通話内容を AI で文字起こしする、準備編

この記事では核心である、AI を使うところまでは紹介していない。AI で取り扱うのに必要なデータを準備するところまで解説する。AI を使うところは次の記事で取り扱う。
近頃は連日、AI やら機械学習の話題を目にしない日はないというほど盛り上がっているように見える。
しかしまだ各社では研究段階といったフェイズであって、ビジネスに直結するような実用になっているケースはあまりないように感じる。もし、誰でも実感できるような実例があればメディアでも取り上げられるだろう。
AI、特に機械学習だと人力より明らかに得意な分野というのがわかってきて、画像認識、画像解析などのパターンを探し出すロジックは正確性が高く、処理速度も速いということで活用が期待される。
そんな中、うちの業務でも AI を活かせる分野はないかと模索しているが、「あったらいいな」ですぐに思いつくケースとして電話の「通話内容を文字起こしする」ことができないか、まずは「とりあえず動く」という状態を作ってみることにする。
音声の文字起こしというのは分野としては古くからあるもので、基本のロジックとしては AI や機械学習とは直接関係がない。しかし、これまでの文字起こしエンジンはチューニングを人力に頼っていたため、どうしても精度を高めることができず実用として使えるものではないレベルでしか動作しなかった。例えばカーナビで目的地を設定する、といった程度の短いセンテンスでしか利用することが想定できなかった。
ここに、機械学習を持ち込むことで大量のデータを扱うことで精度を上げていくことが期待でき、YouTube で動画に自動的に字幕を付与する、といったこれまでの文字起こしと比べて少し実用になりえるものが動き出そうとしている。もちろん、まだ精度の点では完璧ではないが、近いうちに人間が聞き取って書き出すのと遜色ない精度で動くことが期待できる。
各社の AIエンジン
音声の文字起こしとして使える各社の AIエンジンはいくつかの選択肢がある。ChatGPT で一躍注目された OpenAI社の Whisper、AWS の Amazon Transcribe など、メジャーなサービスを始め、業務用に特化したクラウドサービスなどもある。
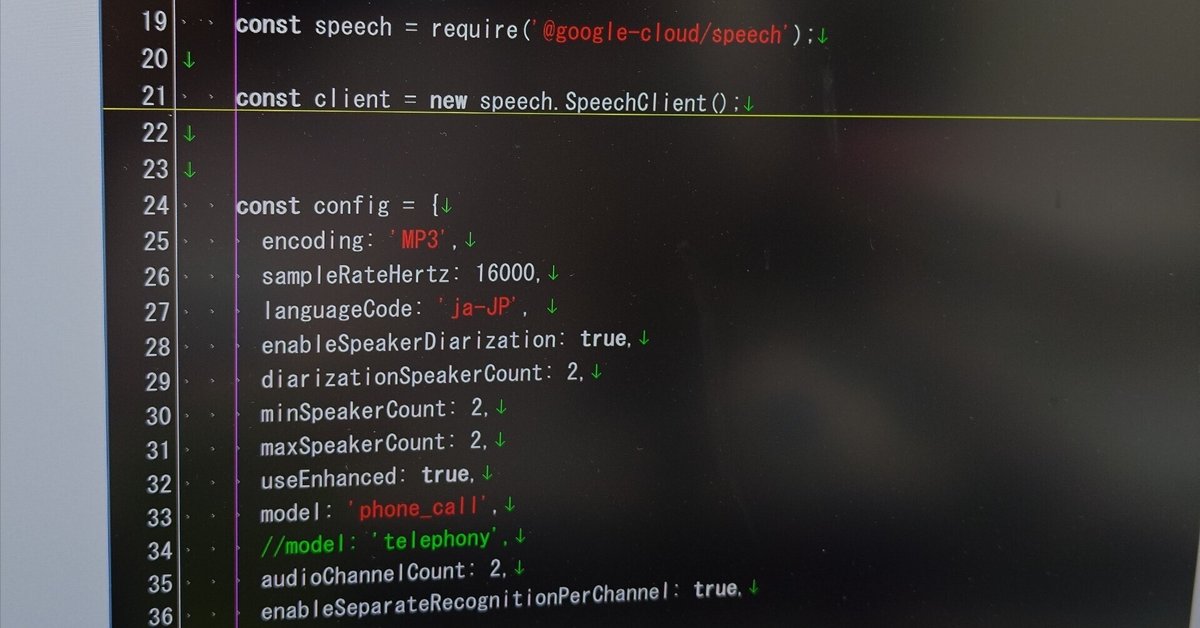
本来は精度や料金などを比較して選定すべきではあるが、今回は「とりあえず動く」ことが目標なので、これらの評価は省略して「API が使いやすい」という点で Google Cloud Speech-to-Text API を使うことにする。
Google では Google Cloud で提供するサービス群の中で、AI に関するエンジンは Vertex AI というブランドで提供し、この中には自社開発の AIエンジンである Gemini をはじめ、サードパーティ製AIモデルを用意してユーザが好きな AIモデルを共通のインタフェイスを介して使えるように整備している。
Google Cloud Speech-to-Text API もこの Vertex AI の一員ではあるものの、これはブランディング的な意味合いが強く、いまのところは Vertex AI であることを意識する必要はない。
2024年6月現在、Google Cloud Speech-to-Text API は v1、v1p1beta1、v2 が用意されている。もちろん、新規に開発されている v2 のほうができることが多く、利用料も安く設定されている。しかし、「日本語だけ」を取り扱えばよければいまのところ v1 がライブラリ類が充実しており、またドキュメントの整備状況、その他を勘案して使いやすいと思う。v1p1beta1 も試してみたが日本語に関しては精度の点で v1 に叶わず、v2 は利用方法が煩雑になるだけで精度の点でそこまでの差は感じられなかった。
なお利用料については計算方法などは Google Cloud の料金表を確認していただくのが確実だと思うが、2024年6月現在、v1 が $0.024/分、v2 が $0.016/分で解析対象の音声を秒数単位で積算して請求額が決まる。v1 に対しては初回$300 の無料クレジットが有効で、さらに毎月60分までの解析は請求対象から控除される。
本格的に稼働すると 60分あたり 230円前後($1 = 160円換算)と競合他社より単価は高く感じる設定になっているものの、実際に解析した音声の秒数に対してだけ課金される(無音部分や、無音トラックは排除される)ことなどを考慮するとこれくらいの単価が適正に感じる。
通話内容の抜き出し
音声データを用意して、それを Google Cloud Speech-to-Text API に解析させることろはサンプルコードそのままでも動くので敷居が低いものの、その前段である通話内容を抜き出すところがけっこう力技になる可能性がある。
うちの場合は幸い、電話関係はすべて自社開発の IP電話機(SIP電話機) で動かしており、そのコア(IP-PBX)は Asterisk で動かしているため Asterisk の Extension に次の設定を追加するだけで音声データを wav形式で保存して取得することができる。
Asterisk の設定例では、extensions.conf を使っている例が多いが、うちはすべて AEL に移行しており、extensions.ael に MixMonitor関数の行を追加する。
467 context incoming1 {
468 s => { jump _X.; };
472 _X. => {
486 Set(FILE=${STRFTIME(${EPOCH},JST-9,%Y-%m-%d_%H%M%S)});
487 Set(MONITOR_DIR=/var/spool/asterisk/monitor/);
489 MixMonitor(${FILE}-mix.wav, a t(${FILE}-out.wav16) r(${FILE}-in.wav16));不要な行を削除したので行数が飛んでいるが、incoming1 が着信したときに呼ばれる context で、_X. で宛先に関わらず処理が実行される。
486行目と 467行目で Set関数で変数をセットしている。これはファイル名に日付時刻データを使いたいからで、486行目が実行されることで、例えば 2024年6月5日 15時22分05秒であれば、2024-06-05_152205 という文字列が ${FILE} という変数に代入される。
MixMonitor関数が Asterisk で通話内容をファイルとして保存する機能を提供しており、拡張子を wav16 とすることでサンプリングレート 16kHz のファイル形式として保存される。wav を指定するとサンプリングレート 8kHz のファイル形式として保存される。一般的な電話回線ではコーデックの関係でサンプリングレート 8kHz 以上の音質は期待できないが、Opus などの高音質コーデックを使った通話を取り扱う場合、サンプリングレートを高く取っておいたほうが、このあとで行う Google Cloud Speech-to-Text API での認識精度が高くなる。(公式ドキュメントでも API に食わせる音声データは最低16kHz のサンプリングレートを担保すると良い、というヒントが書いてある)
t のファイル(-out.wav16) は transmit、つまり送話、こちらがわの音声を、r のファイル(-in.wav16) は receive、つまり受話、相手側の音声を意味し、それぞれ違うファイルとして保存しておく。送話と受話が混じってモノラルトラックに統合された音声は、-mix.wav として保存されるが、これは Google Cloud Speech-to-Text API に食わせるときに取り扱いづらいので使用しない。(通話内容を単に録音しておきたいだけ、といった場合はこのファイルだけでも良い)
通話をステレオトラックに統合する
このままだと、送話と受話で別のファイルになったままで取り扱いづらいため、これを統合してステレオファイルとし、この先の API での取り扱いも考慮して mp3形式に変換しておく。(API を叩くときに音声データを送る必要があるが、wav16形式のままではファイル容量が大きくなりすぎるため。mp3 に変換することでファイル容量を 9.6% くらい(1/10 程度)に抑えられる)
こういう音声ファイルの操作では、ffmpeg の利用が便利だが、今回は SoX を利用する。FreeBSD など Unix系で取り扱いやすい、コマンドベースで音声ファイルを編集できるツールで、ドキュメント類が参照しづらいものの、かなり高機能なのでけっこういろんなことができる。
2本のモノラルトラックのファイルを、それぞれ Lチャンネル、Rチャンネルのトラックとしてステレオトラックのファイルに統合するには、mergeオプションを使う。
% cd /var/spool/asterisk/monitor
% /usr/local/bin/sox \
-M \
2024-06-05_152205-out.wav16 \
2024-06-05_152205-in.wav16 \
2024-06-05_152205-stereo.mp3 normsox コマンドに、-M (merge) で 1トラック目、2トラック目、出力ファイルの順にファイル名を指定することで統合したファイルが作られる。最後の norm はオプションで、音声を正規化(小さすぎる音声をクリップしない範囲で大きくする処理)しているが、これはたぶん Google Cloud側でも事前処理でやっているので不要かもしれない。
このファイルを再生すると、相手の声が左から、自分の声が右から聞こえる。完全に分離したトラックで再生されるので気持ち悪く感じると思う。
(おまけ)人間が聞きやすいステレオトラックを作る
さきほどのファイルは API に食わせる目的で作ったものなので、完全に分離したトラックになっているが、人間が聞くことを考えるとチャンネル間のセパレーションを悪化させたほうが良い。完全に統合するのではなく、相手がちょっと左、自分がちょっと右、くらいに定位するようにする。
まずは、soxコマンドで、少しだけ他チャンネルが混じったトラックを用意する。
% /usr/local/bin/sox \
-m \
-v 1.0 2024-06-05_152205-out.wav16 \
-v 0.5 2024-06-05_152205-in.wav16 \
2024-06-05_152205-L.wavsox の -m (mix) で 1トラック目、2トラック目、出力ファイルの順にファイル名を指定することでモノラルトラックとして統合したファイルが作られる。
入力ファイルの前に、-v (volume) オプションを付けることで音量を調整する。-v 1.0 はそのまま(つけなくても同じ)で、-v 0.5 で 50% の音量になる。1.0以上の数字を指定することで、音量を上げることもできる。
同じように、逆の割合で混ぜたファイルも用意する。
% /usr/local/bin/sox \
-m \
-v 0.5 2024-06-05_152205-out.wav16 \
-v 1.0 2024-06-05_152205-in.wav16 \
2024-06-05_152205-R.wavあとは先程と同じように、この 2つのファイルを統合する。デフォルトでは、sox は mp3 を 128kbps のビットレートで生成するが、人間が聴くだけならここまでのビットレートは不要なので、ファイル容量を抑えるために 32kbps を指定しておく。
% /usr/local/bin/sox \
-M \
2024-06-05_152205-L.wav \
2024-06-05_152205-R.wav \
-C 32.1 \
2024-06-05_152205-stereo-32k.mp3出力ファイルの前の -C (compression) オプションで、32kbps、圧縮率高め(.1)を指定する。圧縮率は高め(.1) から低め(.9)で指定できる。
このファイルであれば左右のチャンネルが適度に混じっているので違和感なく聞こえると思う。
次回の記事で、今回準備した mp3ファイルを Google Cloud Speech-to-Text API に解析させる。