⑬(ここをくりっく)

こんにちは。

こんかいは、
『文章からイメージ』を生成.
です。
上の絵は、
「黄色の体で、黒い羽を持ち、くちばしの短い鳥」
という文章から生成してます。
Microsoftさん、
文章からイメージを自動生成できる
AI技術を開発。
どうやってるの?
AttnGANを使ってます。
(ざっくり言うと)
AttnGANは、
入力テキストを
1つひとつの単語に分けて、
それらの単語を画像の特定の領域に
マッチング(Matching)させています。
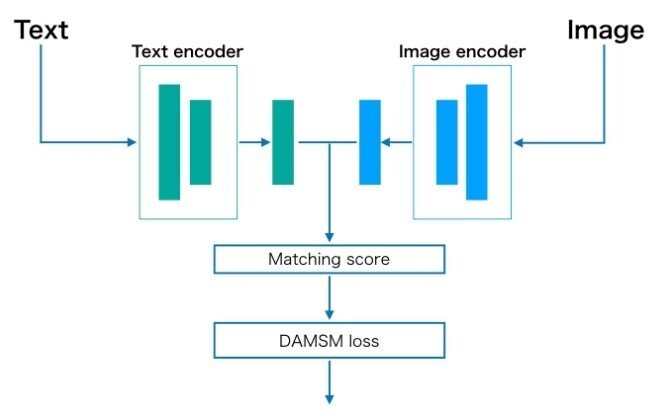
AttnGANでは、
「単語の意味」と,それに「対応する画像」を
おなじ特徴量空間にマッピングすることで
画像とテキスト間の類似度を
DAMSM
(Deep Attentional Multimodal Similarity Model)
を使って計算します。
DAMSMでは、
「単語の意味」と「画像中の小領域」を
紐づけるために
2つニューラルネットワークを使用して、
「言葉としての意味」と「画像」の類似度を
測定することで
損失関数(誤差関数)を算出します。

損失関数では、
損失がもっとも小さくなるパラメータ(特徴)を
探し出します。
ニューラルネットワークの学習では、
どれだけ答えに近い値になるか
パラメータを調整することが
メインになっていて、
この『答えに近い値になる』ための
指標となるのが
損失関数です。
これは、
「目標」と「実際」の出力の誤差を
表すことでもあり、
誤差関数とも言います。
Attention Modelでは、
画像中のこまかく区分けされた領域のうち
特定の単語と、
もっとも関連性の強い領域を描画します。

ことばの意味は?
・Text Encoder
「Bi-Directional LSTM」で,
テキスト特徴にエンコード(圧縮)
.
LSTMは、
前から順番に文字を読み込んで,
次に出てくる文字を予想します。
Bi-Directional LSTMは、
前と後ろから読んで,
次に出てくる文字を予想して、
双方向の時間軸から処理を行います。
→より高い認識率を実現。
・Image Encoder
CNN (Inception-v3)で,
画像特徴にエンコード(圧縮).
CNNは、
畳み込みニューラルネットワークのことで、
特徴をぬき出して、
小さくまとめる画像認識です。
Inception-v3では、
読み込まれた画像の中に、
なにが含まれているか判定できます。
Inception-v3 は、
深さが48層の
畳み込みニューラル ネットワーク(CNN)で
「ImageNet」データベースから読み込んでます。
ImageNetは、
1400万枚を超える画像と
その画像に写っている情報を分類して、
学習させたデータのまとまりです。
画像処理の学習では、
脳内の神経細胞(ニューロン)の
ネットワーク構成を類似した数学モデルを
使っています。
→ニューラルネットワーク。
ざっくり言うと、
たくさんの画像から,
物体の特徴を濃縮してまとめることです。
濃縮は、
たくさんの画像から,
特徴のある情報をだけを残して、
それ以外を消していく作業のことです。
・特徴量空間
1枚の画像は,
1つの「特徴量」で表現されます。
この「特徴量」で表現される空間が,
特徴量空間。
特徴量は、
処理対象の特徴をよく表す記号や
数値の組(特徴ベクトル)のこと。
→判別に必要なデータをコンパクトに
表現するものです。
たとえば、
「赤りんご」と「青りんご」を判別するために
必要な情報は“色”です。
“色”については,
ヒストグラムという形式がよく用いられます。
ヒストグラムは、
データの個数が,
どの値からどの値の範囲に、
どのように散らばっているかを
グラフにしたもの。
これを使って、
画像に含まれている1つひとつの
ピクセル(画素)の色を数えていって、
「赤」と「青」を判別してます。
Microsoftさん、

『じゃっかん、トリ.』でいい?
いいなと思ったら応援しよう!
