
Whisper(v3, distil)やVoskを超簡単に試せるデスクトップアプリ爆誕!

音声認識まわりで有名なWhisper(v3, distil)やVoskを活用し、リアルタイムな文字起こしアプリケーションを作ってみました!
OpenAI社のAPIも使えるので、高速な文字起こしに加え、AIとのチャット体験も可能です。
背景
AIがどんどん進歩していく中、OSSでこんなことまでできるんだ!という身近な体験を作りたいと考えたときに、まずは音声認識かなと思ったのが開発のキッカケです。調べていくとPythonを使ったスクリプトベースの事例は多くありましたが、アプリケーションに組み込む事例は少なかったのでお話したいと思っています。
技術選定
アプリケーションフレームワーク
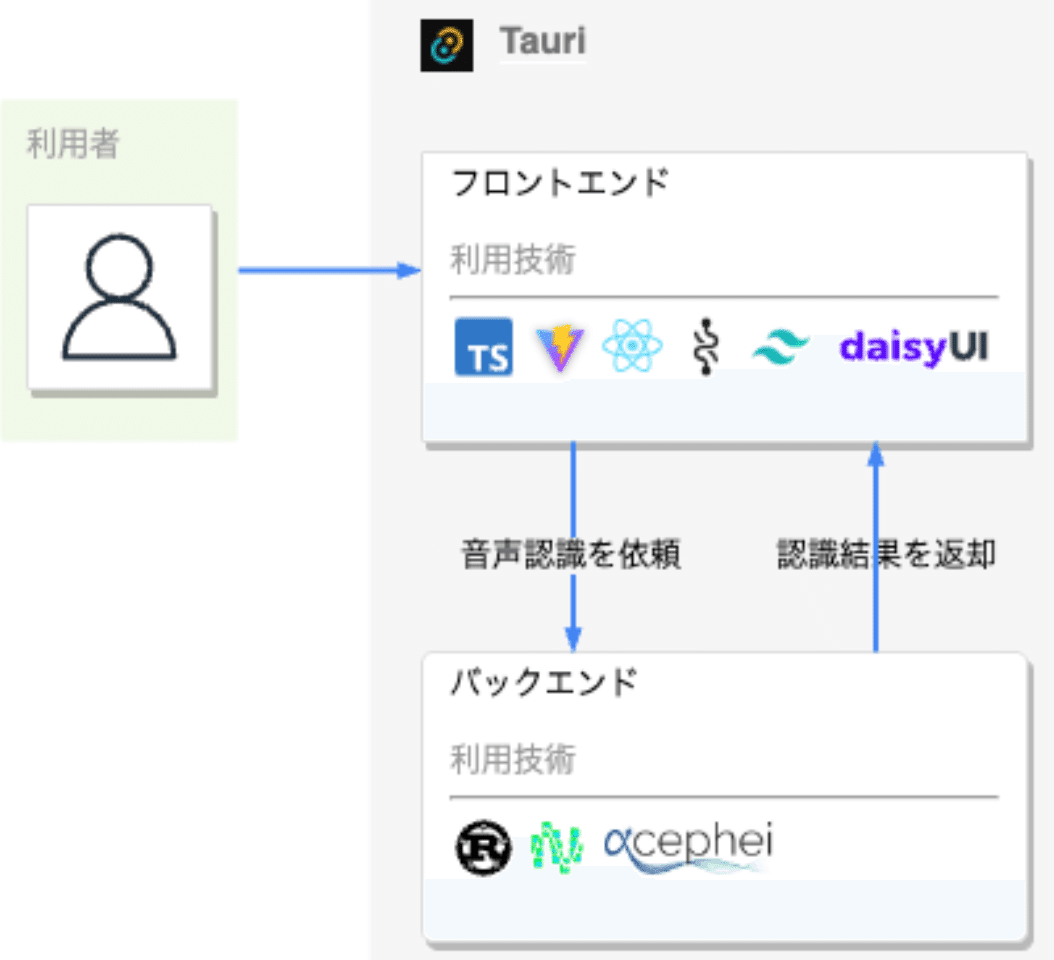
デスクトップアプリケーションを作るにあたり、Tauriというフロント部分はWEB技術、バックエンド部分をRustで記述できるフレームワークを採用しました。Electronも選択肢にはあったのですが、音声認識まわりはネイティブな処理が多いため、相性が良いRustが使えるというのが決め手でした。
音声認識技術
2つの音声認識技術を同時に使って、リアルタイムな文字起こしを実現しました。Whisperだとどうしてもラグが発生してしまうため、ラグが短いVoskでリアルタイムな文字起こしを実現しつつ、話者の会話の区切りを認識。その区切りごとにWhisperを利用して、Voskの認識結果を高精度なものに置換させるというステップを踏んでおります。
Whisper
皆さんご存知のOpenAI社の音声認識ライブラリです。複数のモデルがあり、容量の大きいものほど高精度です。直近容量の大きいLargeモデルのv3が発表されて話題になりました。
今回は、C++実装で最適化されているggerganov氏の下記ライブラリを採用しました。
CPUだけでも動作する素晴らしいライブラリですが、MacのCoreMLにも対応しており、作成したアプリケーションもApple Silicon(M1,2,3)対応のものは、CoreMLで動作します。※ 私も陰ながらCoreML対応のLargeモデルのv3をアップロードするなど貢献しております。
Rustで記述するにあたり、下記Rust bindingsを実際には利用しています。
Vosk
Whisperが出てくる前?に話題になっていたAlpha Cephei社のオフラインのリアルタイム音声認識ライブラリです。
多くの言語モデルが簡単に利用できるようになっており、文字起こしを高速にリアルタイムで行えるのが魅力です。
こちらもRustで記述するにあたり、下記Rust bindingsを実際には利用しています。
システム構成図
使い方
1. Booth上のファイルをダウンロードして解凍すると、インストーラが起動するのでドラッグ・アンド・ドロップでインストールしてください
2. インストール後、上部メニュー右の歯車(設定)をクリックします

3. 設定内で、認識したい言語(話し手の言語)の言語パックをダウンロードします
この言語パックはVoskのモデルがダウンロードされます。
今回はVoskで利用できる日本語モデルの高精度のものをダウンロードしたいと思います。(しばらく時間がかかりますが、ダウンロード済という表記に変わるまでお待ち下さい)

4. オフラインで追っかけ認識/翻訳する場合は、同じく設定内で、認識したい精度レベルの言語パックをダウンロードします。
こちらはWhisperのモデルがダウンロードされます。汎用の低、中、高が、WhisperのSmall、Medium、Large v3に対応しており、英語:高は、distilモデルのLarge v2に対応しています。(こちらも時間がかかりますが、ダウンロード済という表記に変わるまでお待ち下さい)

5. オンラインで追っかけ認識/翻訳する場合は、同じく設定内で、OpenAI社のAPIキーを入力します。
オンライン上のWhisperを利用する場合や、各種GPTモデルと対話する場合にはAPIキーを入力してください。

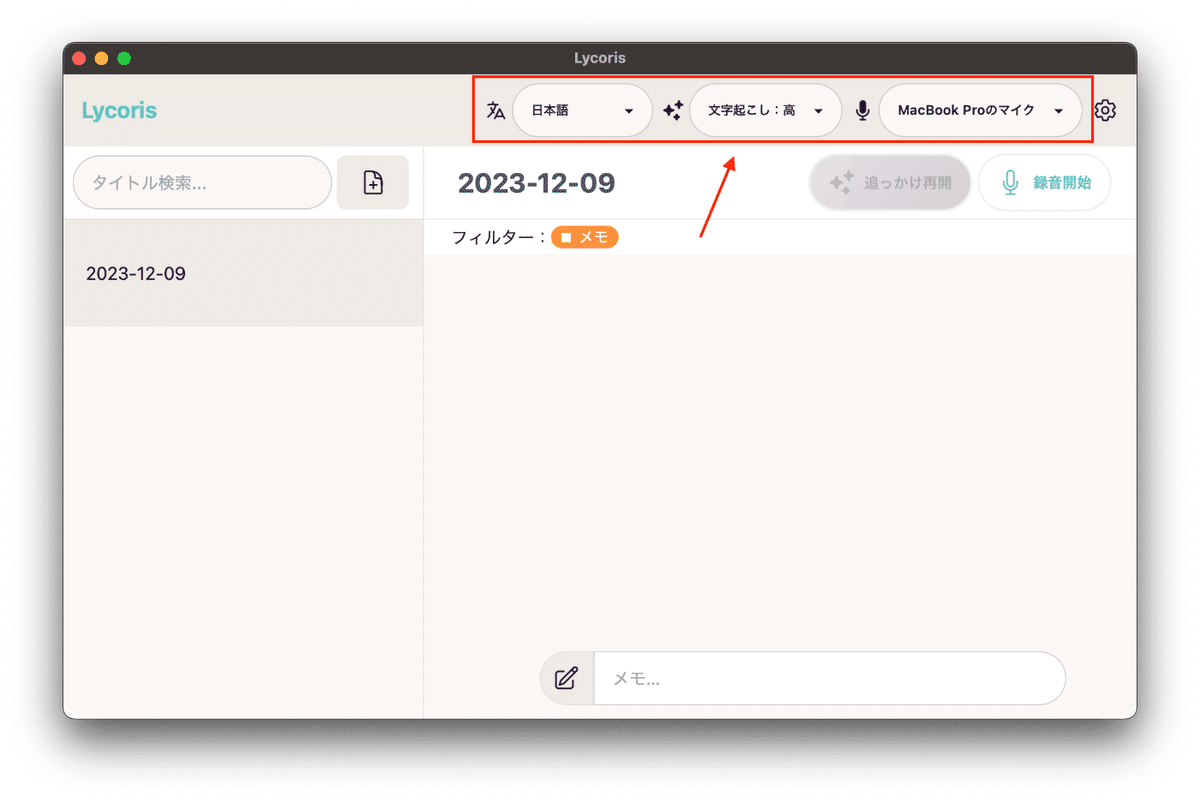
6. 左上部の検索窓横のノート追加ボタンから、ノートを追加します。

7. 上部メニューの『話し手の言語』、『追っかけ設定』、『利用するマイク』を設定すると、ノート内で録音開始ボタンが押せるようになります。
苦労した点
Macアプリ開発素人編
1. 利用する機能の権限設定
Macアプリがネイティブな機能を利用するには、Info.plistという設定ファイルに使用する権限を記載する必要があり、初めての対応だったので苦戦しました。
2. アプリのユーザー負担のないインストール
アプリストアで配布しないアプリは、Macのセキュリティでブロックされるため、ユーザー自身がセキュリティ設定でアプリを許可する必要があります。私はこの手順をユーザーにさせたくなかっため、AppleDeveloperProgramに課金し、別途アプリのAppleの認証(公証)を行いました。普段アプリ開発をしないので、AppleDeveloperProgramの年間$99の負担は結構重かったです。。。
3. Appleの認証(公証)
公証する際にも、使用する権限をentitlements.plistという設定ファイルに記載する必要があり、同じく初めての対応だったので苦戦しました。Info.plistとは別権限名であり、またAppStoreに公開する場合も別権限名なのでややこしいこと、この上なかったです;;
ネイティブ素人編
1. ライブラリのアプリへのバンドル準備
Voskのlibvosk.dylibを利用するにあたり、dylibには自身の場所が書き込まれているので、アプリにバンドルする場合は、アプリ実行時に自身の場所を教えてもらえるよう@rpathとする必要がありました。
2. ライブラリのアプリ実行時のリンク設定
アプリ実行時に、@executable_pathで実行場所を取得し、dylibにリンクする必要がありました。
3. ライブラリの公証
Macアプリ開発素人編で紹介した公証では、dylibについても署名があることが必須要件となっています。実はTauriアプリケーションを簡単にビルドできるGithubAction(tauri-action)を利用すると、簡単に公証できるのですが、Tauriアプリ本体のみにしか対応していなかったので、codesignコマンドで別途署名する必要がありました。
その他の機能
AIとのチャット機能
OpenAI社のAPIキーと、利用モデル(gpt-3.5-turbo、gpt-3.5-turbo-1106、gpt-4、gpt-4-1106-preview)、発話有無(Macのsayコマンドを利用)を設定することで、ノート上でAIと対話が可能となります。

もちろん、AIにどんな役割をしてもらいたいか入力できます。

AI入出力のシステム取得
OpenAI社のChatCompletionAPIとのやりとりの前後に、システム的な処理を挟むことができます。
発話ベースのチャットアプリを作りたいんだけど、どんな体験になるのか事前に試したいというときに活用できます。
ChatCompletionAPIへのリクエスト前
事前にAIに渡したい情報をcurlコマンドなどで、取得しておくといった使い方が可能です。

ChatCompletionAPIへのリクエスト後
AIとのやりとりの結果をテキストファイルに保存したり、自身のシステムに受け渡したりといった使い方が可能です。

FunctionCallingの利用
上記処理において、OpenAI社のAPI仕様であるFunctionCallingも活用可能です。

まとめ
ローカルでの音声認識技術が個人の開発者にとってもかなり身近なものとなったと、しみじみと感じるアプリケーション開発となりました。これからは、さらにAIもどんどん身近なものになっていくのでしょう。
また、無料でGPT-4と会話できるSNSも作ってみたので、良かったらこちらも触ってみてください><
AIで人々の暮らしをより便利に!シンプルにしたい!
よりAIが溶け込んだ未来になると楽しいなと妄想し、日々実現に向けて色んなことにチャレンジしていく所存です。