
BERTモデル完全ガイド:理論から応用までの詳細解説

こんにちは!こーたろー@データ分析の診療所 院長です。
今回は、Transfomerモデルを応用したBERTモデルについて考えて行きます!
前の記事で、大規模言語モデル(LLM)の歴史についても書いていますので、そちらもご覧ください。
Twitter: https://twitter.com/DsfKotaro

1. BERTモデルの概要
1.1 BERTの定義
BERT(Bidirectional Encoder Representations from Transformers)は、Googleが開発した自然言語処理(NLP)のための新しい手法です。BERTは、文脈を理解するために、文の両方向を同時に考慮することができます。これにより、BERTは文の意味をより正確に把握することができ、より高度なNLPタスクを実行することが可能になります。
1.2 BERTの起源と進化
BERTは、2018年にGoogleが発表しました。それ以前のNLPモデルは、文の一方向(左から右または右から左)しか考慮しなかったため、BERTの双方向性は大きな進歩となりました。BERTは、大量のテキストデータ(ウィキペディアなど)を学習し、その知識を新しいタスクに適用することができます。
2. BERTモデルの構成
BERTモデルの構成は以下のようになっています。
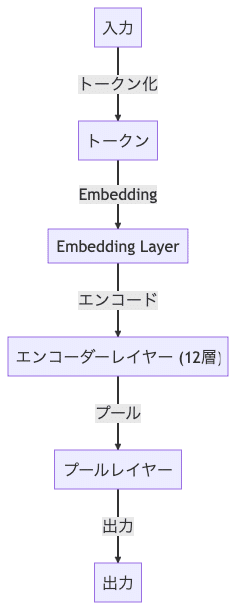
2.1 入力
BERTモデルの入力は、テキストデータです。このテキストデータは、トークン化され、各トークンはベクトルに変換されます。
2.2 トークン化
入力テキストは、トークン化されます。トークン化とは、テキストを単語やサブワードに分割することを指します。BERTは、WordPieceという方法を使用してトークン化を行います。
2.3 Embedding Layer
トークン化された各トークンは、Embedding Layerによってベクトルに変換されます。これにより、各トークンは高次元空間上の点として表現され、その位置はトークンの意味を表します。
2.4 エンコーダーレイヤー
BERTモデルの中心部分は、エンコーダーレイヤーです。BERTベースモデルでは、このエンコーダーレイヤーが12層あります。各エンコーダーレイヤーは、Transformerというアーキテクチャを使用しています。これにより、各トークンは、他のすべてのトークンの情報を考慮して更新されます。
2.5 プールレイヤー
エンコーダーレイヤーの出力は、プールレイヤーに送られます。プールレイヤーでは、最初のトークン([CLS]トークン)の出力が取り出され、これが全体のテキストの表現となります。
2.6 出力
最後に、プールレイヤーの出力は、特定のタスク(例えば、文章の分類や質問応答)に適した形に変換されます。これにより、BERTモデルは、様々なNLPタスクに対応することができます。
3. BERTモデルの特徴
3.1 BERTのメリット
BERTの最大のメリットは、その双方向性と文脈理解能力です。これにより、BERTは、文の意味をより正確に理解し、より複雑なNLPタスクを実行することができます。また、BERTは、大量のテキストデータを学習することができ、その知識を新しいタスクに適用することができます。
3.2 BERTのデメリット
一方、BERTのデメリットは、その計算量の多さと学習時間の長さです。BERTは、大量のテキストデータを学習するため、大量の計算リソースと時間が必要です。また、BERTは、モデルの解釈性が低いという問題もあります。つまり、BERTが特定の予測を行った理由を理解するのは難しいということです。
4. BERTモデルの応用例
4.1 自然言語処理(NLP)
BERTは、自然言語処理(NLP)の多くのタスクで使用されています。例えば、文章の意味の理解、感情分析、文章の生成などです。BERTの高度な文脈理解能力により、これらのタスクをより高い精度で実行することができます。
4.2 機械翻訳
BERTは、機械翻訳の分野でも活用されています。BERTの双方向性と文脈理解能力により、より正確な翻訳が可能になります。特に、異なる言語間のニュアンスを理解し、それを考慮に入れた翻訳を行うことができます。
5. BERTモデルの将来性
5.1 AIとBERT
BERTは、AIの分野で大きな影響を与えています。BERTの高度な文脈理解能力により、AIは人間のように文の意味を理解し、それに基づいた行動を取ることが可能になります。これにより、AIはより人間に近い形でのコミュニケーションが可能になり、AIの応用範囲が広がります。
5.2 BERTの進化の可能性
BERTは、今後も進化し続けると考えられています。特に、BERTの計算量の多さと学習時間の長さを解決するための研究が進められています。また、BERTの解釈性を向上させるための研究も行われています。これらの進歩により、BERTはより効率的で、より理解しやすいモデルになると期待されています。
6. BERTモデルのまとめ
6.1 BERTの重要性
BERTは、自然言語処理(NLP)の分野で革新的なモデルとなっています。その双方向性と文脈理解能力により、BERTは文の意味をより正確に理解し、より高度なNLPタスクを実行することが可能になります。これにより、BERTは、AIの分野で大きな影響を与えています。
6.2 BERTの今後の展望
BERTは、今後も進化し続けると考えられています。特に、BERTの計算量の多さと学習時間の長さを解決するための研究が進められています。また、BERTの解釈性を向上させるための研究も行われています。これらの進歩により、BERTはより効率的で、より理解しやすいモデルになると期待されています。
よくある質問
Q1: BERTとは何ですか?
A:BERT(Bidirectional Encoder Representations from Transformers)は、Googleが開発した自然言語処理(NLP)のための新しい手法です。BERTは、文脈を理解するために、文の両方向を同時に考慮することができます。
Q2: BERTのメリットとデメリットは何ですか?
A:BERTの最大のメリットは、その双方向性と文脈理解能力です。これにより、BERTは、文の意味をより正確に理解し、より複雑なNLPタスクを実行することができます。一方、BERTのデメリットは、その計算量の多さと学習時間の長さです。
Q3: BERTはどのように機能しますか?
A:BERTは、大量のテキストデータを学習し、その知識を新しいタスクに適用することができます。具体的には、BERTは、特定の単語やフレーズの意味を理解し、それを他の単語やフレーズと関連付ける役割を果たします。
Q4: BERTはどのような分野で使用できますか?
A:BERTは、自然言語処理(NLP)の多くのタスクで使用されています。例えば、文章の意味の理解、感情分析、文章の生成などです。また、BERTは、機械翻訳の分野でも活用されています。
Q5: BERTの将来はどうなると思いますか?
A:BERTは、今後も進化し続けると考えられています。特に、BERTの計算量の多さと学習時間の長さを解決するための研究が進められています。また、BERTの解釈性を向上させるための研究も行われています。
参考文献
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Google AI Blog: Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing