
Pythonで基本統計量 ~分散・尖度・歪度~

(1)前回からの続き
前回は、基本統計量として平均、標準偏差、最小、最大等を算出しました。今回はPandasのdescriveでは算出できない分散・尖度・歪度を算出したいと思います。
分散・尖度・歪度の意味は下記のとおりです。
・分散
分布のひろがりを表す統計量。
・尖度(せんど)、歪度(わいど)
分布が正規分布からどれだけ尖っているかを表す統計量。0の場合、正規分布になります。
(2)使うデータ
前回と同じく、irisデータを使います。
(3)実際に計算してみる
今回のコードは下記のとおりです。1~3行目までは前回と同じです。
import pandas as pd
df = pd.read_csv('iris.csv')
print(df)
var = df.var() #分散
kurt = df.kurt() #尖度
skew = df.skew() #歪度
print("分散:\n", var)
print("尖度:\n", kurt)
print("歪度:\n", skew)4~6行目
var = df.var() #分散
kurt = df.kurt() #尖度
skew = df.skew() #歪度 4行目:分散(Variance)を算出します。
5行目:尖度(Skewness)を算出します。
6行目:歪度(Kurtosis)を算出します。
ここで前回のおさらいですが、平均・標準偏差等の基本統計量の算出に使用したコードは下記です。
df.describe()今回の分散・尖度・歪度は「.」以下を変更しただけです。ちなみに、平均や標準偏差等も下記のように算出できます。平均だけほしい、標準偏差だけほしい、という場合はdescribeではなく、下記のコードを用いることもあります。
df.mean() #平均
df.std() #標準偏差 詳細は下記のURLをご確認ください。
https://pandas.pydata.org/docs/reference/frame.html
なお、「#~」はコメントです。あってもなくてもいいですが、何の処理をしているのかを書いておくと便利です。
7~9行目
print("分散:\n", var)
print("尖度:\n", kurt)
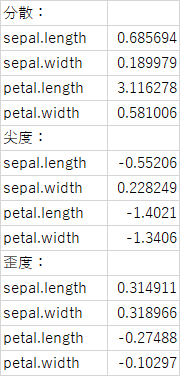
print("歪度:\n", skew)算出した結果を表示するコードで、下記のように列ごとに算出してくれます(見やすくするため表形式に直しています)。コードにある「\n」は改行を意味します。なお、ここでは結果の読み方までは説明しません。
(4)まとめ
実際のデータ分析の現場では、尖度・歪度を用いて正規性の検定を行なうことは少ないように思います。たとえば私の専門分野の査読論文では、正規性の検定にシャピロ-ウィルク検定やコルモゴロフ・スミルノフ検定が使われていることが多いです。このあたりも今後紹介したいと思います。
尖度・歪度を算出する大事なポイントは、分析者の主観で「このデータは正規分布だ!」と決めつけないようにすることだと思います。
また分散は、前回算出した標準偏差の平方根になります。自分が分析したいデータのばらつきを把握したうえで、データ分析を行なうことが重要です。
(5)参考
■Pandasで算出できる基本統計量
https://pandas.pydata.org/docs/reference/frame.html
■分散の意味(このページは数式等もあり、Web辞書として便利です。)
https://bellcurve.jp/statistics/glossary/1032.html
■尖度・歪度の意味
https://bellcurve.jp/statistics/glossary/2113.html
https://bellcurve.jp/statistics/glossary/2135.html