
【3分で完了】データ分析の始め方 -試験結果データの取り込みと統計グラフ表示-

概要
この記事の目的 :Pythonでデータ分析をしてみたい人に任意のデータを取り込んでグラフを作成する方法を紹介する
この記事の対象読者:Pythonでデータ分析をしてみたいが何から始めれば良いかわからない人
事前に必要な準備 :なし
---
<前回の記事>
前回の続きですが、前回を見ていなくても問題ありません。今回は外部データの取り込みとグラフ表示を体験することを目的として記事を作成しました。
数学・英語のテストそれぞれ100人分のスコア(csvファイル形式)を用意しましたので、それらのデータを取り込み、スコア分布を表現するグラフを作成します。
やり方
以下の手順でデータ分析が完了します。
1.以下のファイルをダウンロード(テストのスコア100人分です)
※場所はどこでも良いです。後で使いますので場所を覚えておいてください
2.以下のURLをクリック(Googleのプログラムアプリ(無料)に飛びます)
※クリック後、Googleアカウントを所有している場合はログイン。所有していなければ作成する
3.上部タブ「ファイル」→「ノートブックの新規作成」の順にクリック
※ポップアップが表示された場合も無視して「ファイル」ボタンを2回クリックすればOK(1回目のクリックでポップアップが消えます)
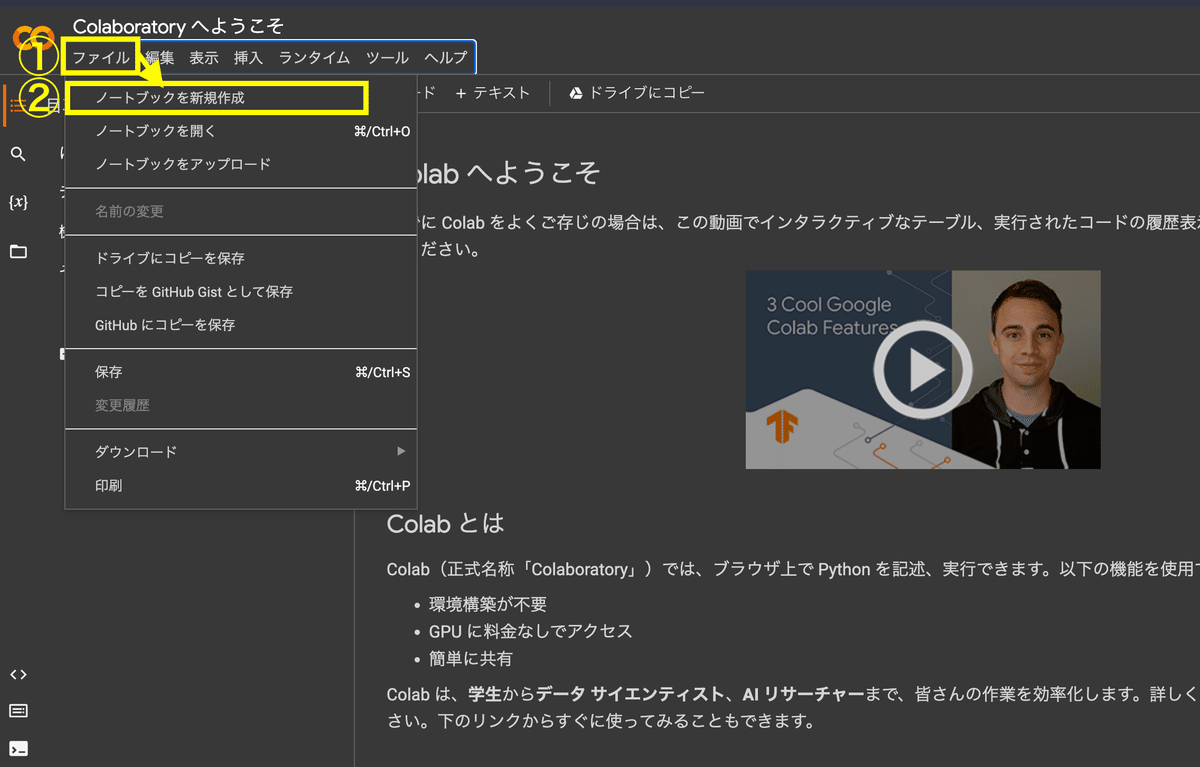
4.再生ボタン▶️の右にある①ブラックボックスに下のコードを全文コピペし、②再生ボタン▶️をクリック(10秒~30秒程度待ちます)

# コピペ用コード
# 必要なライブラリをダウンロードする
import matplotlib.pyplot as plt
import pandas as pd
from google.colab import files
# ファイルのアップロードボタンを表示する
uploaded = files.upload()
# アップロードしたファイルのタイトルを自動取得する
uploaded_file_name = list(uploaded.keys())[0]
# アップロードしたファイルのタイトルを指定してデータを取り込む
df = pd.read_csv(uploaded_file_name)
# グラフを作成して表示する
df.hist(bins=3, edgecolor='black')
plt.suptitle('Test Score Graph')5.「ファイルを選択」ボタンをクリックし、1.でダウンロードした「test_score_graph_source.csv」を選択しアップロード
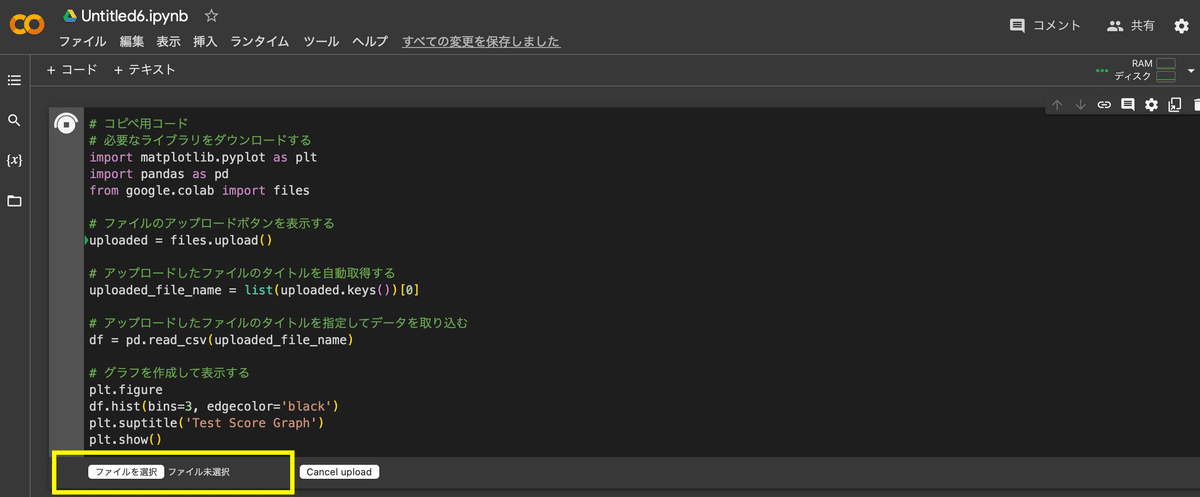
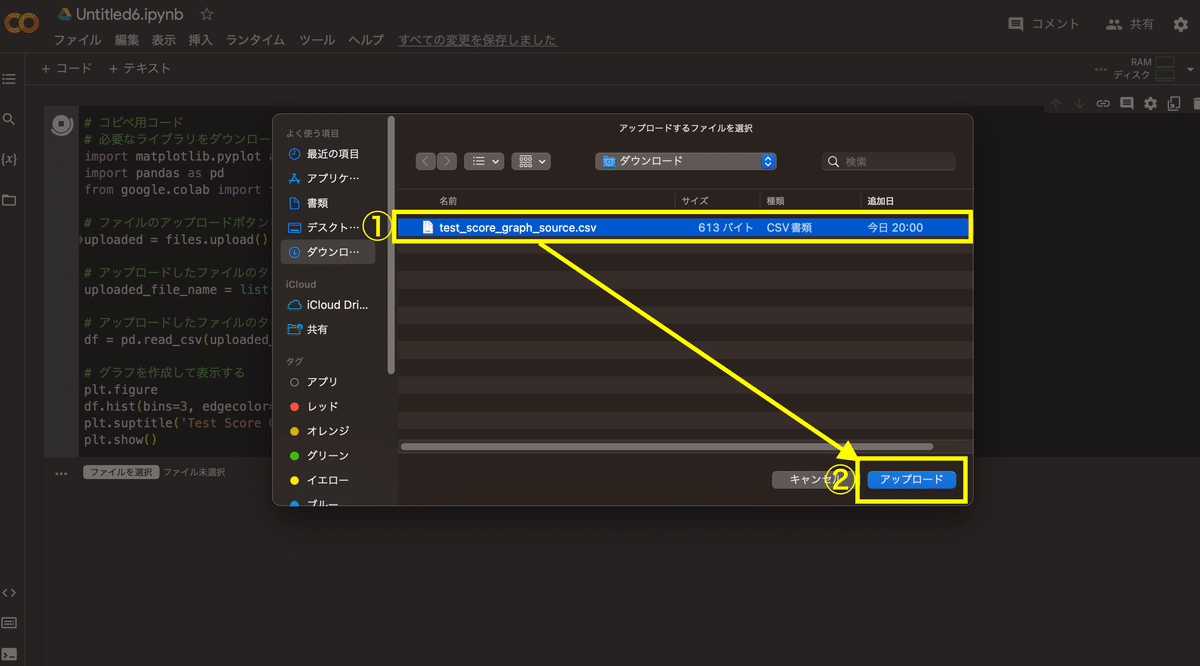
6.グラフが表示される <完了>
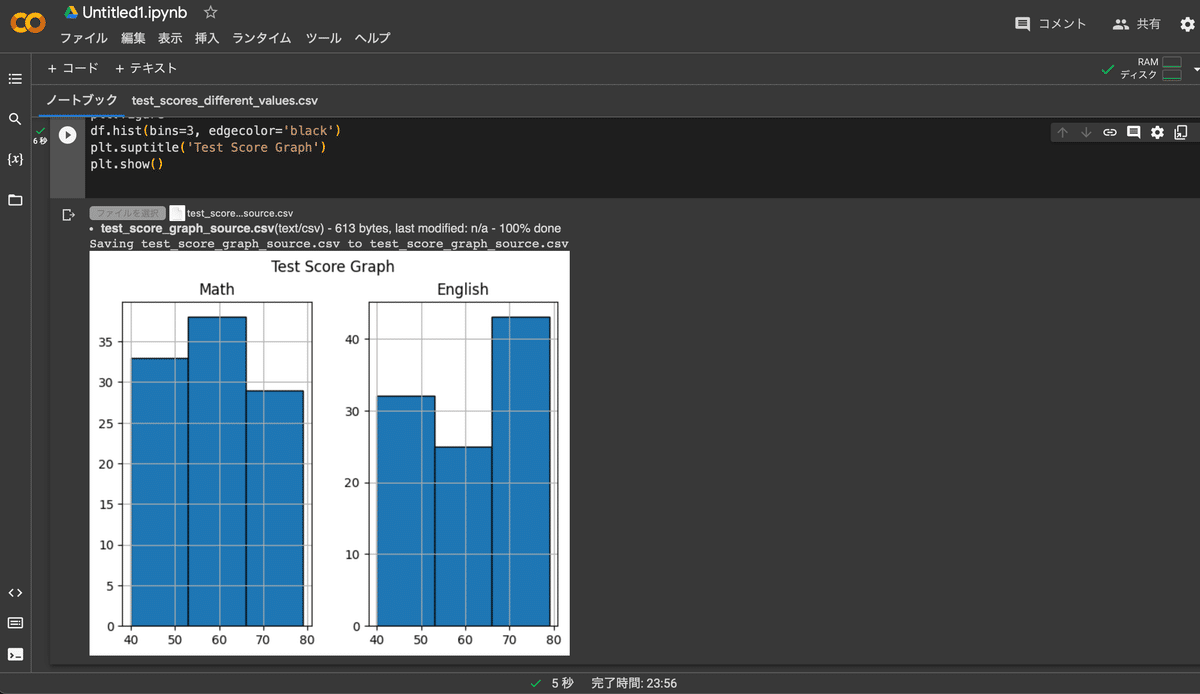
<外部データの取り込みおよびグラフの表示はこれで完了しました。以降の内容は解説と応用になります。不要な人はここで読み終えてください。>
1. はじめに
この記事では、PythonとGoogle Colaboratoryを使用して、外部データを使用したグラフ出力の方法を紹介します。
まずは実際にプログラムを実行しグラフを表示させました。一度体験するとサンプルデータと出力データの設定を変更することで別の内容やグラフを出力可能なことが想像できると思います。
2. PythonとGoogle Colaboratoryの紹介
重複するため前回の記事を参照
3. 今回使用したコードの解説
今回使用したコードの解説を行います。
matplotlib.pyplotとpandasを使用して、外部ファイルからデータを取り込み視覚化(グラフ表示)を行っています。
①ライブラリ(便利機能)のダウンロード
# コピペ用コード
# 必要なライブラリをダウンロードする
import matplotlib.pyplot as plt
import pandas as pd
from google.colab import filesここでは、matplotlib.pyplotおよびpandasライブラリをインストールしています。
matplotlib.pyplotは視覚化を効率的に行うためのライブラリとモジュールです。
matplotlibがライブラリ、pyplotはmatplotlibのモジュール(部品)であり、より簡単に視覚化を実行可能にします。
pandasはデータ操作や解析を行うためのライブラリです。
google.colab import filesはGoogle.colabのモジュールであるImport filesをインストールし、ファイルのアップロード機能を使えるようにしています。
②ファイルのアップロードボタンを表示する
# ファイルのアップロードボタンを表示する
uploaded = files.upload()この行でGoogleColabにデータファイルを取り込むボタンを表示するよう指示を出しています。アップロードされたファイルはuploaded変数(「uploaded」という名前のデータ保存場所)に格納されます。

③アップロードしたファイルのタイトルを自動取得
# アップロードしたファイルのタイトルを自動取得する
uploaded_file_name = list(uploaded.keys())[0]アップロードしたファイルのタイトルをuploaded_file_name変数に格納しています。list(uploaded.keys())[0]はアップロードしたファイルのタイトルの場所を示しています。
④アップロードしたファイルのタイトルを指定してデータを取り込む
# アップロードしたファイルのタイトルを指定してデータを取り込む
df = pd.read_csv(uploaded_file_name)
pd.read_csv()はpandasの機能の一つで、csv形式のファイルの読み込みに使用します。アップロードしたcsvファイルをデータフレーム形式(行列のあるExcelのような二次元の表)にしてdf変数に格納しています。(dfはdateframeの略)
データフレームについて詳細は以下のリンク先に詳しい記載があります。
⑤分析結果の表示
# グラフを作成して表示する
df.hist(bins=3, edgecolor='black')
plt.suptitle('Test Score Graph')df.hist(bins=3, edgecolor='black')ではdf変数に格納したcsvファイルの内容をヒストグラムにして表示しています。.hist()はpandasライブラリの機能で、ファイル内の値の分布をヒストグラムにします。binsはグラフに表示する柱の数を、edgecolorは柱の境界線の色を指定しています。
plt.suptitle('Test Score Graph')ではMatplotlibライブラリの機能suptitleを使用し、グラフのタイトルを「'Test Score Graph'」に設定しています。
4. 今回の出力データの解説
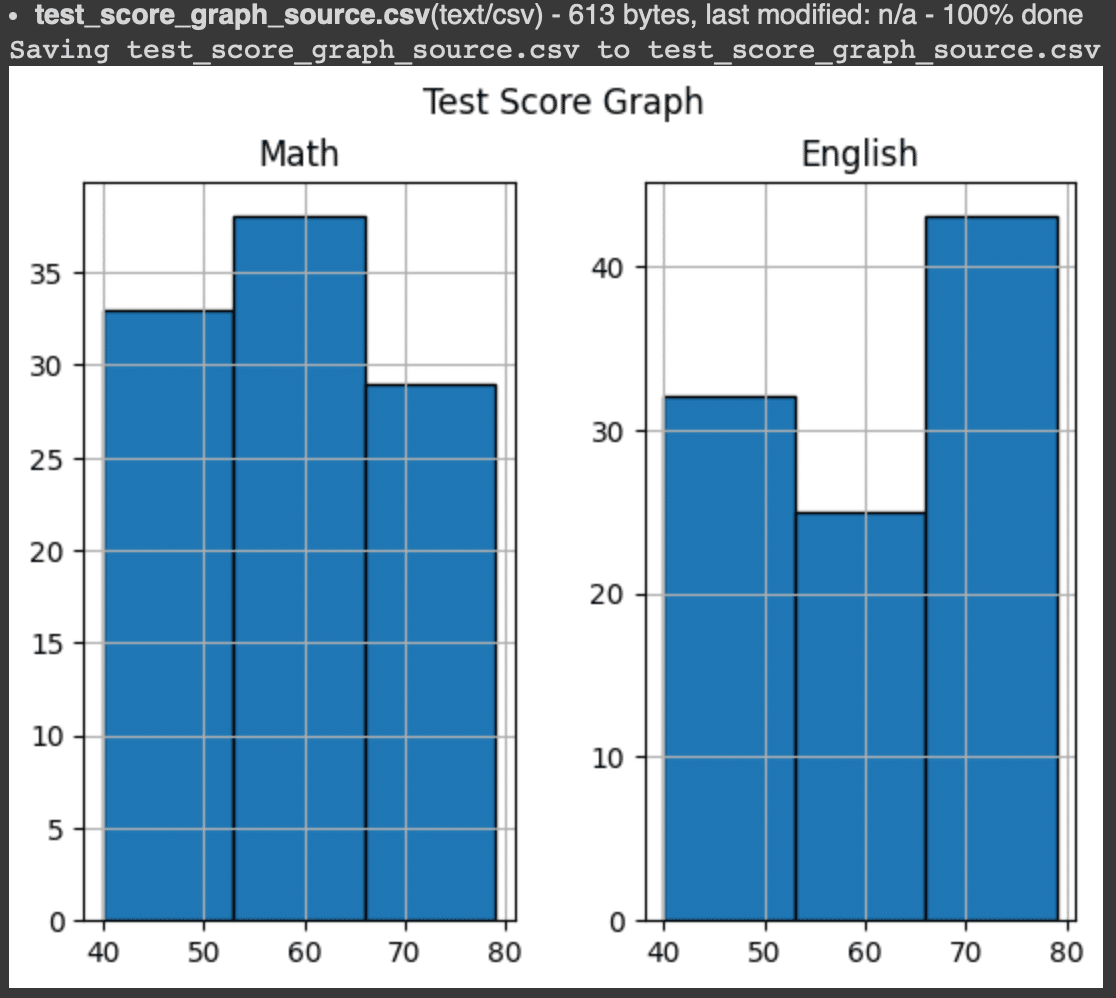
①グラフ表示
今回はヒストグラムを使用しました。例えばplt.histの部分をplt.pie()にして使用すれば円グラフ、plt.plot()にして使用すれば折れ線グラフなどカスタマイズが可能です。その場合は設定する値がbinではなくなるため、以下のような詳しく記載されたページを参考にして調整後に試してみてください。
②分析結果
各値はそれぞれ以下の情報を表しています。
縦軸:Math、Englishの点数(100点満点)
横軸:テストを受けた人数
柱の値(bin)を3本に設定した理由として、
「今回のテストは英語より数学の方が難しかった」ことを主張するために、
「英語の点数は高得点の領域に分布が多く、数学の点数は中間の領域に分布が多い」ことがより伝わるように意識しています。
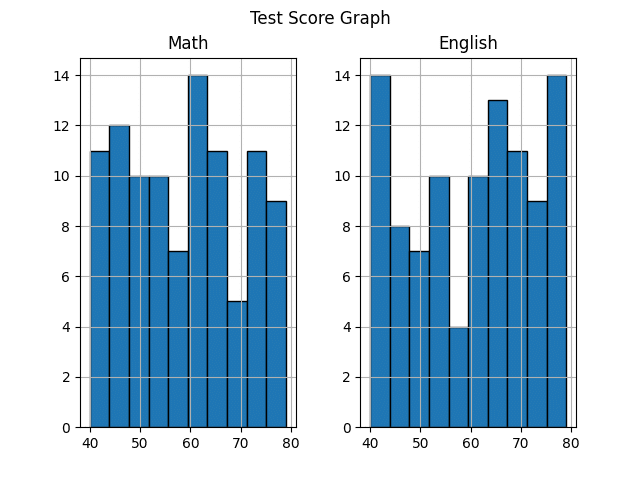
参考まで柱の設定を10本にした場合の画像を載せておきます。詳しくはなりましたが、上記の主張したいことが3本のときよりも伝わりにくいグラフになったことがわかると思います。
5. 【応用】 データ分析の拡張と応用
<リンク>
別途記事作成予定
データの可視化(グラフの作成など)、見せるための分析手法や、高度なデータ分析の手法に触れます。
6. まとめ
本記事では、PythonとGoogle Colaboratoryを使用して外部データの取り込みとグラフ表示を行う方法を紹介しました。
次のステップとして、他のデータを読み込めるようコードを変更してみたり、別のグラフ表示をしてみるのがおすすめです。
現在のコードのままでも、列や行を変更したデータを使えば別の結果を表示することが可能ですので色々試して見てください。参考までに、列を3列、行を200行に変更したサンプルデータも載せておきます。