
【3分で完了】データ分析の始め方 -PythonとGoogle Colaboratory-

概要
この記事の目的 :Pythonでデータ分析をしてみたい人に最初の一歩を案内する
この記事の対象読者:Pythonを始めてみたいが何をすれば良いかわからない人
事前に必要な準備 :なし
---
Pythonをやってみたいけど何やっていいかわからないぞ、という人向けに、まずは1回体験することを目的として記事を作成しました。
ランダムな値を100個×2列記載した表を作り、それぞれのデータ分析結果(最大値や中央値など)を出力するプログラムを体験します。
やり方
以下の手順でデータ分析が完了します。
1.以下のURLをクリック(Googleのプログラムアプリ(無料)に飛びます)
※クリック後、Googleアカウントを所有している場合はログイン。所有していなければ作成する
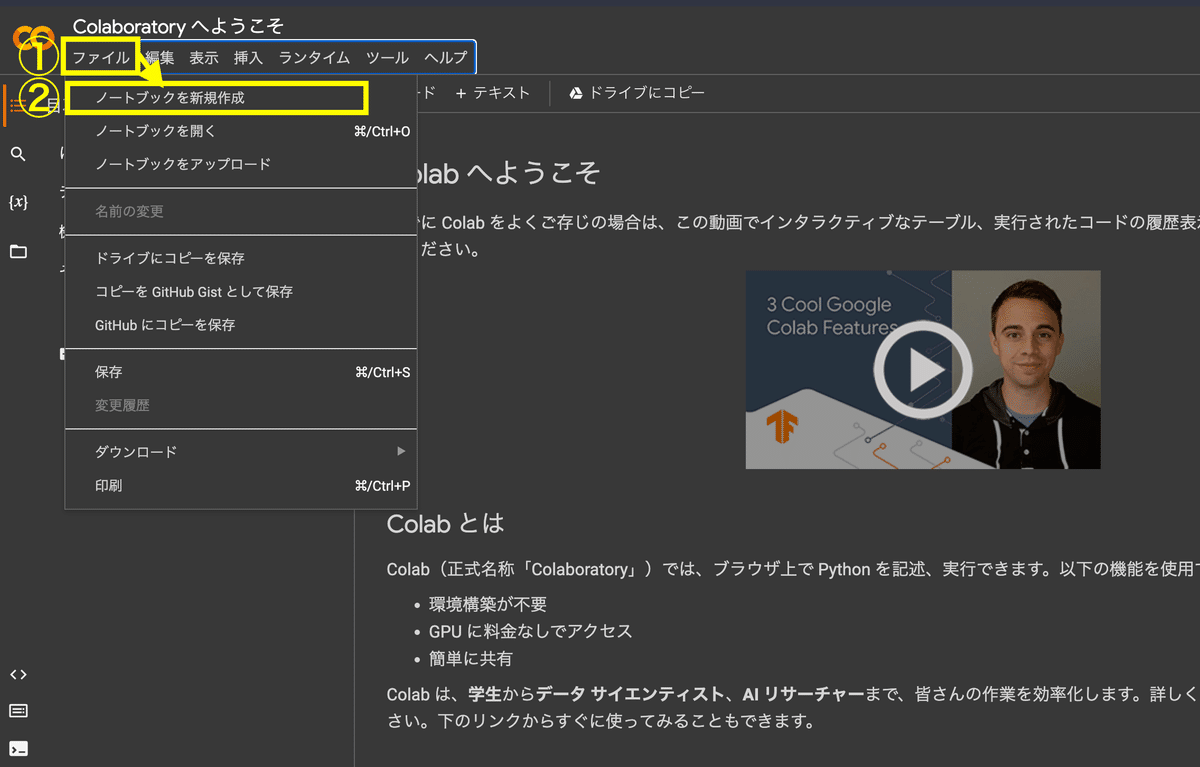
2.上部タブ「ファイル」→「ノートブックの新規作成」の順にクリック
※ポップアップが表示された場合も無視して「ファイル」ボタンを2回クリックすればOK(1回目のクリックでポップアップが消えます)
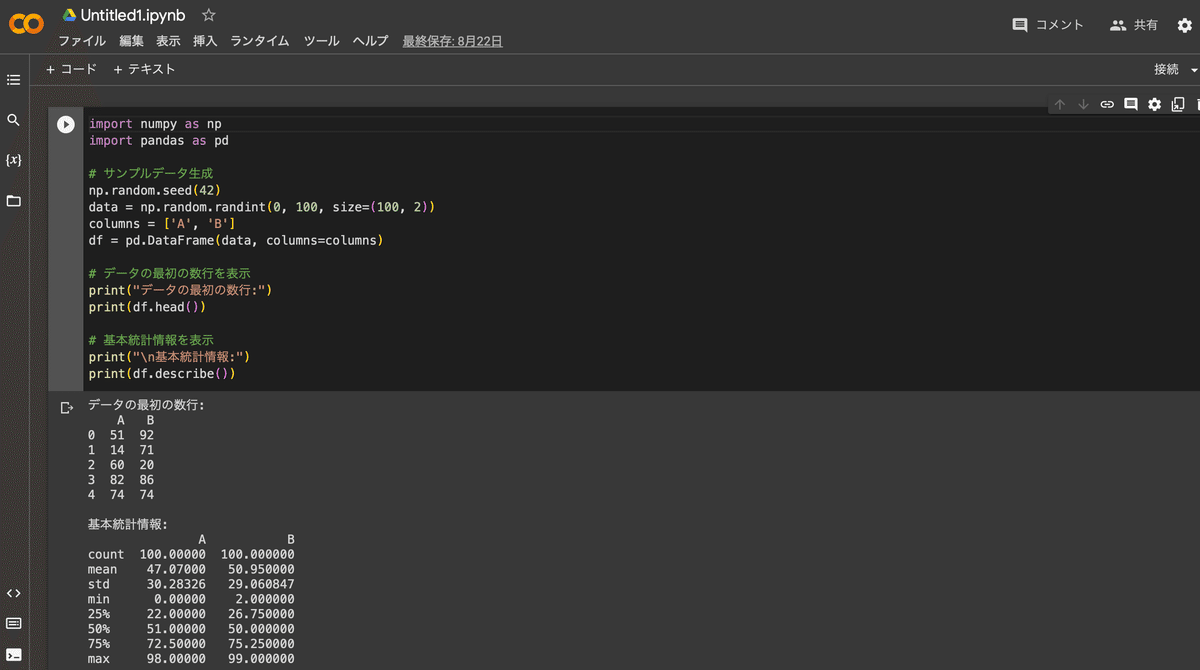
3.再生ボタン▶️の右にある①ブラックボックスに下のコードを全文コピペし、②再生ボタン▶️をクリック(10秒~30秒程度待ちます)

# コピペ用コード
# 分析に必要なPythonランタイム(便利機能)をダウンロードする
import numpy as np
import pandas as pd
# サンプルデータを自動で生成する
np.random.rand(100)
data = np.random.randint(0, 100, size=(100, 2))
columns = ['A', 'B']
df = pd.DataFrame(data, columns=columns)
# 生成したサンプルデータからランダムに3行を表示して確認する
print("ランダムに3行表示")
print(df.sample(3))
# 分析結果(サンプルデータの・・・データ数、平均、標準偏差、最小値、最大値など)を表示する
print("\n\n分析結果")
print(df.describe())
4.生成されたデータ一覧(ランダムに3行)と分析結果が表示される <完了>
<データ分析はこれで完了しました。以降の内容は解説と応用になります。不要な人はここで読み終えてください。>
1. はじめに
この記事では、PythonとGoogle Colaboratoryを使用して、分析結果を出力する方法を紹介します。分析は、ビジネス・プライベート問わず意思決定の協力な味方になります。
まずは実際にデータ分析を行ってみました。一度体験するとサンプルデータと出力データの設定を変更することで別の分析結果が出力可能なことが想像できると思います。
今回のコードの一部を変更することで簡単に外部データを取り込むことができるようになります。
今回は自動生成データを使用しましたが、早く外部のデータを使った分析をしたい、という方は「5.外部データの読み込みと分析」に進んでください。(後日別記事アップ予定)
2. PythonとGoogle Colaboratoryの紹介
Pythonは、データ分析や統計処理において広く使用されているプログラミング言語です。専門分野のライブラリ(よく使用する機能を集めた便利プログラム)が豊富にあります
今回利用したGoogle Colaboratoryは、ブラウザ上で使用できるプログラムの実行環境であり、今回のように「ちょっと実行したい」コードを実行するのに便利なツールです。
3. 今回使用したコードの解説
今回使用したコードの解説を行います。分析結果の出力方法を学ぶために、サンプルデータを生成して表示する、という手法で行いました。
numpyとpandasを使用して、ランダムなデータを生成し、数行を抽出して表示、および各種分析結果の表示を行っています。
①ライブラリ(便利機能)のダウンロード
# 分析に必要なPythonライブラリ(便利機能)をダウンロードする
import numpy as np
import pandas as pd ここでは、numpyおよびpandasライブラリをインストールしています。
numpyは数値計算を効率的に行うためのライブラリで、Pythonに標準でインストールされてはいないものの、とてもよく使われています。事実上の標準ライブラリとも言われています。
https://numpy.org/ja/
pandasはデータ操作や解析を行うためのライブラリです。
https://pandas.pydata.org ※日本語未対応
②サンプルデータの自動生成
# サンプルデータを自動で生成する
np.random.rand(100)
data = np.random.randint(0, 100, size=(100, 2))
columns = ['A', 'B']
df = pd.DataFrame(data, columns=columns)np.random.rand(100)では乱数生成の設定をしています。100個のランダムな数字を作っています。npは最初にインポートしたライブラリnumpyの略称です。以降のrandom.randで条件付きで乱数を生成しています。乱数の上限下限を設定したり、実行毎に数字が変わらないよう同じ値に固定する設定もできます。最後の(100)でデータの生成数を100個に指定しています。
data = np.random.randint(0, 100, size=(100, 2))ではdataに生成した乱数を格納しています。まず、np.random.randint()は指定した値内での乱数の作成を行います。(0, 100, で0から100までの範囲のランダムな整数データを生成し、size=(100, 2)は出力フォーマット、100行2列のデータを生成を指定しています。
columns = ['A', 'B']では先ほど生成した2列それぞれに「A」「B」という名前を設定します。
df = pd.DataFrame(data, columns=columns)では、先ほど生成したデータを元に、pandasで表を作成しています。pdは最初にインポートしたライブラリpandasの略称です。DataFrameで表を作成します。()内については、dataで先ほど生成した乱数を取得、上の行のcolumnsで指定された名前を各列に割り当てます。これにより、各列に「A」「B」と名前が付けられた表が作成されます。
③生成したデータの表示
# 生成したサンプルデータからランダムに3行を表示して確認する
print("ランダムに3行表示")
print(df.sample(3))print("ランダムに3行表示")では()内のテキストの表示を指示しています。実行結果で日本語が表示された部分がありましたが、このようにprintで指定しています。2行目のprintではdf.sample()を呼び出して表DataFrameからランダムに3行を表示します。(3)が表示する行数です。3を入力しなかった場合は1行のみ表示されます。
④分析結果の表示
# 分析結果(サンプルデータの・・・データ数、平均、標準偏差、最小値、最大値など)を表示する
print("\n\n分析結果")
print(df.describe())print("\n\n分析結果")もテキストの表示を指示しています。/nは改行です。今回は視認性向上のため2行改行したので、/n/nと2回入力していますprint(df.describe())ではdf.describe()でDataFrameから基本的な分析情報を計算・抽出し、printで分析情報、つまり各列のデータの個数、平均値、最大値、最小値などを表示します。
4. 今回の出力データの解説
ランダムに3行表示
A B
84 47 60
87 16 27
72 46 62
分析結果
A B
count 100.000000 100.000000
mean 54.930000 48.740000
std 29.074358 30.500743
min 2.000000 0.000000
25% 31.750000 23.500000
50% 59.000000 49.000000
75% 80.250000 78.250000
max 99.000000 99.000000※値は毎回変わります
①ランダムに3行表示
ここでは作成された100行2列のデータから、ランダムな3行を抽出し表示しています。1番左の列が行数、2番目の列がA列の値、3番目の列がB列の値です。
②分析結果
各値はそれぞれ以下の情報を表しています。
count:データの個数
mean:データの平均値
std:標準偏差
min:最小値
25% :四分位数(初めから(4/1=25%)に位置する値のことです)
50%:中央値
75%:四分位数(初めから(4/3=75%)に位置する値のことです)
max:最大値
5. 【応用】 外部データの読み込みと分析
<リンク>
別途記事作成予定
今回は自動生成の値を使用しましたが、通常は外部データを用いて分析をすることになると思います。
外部ファイルの事前準備等必要なため、別記事でアップします。
6. 【応用】 データ分析の拡張と応用
<リンク>
別途記事作成予定
データの可視化(グラフの作成など)、見せるための分析手法や、高度なデータ分析の手法に触れます。
7. まとめ
本記事では、PythonとGoogle Colaboratoryを使用してデータ分析を行い、結果を出力する方法を紹介しました。
次のステップとして、外部のデータを読み込んだ分析を行ったり、データの可視化に取り組むのがおすすめです。