
【完全保存版】Metaplex Auraの全体フローについて

この記事は、こちらのGithubを翻訳・編集したものです。
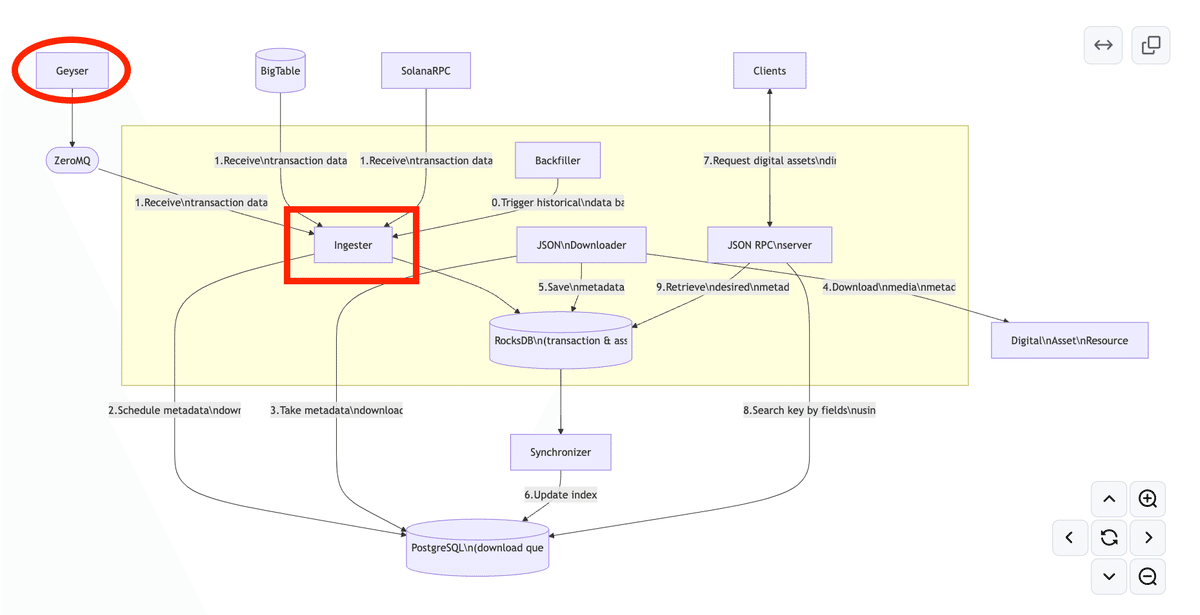
1 データ準備部分
1 トランザクションの取得
Ingesterメカニズムは、Geyserから新しいトランザクションを継続的に取得します。
それらはZeroMQ経由で送信します。
翻訳者注
そもそも、Ingesterとは「データを収集するプロセス」くらいの意味合いです。
翻訳者注
Geyserは、Solanaブロックチェーンのノードが持つプラグインシステムです。
ブロックチェーン上で発生するリアルタイムのデータを外部に送信・配信する機能を提供します。
同様の情報はSolana RPCノードやGoogle BigTableからも取得できます。

2 必要な情報のフィルタリング
Ingesterは取得したトランザクションをフィルタリングします。(メディア関連のレコードのみが対象)

それらをダウンロード用のタスクとしてPostgreSQLデータベースに保存します(PostgreSQLはキューとしても使用します)。
3 タスクの取得
その後、JsonDownloader(interface::json::JsonDownloader)がPostgreSQLの「キュー」から次のタスクを取り出します。

4 データの取得
JsonDownloaderは、実際にメディアアセットが保存されている場所からメディアのメタデータを取得します。
翻訳者注
それぞれのメタデータがどのURLに入っているのかを確認し、取得します。
5 データの保存
取得されたメタデータはRocksDBに保存されます。

6 インデックスの更新
Synchronizer(別プロセス)がPostgreSQLのインデックスを更新し、さまざまなメタデータフィールドでの検索を可能にします。

また、バックフィルメカニズムも存在し、既存のトランザクションのメタデータ(履歴データ)をロードするために使用されます。
補足
つまり、この仕組みが動き始める前の段階ですでにあったトランザクションについてですね。

2 データ検索部分
1 リクエストの送信
クライアント(エンドユーザーまたは他のサービス)は、検索したいフィールドを指定してJSON RPCエンドポイントにリクエストを送信します。

2 キーの検索
サーバーはまずPostgreSQLのインデックスにアクセスして、必要なレコードのIDを見つけます。

3 メタデータの取得
そのIDを使用して、サーバーはRocksDBから必要なメタデータを取得し、クライアントに返します。

いいなと思ったら応援しよう!
