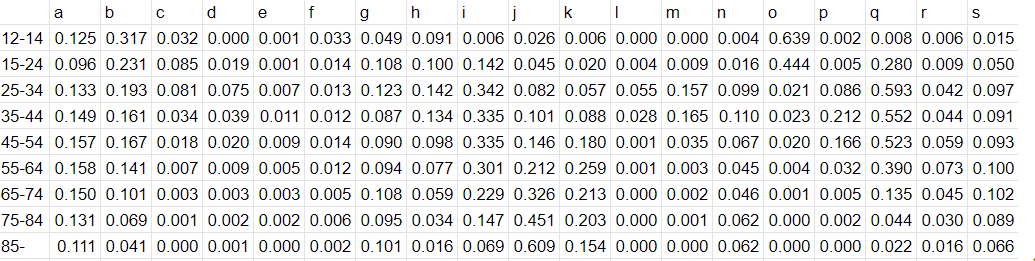
上記がダウンロードしたデータに基づくクロス集計表になります。「悩みやストレスあり」と回答した人の原因(複数回答)別の割合を全国年齢階級別に表したデータです。
表側で9、表頭で19も項目があります。
この数字の羅列から傾向を瞬時に判断するのはとてもムズい。。
では棒グラフにしてはどうかと、単純にスプシのグラフ機能を使うとこうなります。

外部資料などでこういった棒グラフのスライドをちょくちょく見かけますが、ちょっとカオスです。
(年齢階級)✕(悩みやストレスの原因)の関係性をコレスポンデンス分析で可視化
こちらが今回のデータを使ったコレポン分析結果としての散布図です。

PythonのMCA(Multiple Correspondence Analysis)というパッケージを活用すれば、クロス集計表のcsvファイルを使って比較的容易に上記のような散布図を出力できます。
今回はGoogle Colaboratoryを使ってPythonを動かしています。
散布図の見方として、近い距離にある項目間には親和性が高いこと、外れ値は他の項目と異なる特徴をもつことを表します。

上記グラフでいうと、右下の「12-14」と「o=自分の学業・受験・進学」は相対的にこの年代特有の悩み・ストレスの原因であるということがわかります。
中央部「15-24」と「f=いじめ、セクシュアル・ハラスメント」、「b=家族以外との人間関係」が近い距離にあることもわかります。
実感ありますかね⁈
また、中央部の「c=恋愛・性に関すること」、「h=自由にできる時間がない」はどの年齢階級とも距離があり、働くひとの年齢に依存しない普遍的な悩み・ストレスの原因であることを示唆していそうです。
いい大人になっても煩悩から離れられず、忙しそうに働いている現代人の姿といったところでしょうか。
通常の散布図は、サンプルデータが2軸にマッピングされているかと思いますが、このコレポン分析の散布図では逆にサンプルデータの集計結果をもとに、表頭と表側の項目間の相関が最大になるように、スコアを与えて2軸で表したものです。
なので、2軸が何を表しているのかは、グラフから人間が読み取る必要があります。
上記の結果をみると、横軸は右から左へ若い順に並んでおり、年齢を表していそうです。
縦軸を読み解くのはちょっと悩ましい。
上から並べると、次のようにパートナー間にまつわる悩み・ストレスの原因が並んでいることがわかります。
l 妊娠・出産
m 育児
d 結婚
p 子どもの教育
e 離婚
表側項目である年齢階級も25-34以降は上から下へと並んでいるので、結婚後年齢を追うごとの特徴的な悩み・ストレス原因が下へと続いているようです。
逆に下から表頭項目を並べると次のようになり、高齢になると身体的な健康とともに、生きがい、いわゆるウェルビーイングに関心(悩み・ストレスの原因)が集まることを表しているようです。
j 自分の病気や介護
k 家族の病気や介護
g 生きがいに関すること
コレポン分析で気をつけたいこと
このように、クロス集計表をもとに表頭・表側の項目全体の関係性を視覚的につかめるコレスポンデンス分析ですが、いくつか注意すべき点があります。
✅ サンプルデータの大小はわからないので、クロス集計表とセットで分析することが必要
コレスポンデンス分析は項目間の相対的な関係性を可視化してくれますが、近い位置関係にある項目が「最大数」を表しているわけではないことに留意する必要があります。
上記散布図を例にとると「15-24」と「f=いじめ、セクシュアル・ハラスメント」は最も近い距離関係にありますが、「15-24」における最大の悩み・ストレスの原因が「f=いじめ、セクシュアル・ハラスメント」ではないという点です。
下記色分けしたクロス集計表の通り、この年齢階級における最大のそれは「12-14」同様に「o=自分の学業・受験・進学」です。

項目ごとの最大値、最小値は上記のようにスプレッドシートの条件付け書式機能を使ってヒートマップのようにクロス集計表を色付けしてみるとわかりやすくなりますね。
よって集計データを分析する時は、「森=コレスポンデンス分析」、「木=クロス集計表」という両面から見極める必要があるということになります。
✅ 2軸がすべてを表しているわけではないこと
コレスポンデンス分析には寄与率という概念があり、各軸が集計データをどれぐらい説明できているかを表しています。
散布図では2軸しか表わせないですが、裏では他の軸でもスコアリングされており、そのうちの寄与率の高い2軸で散布図としてマッピングされているというわけです。
ちなみに上記散布図での寄与率は高くはないので、あくまで参考データとして見てください。
最後に
データは客観性を与えてくれ、人間の思い込みを正してくれたり、新たな視座を提供してくれたりしますが、基本的に過去の事象の結果です。
過去の延長ではない何か新しいコトを成し遂げていくためには、社会をこうしたいという個人の内面にあるユニークな考え方がドライバーにもなりますよね。
データによる客観性と個人の強烈な思い込みをうまく使い分けていきたいと思うしだいです。
そういえば年末、映画館でシリーズ約20年ぶりとなるマトリックス レザレクションズを鑑賞するとともに、過去の3部作もNetflixで見返しました。
モーフィアスのセリフにこんなフレーズがありましたね。
What is Real? How do you define real?
現実とはなんだ? 現実をどう定義するのだ?
No one can be told what the Matrix is. You have to see it for yourself.
マトリックスが何なのかを誰もあなたに教えることはできない。自分の目で見て、掴むしかないのだ
最後まで読んでいただき、ありがとうございました。
少しでも気づきがあったら「スキ」や「フォロー」をください!僕もそら丸(うちの猫)も跳んで喜びます!