
画像やビデオ内のオブジェクトをセグメント化するモデル「EVF-SAM2」を試してみる

EVF-SAM2とは
EVF-SAM はSAM2 とテキスト プロンプトを使用してビデオ内のオブジェクトをセグメント化してくれるモデルです。
いままでのSAMではできなかったけど、EVF-SAM2リリースによって精度高く可能になったということで試してみました!
🌐プロジェクトページ類
📸写真を試してみる

デモでは写真とビデオ両方試せるようになっていました。

ということでまずは写真から試してみたのがこれ。ちゃんと真ん中の笑顔の女性が撮れてます。まったく不安のない良い精度ですね!
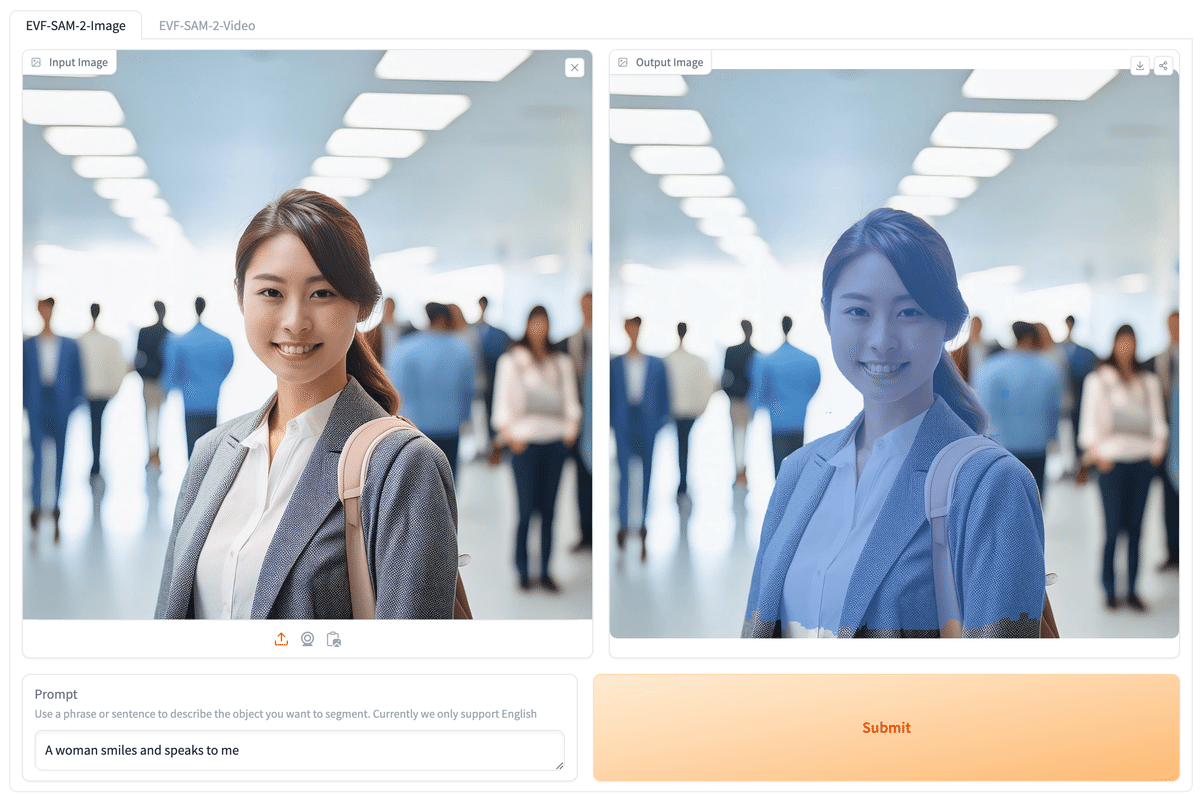

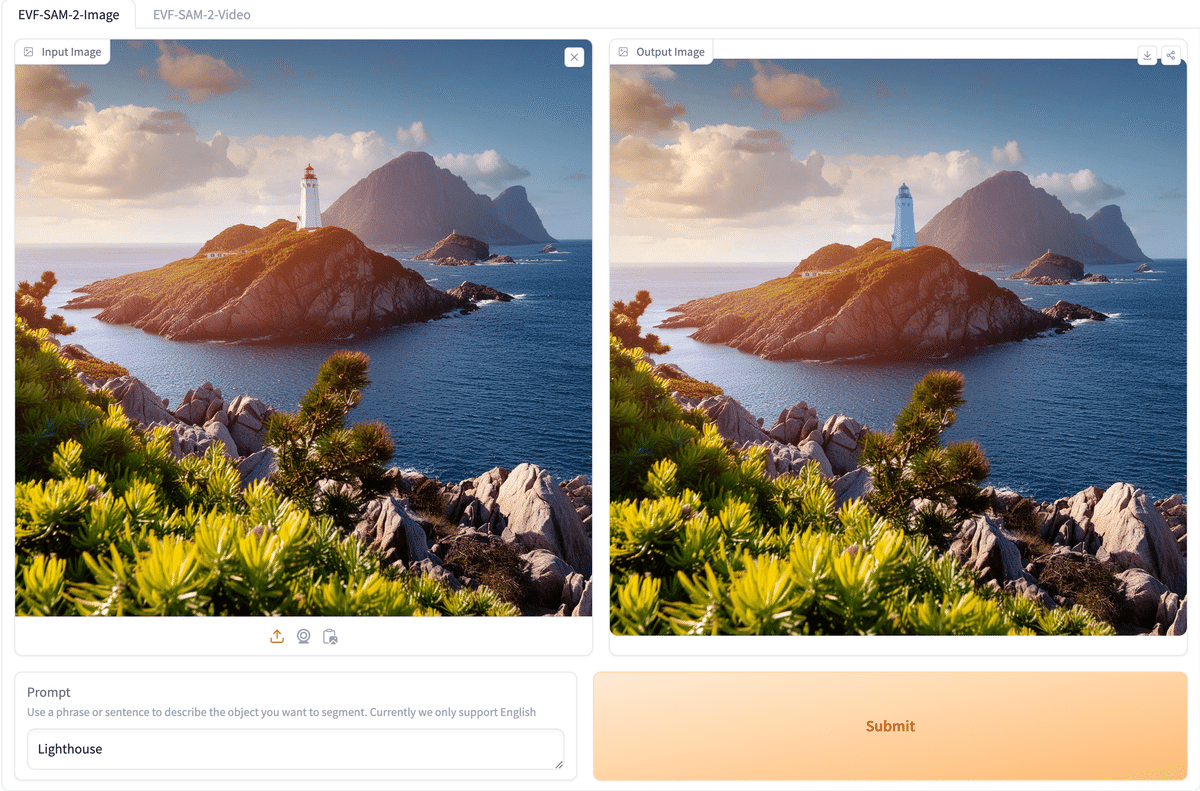

文章の捉え方や選び方もだいぶ洗練されている様子です。
📹ビデオを試してみる
動画の精度も変わらず良いですね!こちらも不安なし。
EVF-SAM-2お試し中。オブジェクト判定の精度良し✨ pic.twitter.com/EQmUY7El4e
— SUTO💡 (@st_e_ai) August 22, 2024
Xでも試した方の動画を見ていますが、いい感じです!
動画内のモノを切り抜ける「SAM-2」で、テキスト入力による指定が可能に!これで、人間が直接確認せずにAIが爆量処理できるようになったpic.twitter.com/5RUvMl1KFP
— ひろちゅ~ (@hirochuu8) August 22, 2024
SAM2 is a powerful and impressive work. We have expanded EVF-SAM. After a simple image training process, we found that EVF-SAM has zero-shot video text-prompted capability. The following videos were obtained with text prompts, i.e., "the man in black" and "the left elephant". pic.twitter.com/pJHlTPuHD0
— Tianheng Cheng (@tiahch) August 1, 2024
👀まとめ
通常SAMは画像の中から特定の部分を選び出すときにポイントやボックスを使ってそれを指示しますが、言葉を使った指示にはあまり対応していませんでした。
でもこのEVF-SAM2は画像とテキストの両方を使って指示を出すことで、SAMがより正確に画像を分けられるようにする方法にしています。
しかも、画像とテキストの情報がだいぶ早い段階で一緒に処理されるのでより的確に画像の中の特定の部分を見つけ出すことができるようになったとのこと。さらに従来の方法に比べて使うデータや計算量が少なくても高い精度を発揮する点も素晴らしいところです✨
本当、どんどん進歩していく技術とそれを公開してくださる技術者のみなさまのおかげで未来って作られていくんだな〜としみじみした今回でした。
今日はここまで〜!
この記事が気に入ったらサポートをしてみませんか?