GPTの歴史

こんにちは。初めての投稿は、GPTの歴史をまとめてみたいと思います。
今やGPT4、Gemini、Claudeなどたくさんのモデルが競争していますが、GPTがどのように生まれてきたかを整理することで、本質が理解できるのではと思っています。
調べれば調べるほどわからないことが増えるので(笑)、徐々にコンテンツとして昇華できればいいなと思っております。
GPTの歴史
GPTの歴史について、主要な出来事を中心にまとめてみました。
2015年・・・イーロン・マスク、サム・アルトマンらによってOpen AIが設立される
2017年・・・Transformerの論文が発表される
2018年・・・GPT-1 登場
2019年・・・GPT-2 登場
2020年・・・GPT-3 登場
2022年・・・GPT-3.5搭載 ChatGPTリリース
2023年・・・GPT-4 リリース
Transformerの論文発表から、1年毎に新しいGPTが出てきています。
なにやらTransformerという技術がとても重要そうなのは疑いようが有りません。
Transformerの詳細は別途ダイブするとして、それぞれのGPTの特徴を整理します。
GPT-1
特徴
semi-supervised approach という、「半」教師あり学習というのが特徴。
半というのは、「教師なし事前学習」に、「教師ありファインチューニング」という工程を足したもの。
完全に教師なしじゃなくて、あとから教師あり学習を足しましたよー、なので「半」教師有りというアプローチ。
semi-supervised approach = unsupervised pre-training + supervised fine-tuning
ファインチューニングについてはいつか詳細を調べようと思います。
論文
Improving Language Understanding by Generative Pre-Training
GPT-2
特徴
構造はGPT-1と同じ。
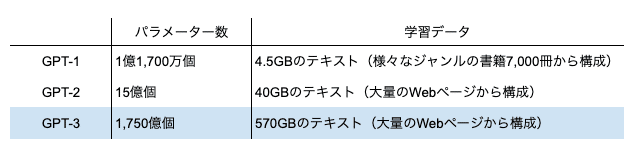
パラメーター数と、学習データが大きく増えた。

パラメーター数が約12.8倍、データ量が8.8倍に増えました。
論文
Language Models are Unsupervised Multitask Learners
GPT-3
特徴
従来のモデルと違い、「ファインチューニング」無しなのが特徴。
これにより、教師データを作成するコストや、関連する制限の一切が無くなり、学習コストが大幅に下がった。
また学習量(データ)も増えました。
また、この時期に「Scaling raw」という重大な法則が発見されています。
これは、Transformerというアルゴリズムは、データの投入量に応じて精度が上がる、というとんでもない発見です。
Scaling rawについては、よく書籍でも出てくる単語なので、別の記事で改めて整理したいです。
論文
Language Models are Few-Shot Learners
GPT-3.5(ChatGPT)
特徴
ChatGPTとして、対話型のGUIが提供されたことにより爆発的に普及しました。
また、パラメーター数も3,550億個と増えました。
GPT-4
特徴
とにかく精度が更に向上しました。
また写真をアップロードして、何が写っているかの説明もできるようになっています。

これ、幼少期にほしかった(笑)。
パラメーター数や、技術的な違いについては、非公開となっているようです。
ただ、難関なあらゆる試験を突破するGPT-4は、もはやこの世で一番賢い存在といっても過言ではないと思います。
米独の研究者から成るチームの調査リポートによると、米国の会計関連の主な資格である公認会計士(CPA)、公認管理会計士(CMA)、公認内部監査人(CIA)、EA(税理士)の試験を解かせてみたところ、最新版「ChatGPT4」は平均スコア85.1%と好成績を上げ、全て合格した。4つの試験とも合格率は50%前後。
また、2024年5月に公開されたセールスフォース・ドットコム創業者のマーク・ベニオフとのインタビューで、サム・アルトマンは飛躍的な精度の向上においてはRLHF(人間のフィードバックからの強化学習)が大きかった、と述べています。
RLHFについても別途深堀りしてみたいです。

GPTの歴史の表面をなぞっただけですが、多くの論文や技術革新があったことがわかります。
「GPTについて理解した」とは到底言えない状況、ということがわかりました(笑)。
今後このブログでは、技術的な部分にも焦点を当てながらゆっくりと紐解いて行きたいと思います。
不定期の更新になるかとは思いますが、ぜひフォローしてお待ちいただけると幸いです。