
Pythonで基本統計量 ~データ分析の第1歩~

(0)作業環境
・Python3.9.4
・Spyder
・Anaconda3
(1)データの特徴を確認
データの特徴に応じて統計解析の手法が異なります。そのため、データを分析する際には、データのサイズ(個数)や平均、標準偏差、最大、最小といったデータの特徴を確認することが重要です。これらは基本統計量と呼ばれます。(基本統計量の詳細な解説は統計の本やWebをみてください。)
もちろん、基本統計量はExcelのデータ分析やRでも確認することができますが、ここではPythonを用いた確認方法を紹介します。
(2)使うデータ
Pythonを使った統計解析の方法をWebで調べると、"iris"というデータに出くわすことが多くあります。ここでは、このirisのデータを例にしていきたいと思います。下記のようなデータで、このHPから引用しました。
(3)実際に基本統計量を算出
コードは下記のとおりです。それぞれの行の意味を紹介していきます。今回は1回目の記事ですので、過剰に説明していきます。
import pandas as pd
df = pd.read_csv('iris.csv')
print(df)
describe = df.describe()
print(describe)
describe.to_csv('iris_基本統計量.csv')まず、1行目
import pandas as pd これは、「Pandasというライブラリを使います!」という宣言を意味します。これを書かないとPandasというライブラリは使えません。
※Pandasについては、下記を参照ください。
https://pandas.pydata.org/
次に、2行目
df = pd.read_csv('iris.csv') ※私はアンケート結果等の分析が多いので、自分のPC上で分析することを想定しています。
ここでは、1行目で使用を宣言したPandasの機能を使って、分析に使用するcsvデータを読み込んでいます。このとき、読み込む列を指定したりもできますが、それは別の機会にまとめます。
Pythonとcsvデータを同じディレクトリに保存しているので、上記のような書き方をしています。もしPythonとcsvデータが別のディレクトリの場合は、きちんとディレクトリを指定する必要があります。
3行目
print(df) 読み込んだcsvの中身を確認します。このコードの結果は下記画像のとおりです。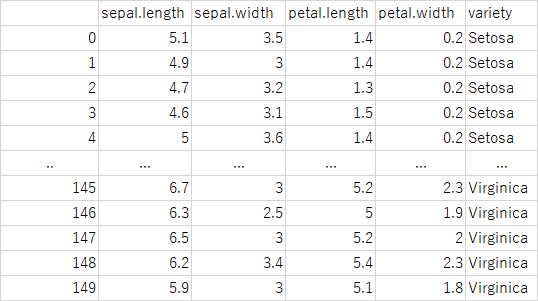
4行目・5行目
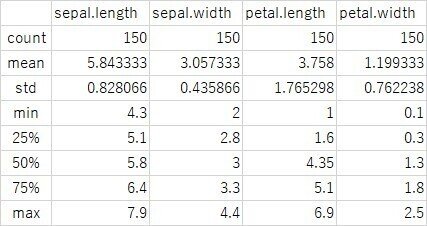
describe = df.describe()
print(describe) 4行目が基本統計量の算出に必要なコードになります。1行です。これで下記の基本統計量を列ごとに算出できます。
Pandasのdescribeで算出できる基本統計量
・データのサイズ(個数)
・平均
・標準偏差
・最小
・第一四分位
・中央値
・第三四分位
・最大
5行目は、算出した基本統計量を確認しています。コードを動かした結果は下記のとおりです。それぞれ計算できています。
6行目
describe.to_csv('iris_基本統計量.csv')算出した基本統計量をcsvとして保存します。この場合、Pythonデータと同じディレクトリに保存されます。もし、別のディレクトリに保存したい場合は、その場所を指定してあげればOKです。
(4)まとめ
今回はPythonで基本統計量を算出する方法を紹介しました。しかし、基本統計量は、上述のもの以外にもいくつかあり(たとえば分散など)、今回紹介したコードでは確認できません。この辺は今後紹介していきたいと思います。
(5)参考
■Pandasのdescribeについて
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.describe.html?highlight=describe
■Pandasのto_csvについて
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_csv.html?highlight=to_csv#pandas.DataFrame.to_csv