
【第2回】エクセル(パワークエリ)を使ったデータ分析業務入門~第2回~

【前回記事】では政府発行の祝日データCSVを参考ファイルとして、エクセル(パワークエリ)で外部データを読み込む方法を解説しました。
しかし、世の中のデータはもっと「雑」なCSVで溢れていますので、今回はもう少し複雑なデータを参考にパワークエリのより詳しい使い方を解説いたします。
今回の参考データは国勢調査の人口速報集計になります。
サイトはこちら
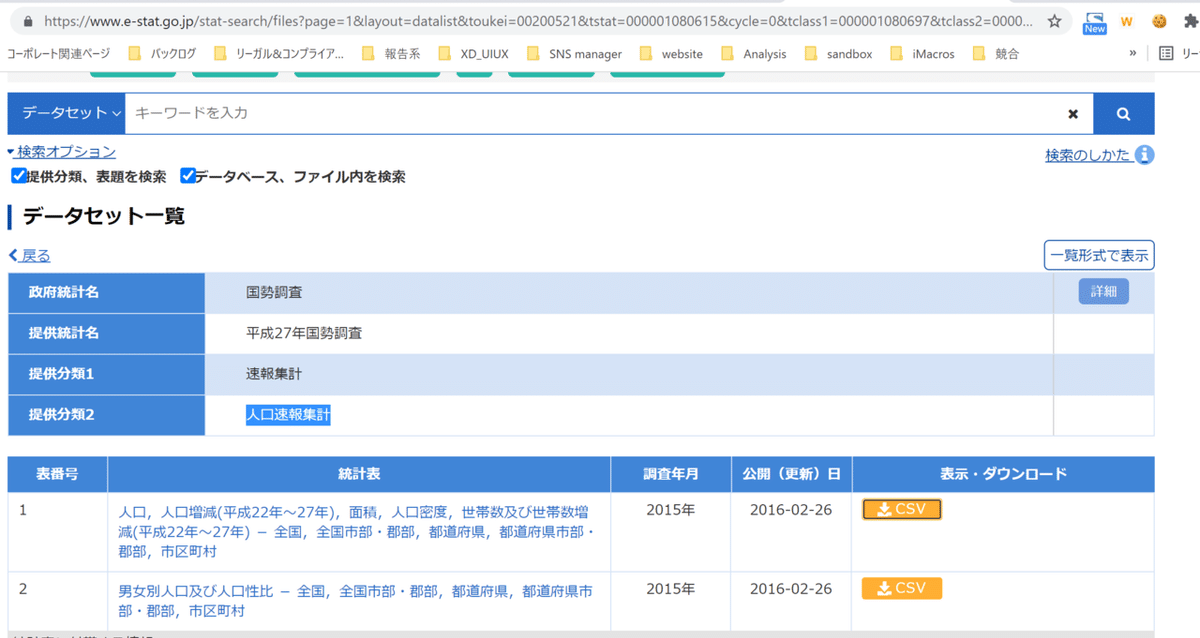
まずは前回同様「Webから読み込む」でデータを読んでみましょう。
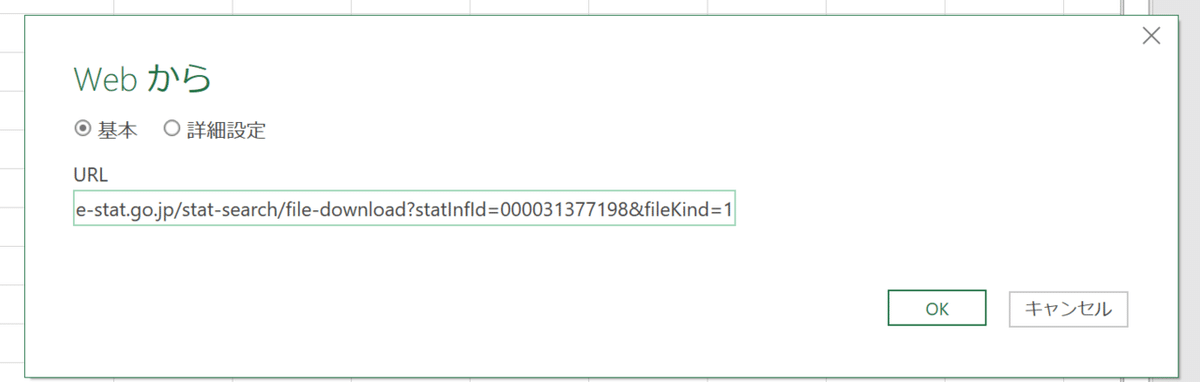
今回は見事に文字化けしましたね。
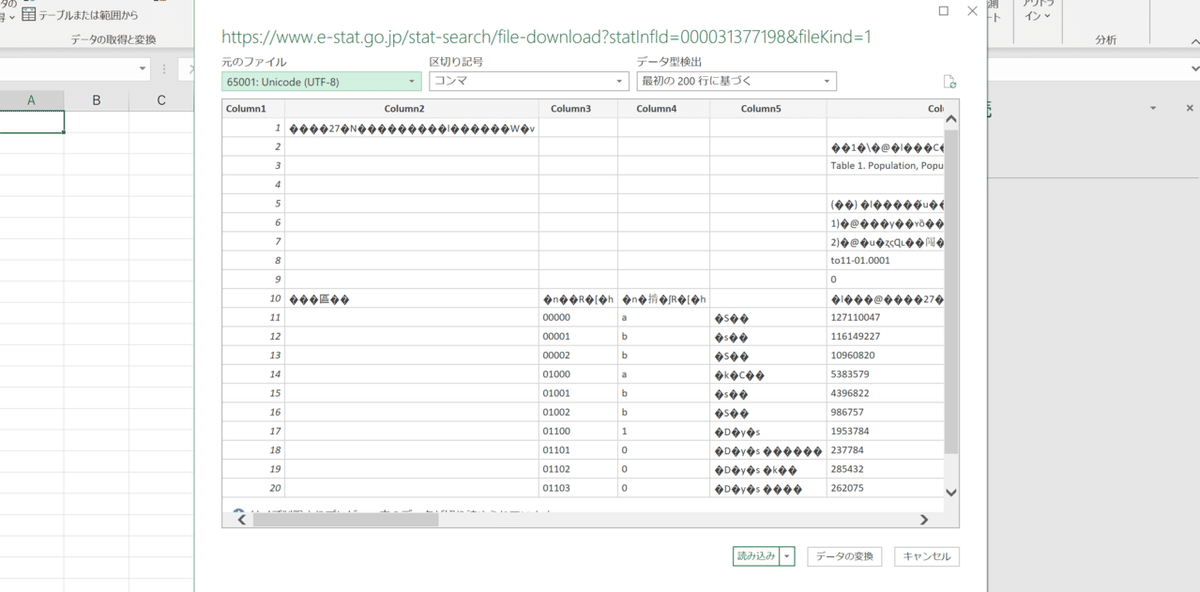
文字コードをシフトJISにしてあげましょう。区切り記号はコンマのままで大丈夫です。これでまずは読める形にはなりました。しかしよく見るとこのCSVは「実際のデータの上になんかいろいろ解説した行がある」ということがわかります。そのため、テーブルの見出しも「column1」などになっていて、読み込むデータの型も正しく検出されてませんね。
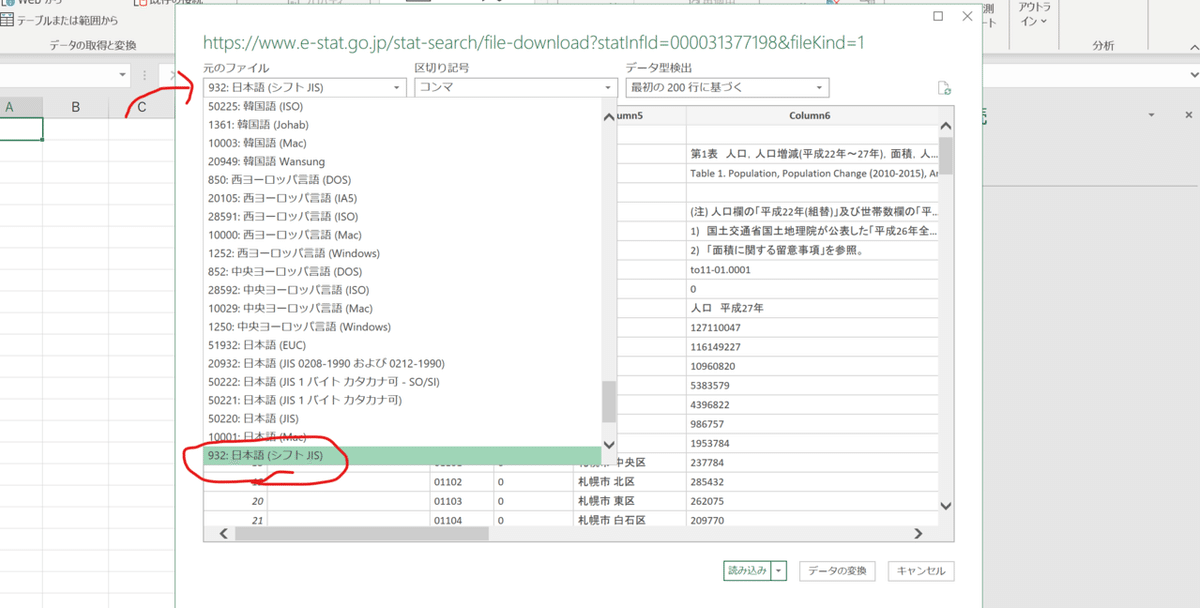
という事で、不要な上位10行を削除したり、見出し設定をしたりと、実際のデータ型を合わせていくような「データ整形」をします。
では「データの変換」ボタンを押しましょう。以下のような画面が開きましたか?
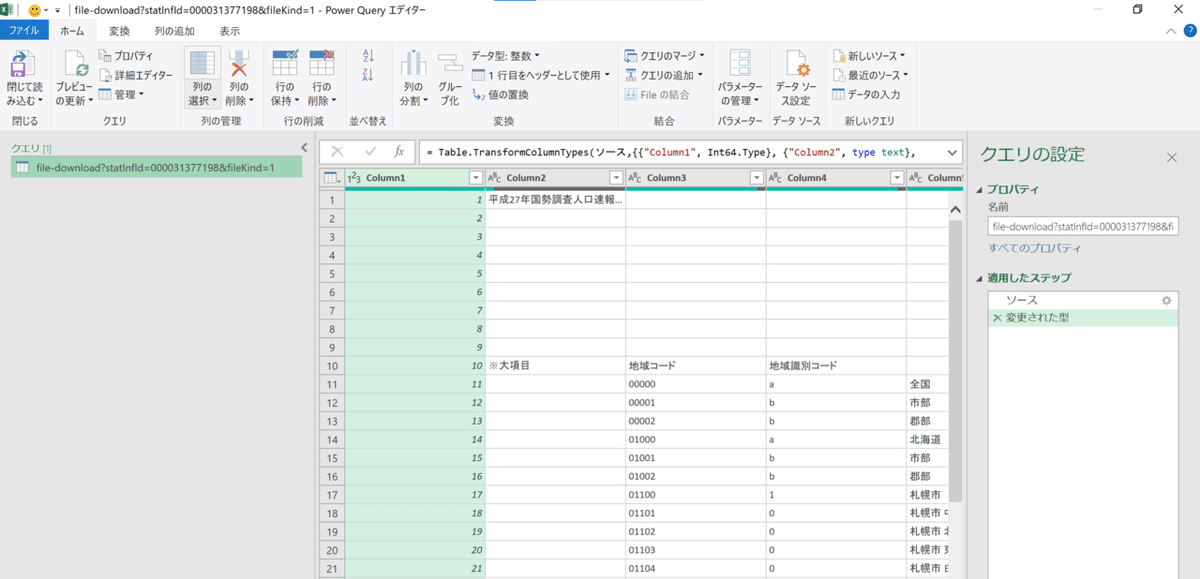
実はこれが、このパワークエリの本来の姿ともいうべき編集画面になります。読み込んだデータテーブルを好きに編集することができる大変優れモノです。
まずは画面の役割を知ろう。
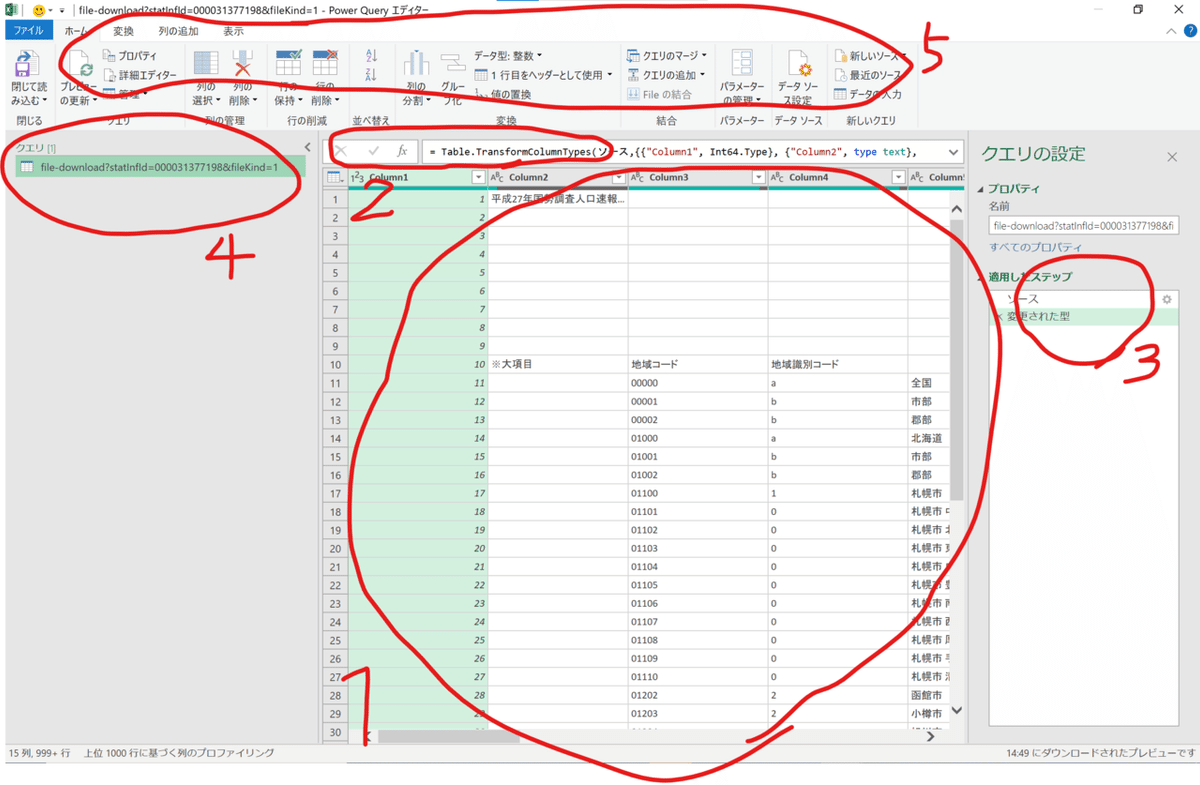
1.この画面は読み込んだデータテーブルのプレビュー画面になります。データテーブルを編集したり、組み合わせたりした操作の結果が表示されます。
2. 「関数式」を書く場所になります。マウス操作でできない作業がある場合に関数を書いてテーブルを編集します。エクセルの関数と同じような役割なのですが、ちょっと難しそうですよね。「当分使わないので大丈夫」です。
3. ここの「適用したステップ」には自身で行った「テーブルを読み込む」、「見出しの名前を変更する」、「列を削除する」などの操作が順番に記録されます。例えばある程度テーブルの編集が終わった際に、「あ、5つ前のステップに戻って見出しの名前を直したい」というような事が可能です。大変便利です。
4.「クエリ」についてのプロパティを見たり名前の編集を行うことが可能です。データテーブルの操作は「クエリ」という単位でまとめられます。一つのレポートにたくさんのデータソースを読み込む場合などに、ここの項目が増えてきます。ちなみに「詳細エディター」は押さない方がよいでしょう。押すとノンプログラミングの制限を超えるのでもう少し慣れて複雑なことをしたくなったら覗いて下さい。
5.ここら辺の表示は「リボン」と呼ばれています。データテーブルに対する編集系の操作がアイコンで並んでいます。
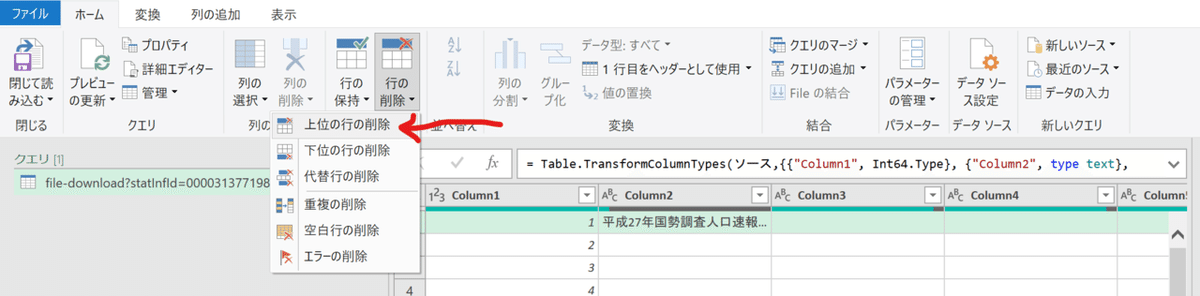
不要な行の削除
実際の整形作業に入ります。まずは上部9行が不要なので削除していきましょう。
↓
↓

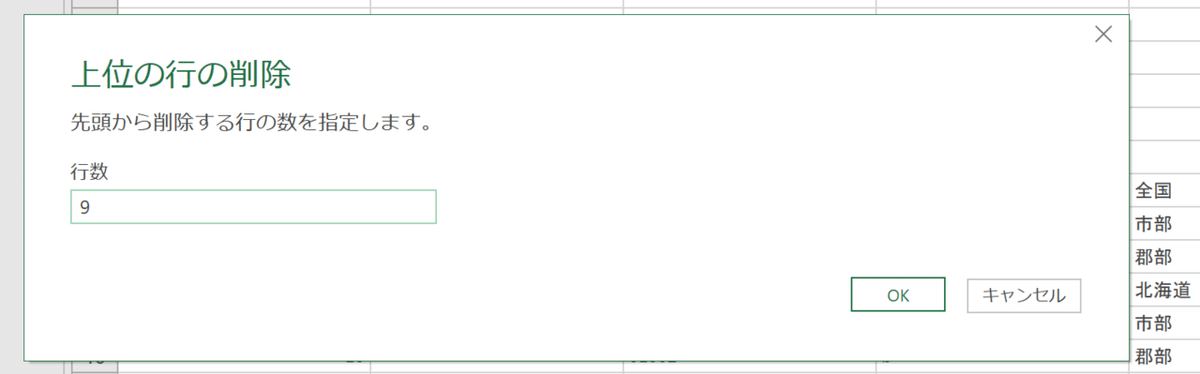
行数を打ち込んでクリックするだけで不要な行を削除できました。昔ながらのCSVにはこのように上部の一定行に実データとは関係ないテキストが含まれていますのでこのように削除しておきましょう。
不要なカラム(列)を削除する
「column1」と書かれた最初のカラム(列)は元のCSVでは行番号を表現していたものなのです。エクセルでは不要なデータになりますので削除します。方法は簡単、「column1」と書いている上で右クリックすると削除メニューが出てきます。リボンからも可能ですので好きな方から操作してください。
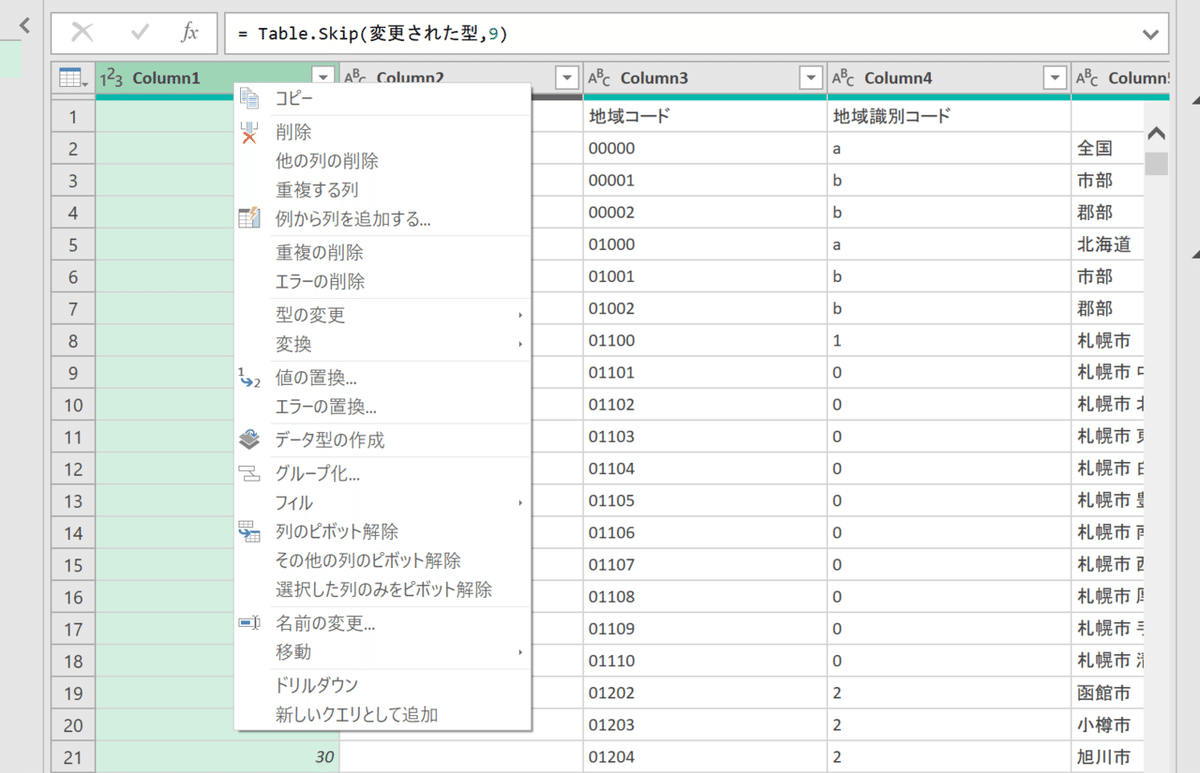
このように数字の「列」が消えて一番左側は「column2」になりましたね。
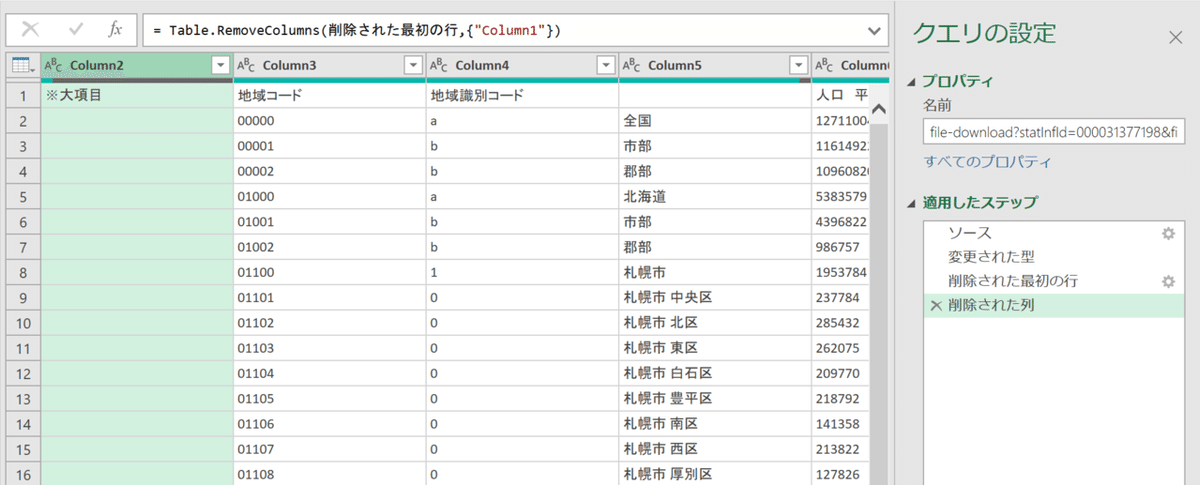
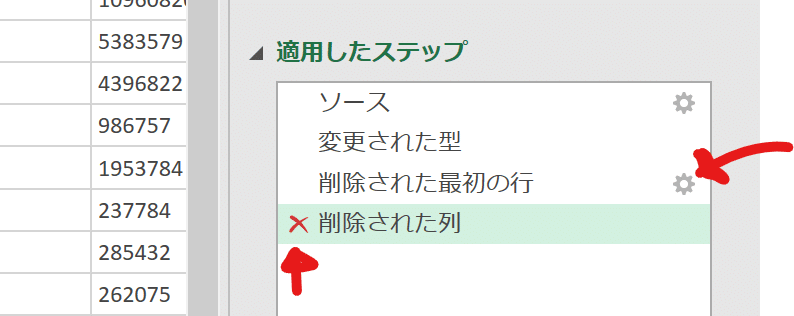
ここで一つ「ステップ」に操作が記録されていること改めて理解しておきましょう。例えば間違えたカラムを削除しても右ステップの「削除された列」の左のバツのアイコンをクリックすれば取り消すことが可能です。ほかにも文字の右端に歯車のマークがあるものはそのステップで操作した設定を修正できますので間違えたときにはここを使いましょう。
見出しを設定する
いつまでもcolumn1~column3のような見出しは、データとして、大変見にくいです。また後々他のデータと結合する際に混乱する原因になります。正しい名前を設定するようにしましょう。今回利用するCSVにはすでに見出しのデータが含まれていましたのでそのデータを見出しとして設定していきます。
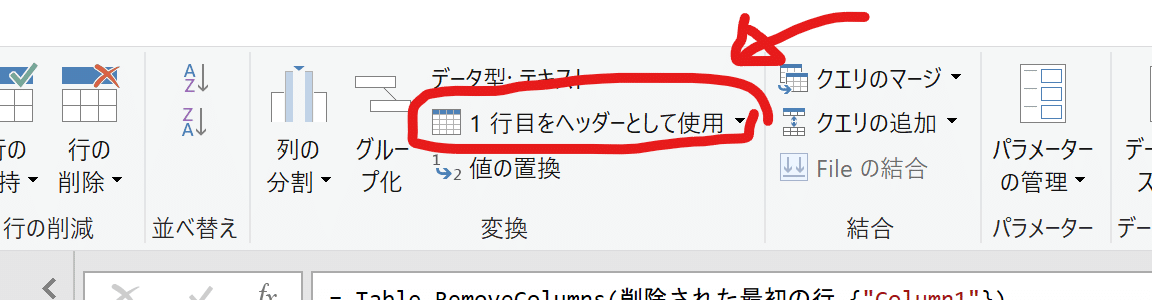
赤枠で囲った部分がまさにやりたいボタンなのポチっとクリックします。
これだけで見事に見出しが置き換えられました。

このデータには見出しが空欄の列がありました。そこには何もテキストが入っていないので、その見出しの上でダブルクリック(または右クリックから名前の変更)を行って自分で名前を付けましょう。
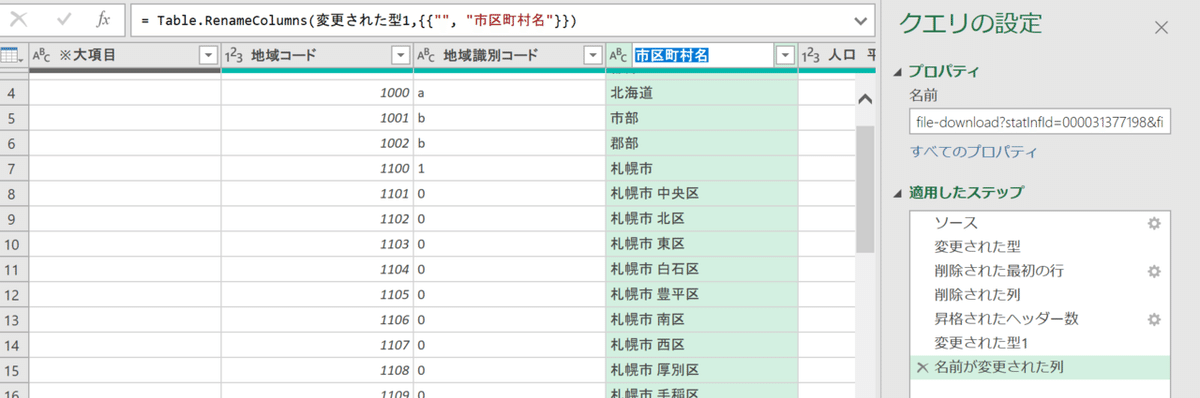
データ型を設定する
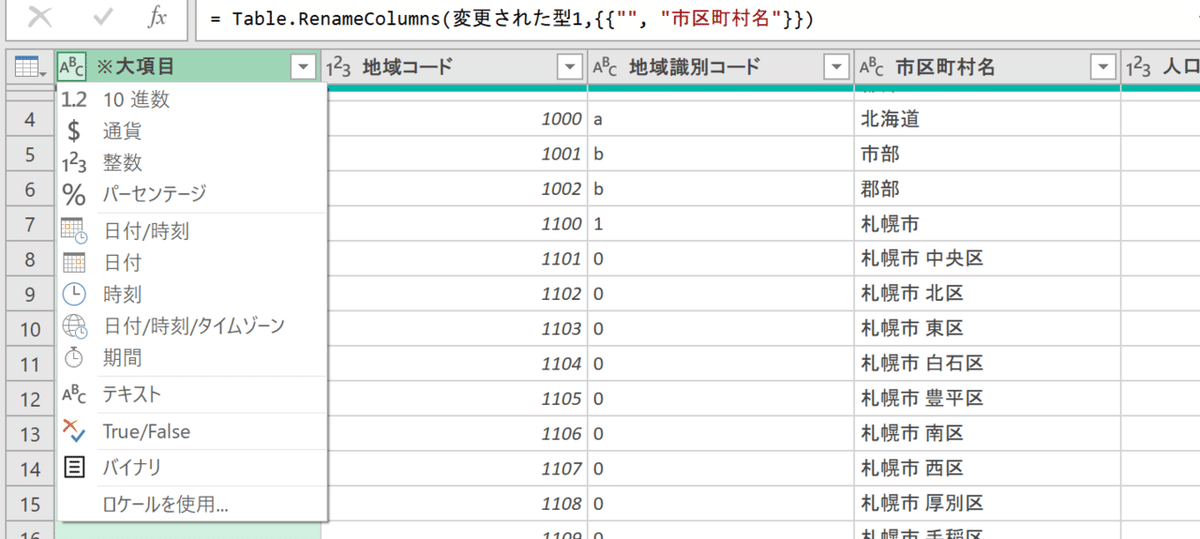
各データの見出しの左に「abc」や「123」などと記述があるのが見えるでしょうか。実はそこでどんな種類のデータかという設定がされています。基本的には自動判別されますが、あまり精度がよろしくないので自分で実際のデータを眺めて正しい値を設定してあげます。
すこし厄介な話ですが、データは見た目は同じでも型が異なっていると違うデータとして判定されます。そのため数字なら数字、テキストならテキスト、時刻なら時刻データであるという設定をしなければいけません。
以下のカラムは率なのでパーセンテージの設定をしてあげましょう。また一番最後の列もパーセンテージに直してあげましょう。
↓
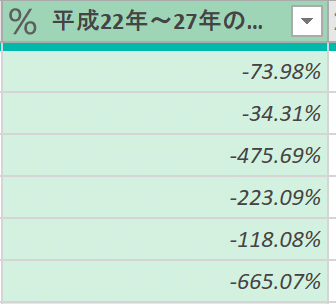
これで一通りデータの整形が完了しました。以下の通り閉じて読み込むを押して完了となります。
エクセルシート側にも無事反映されました。
試しに地域識別コードに「a」を指定、地域コードの「0」を排除したフィルタをかけてデータを絞ってみましょう。
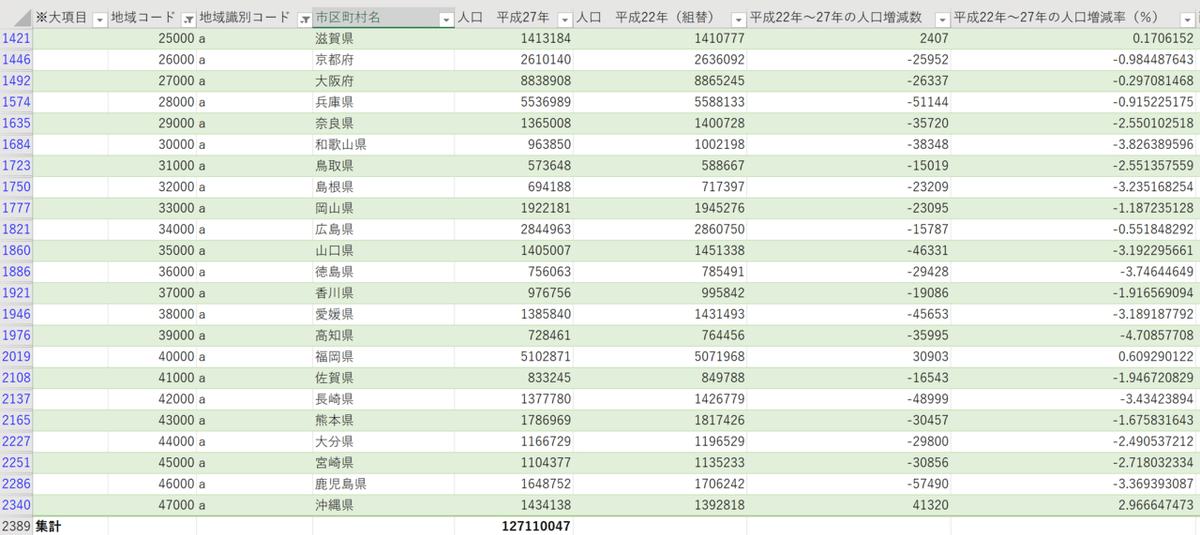
↑のように都道府県別のデータが一目でみられるようになりましたね。またグラフを挿入すれば各都道府県の人口の違いが一目でわかるようになります
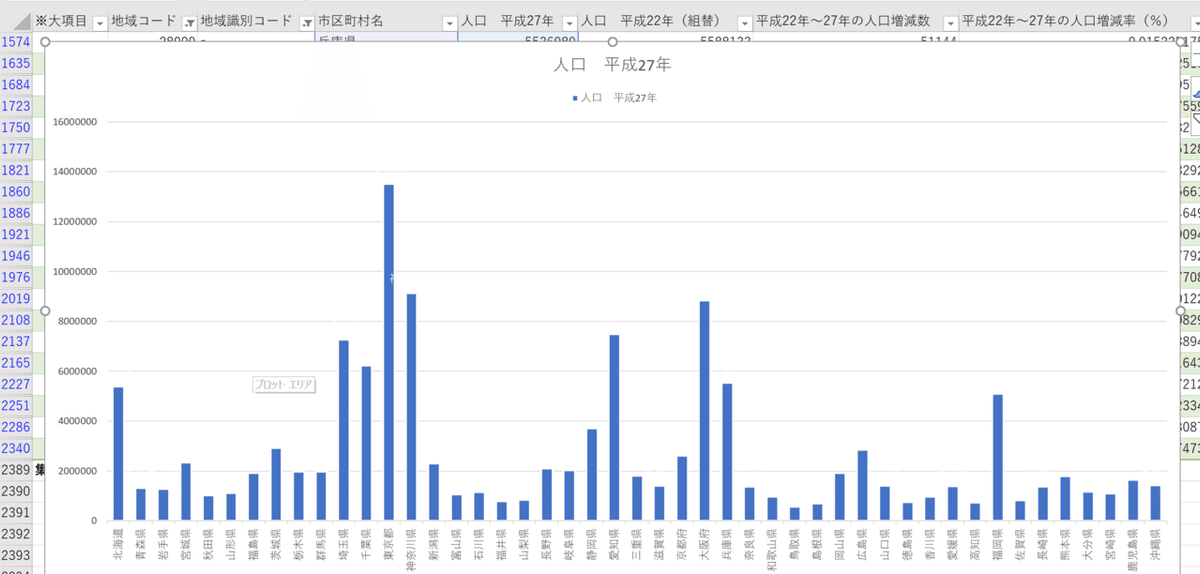
こうすることで必要なデータの収集からビジュアライズまで一貫してエクセルで行うことができるようになりました。
お疲れ様でした。第二回はこれで完了です。
次回は実務レイヤーで良く出会う「分割されたCSV」の読み込みについて解説したいと思います。
参考になった方は「スキ」を押していただけると幸いです。
よろしくお願いいたします。